【問題背景】
最近有一個任務,需要使用python2.7去讀取pdf檔案内容。使用的子產品是pypdf。當我擷取到pdf其中的一頁page時,調用page.mergeScaledTranslatedPage()這個函數處理時,報了下面的錯誤:
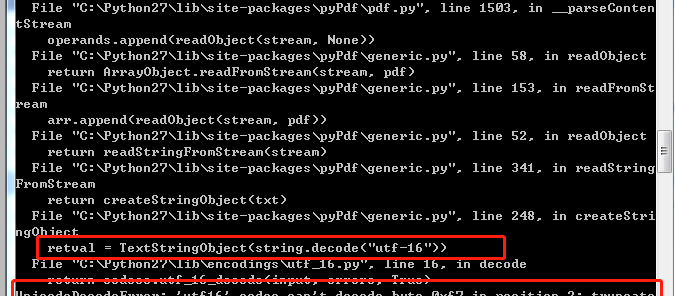
【問題原因】:
這個錯誤是什麼意思呢?咋一看跟解碼和utf16有關。
這個python錯誤的意思是,decode("utf-16") 這個操作,碰到了一個單個位元組的回車(0x0A),utf-16中每個字元應該是2個位元組,如果是UTF-16大端,就是 00 0A,如果是UTF-16 小端(也叫UCS-2小端)的編碼就是0A 00。
這個錯誤就是在UTF-16 小端的情況下,少了後半個字元。即圖中紅色字元所指的位置,有個0A,它後面缺少了00。

【解決辦法】:
解決方法是在decode時,用 decode("utf-16","ignore") 即加上ignore這個選項,把這個錯誤忽略掉。