1. 系統架構
Flink是一個分布式系統,用于有狀态的并行資料流處理。也就是說,Flink會分布式地運作在多個機器上。在分布式系統中,常見的挑戰有:如何對叢集中的資源進行配置設定與管理、協調程序、資料存儲的高可用、以及異常恢複。
Flink自身并未實作這些功能,而僅關注在它自身的核心功能 - 分布式資料流處理。對于分布式叢集的管理,由運作在它之下的叢集完成,并提供基礎設施與服務。Flink與常見叢集資料總管契合度良好,例如Apache Mesos,YARN,以及Kubernetes。當然它也可以配置為stand-alone叢集。Flink并不提供可靠的分布式存儲。它直接使用其他分布式檔案系統如HDFS、S3等。對于在HA設定下的leader選舉,它依賴于ZooKeeper。
在這章我們會介紹Flink的各個元件,以及它們如何互相作用,以運作一個application。我也也會讨論Flink 應用的兩種部署模式,以及它們如何分發、執行任務。最後,介紹在HA模式下Flink如何工作。
Flink元件
在Flink中有四個不同的元件,它們共同協作運作流程式。這些元件為:一個JobManager,一個ResourceManager,一個TaskManager,以及一個Dispatcher。Flink是由Java和Scala實作,是以這些元件全部運作在JVM中。每個元件的職責為:
·JobManager:主(master)程序,用于管理單個application的執行。每個application都由一個不同的JobManager管理。JobManager會接收application并執行。一個application包含:一個JobGraph,一個邏輯資料流圖(logical dataflow graph),以及一個Jar檔案(包含了所有需要的類、lib庫以及其他資源)。JobManager将JobGraph轉化為一個實體資料流圖(physical dataflow graph),稱為ExecutionGraph。ExecutionGraph由一些可以并行執行的任務(tasks)組成。JobManager向ResourceManager申請必須的計算資源(稱為TaskManager slots)用于執行任務。一旦JobManager收到足夠的TaskManager slots,它将ExecutionGraph中的task分發到TaskManager,然後執行。在執行過程中,JobManager負責任何需要中心協調(central coordination)的操作,例如檢查點(checkpoints)的協調
·ResourceManager:Flink 可以整合多個ResourceManager,例如YARN,Mesos,Kubernetes以及standalone 部署。ResourceManager負責管理TaskManager slots,也就是Flink的一個資源處理單元。當JobManager 申請TaskManager slots時,ResourceManager 會配置設定空閑slot給它。如果RM并沒有足夠的slots滿足JobManager的請求,則RM can talk to a resource provider to provision containers in which TaskManager processes are started。RM也負責關閉空閑的TaskManagers,以釋放計算資源。
·TaskManagers:是Flink的worker 程序。一般來說,會有多個TaskManagers運作在一個配置好的Flink 叢集中。每個TaskManager提供了具體數量的 slots。Slots的數量限制了TaskManager可以運作的task數量。在TaskManager啟動後,它會向ResourceManager注冊它的slots。在接受到RM的指令後,TaskManager會向JobManager提供它的slots。JobManager即可配置設定任務到這些slots,并開始執行這些任務。在執行過程中,對于同一個application的不同taks,運作在它們之下的TaskManager 之間會互相交換資料。
·Dispatcher 提供了一個REST 接口,用于送出application執行。當一個application被送出,Dispatcher會啟動一個JobManager并将application交給它。REST接口使得Dispatcher可以作為一個(位于防火牆之後的)HTTP 入口服務提供給外部。Dispathcher也運作了一個web控制台,用于提供job執行的資訊。取決于一個application如何送出執行,dispathcher可能并不是必須的。
下圖展示的是:在送出一個application後,Flink的元件之間如何協作運作此應用:
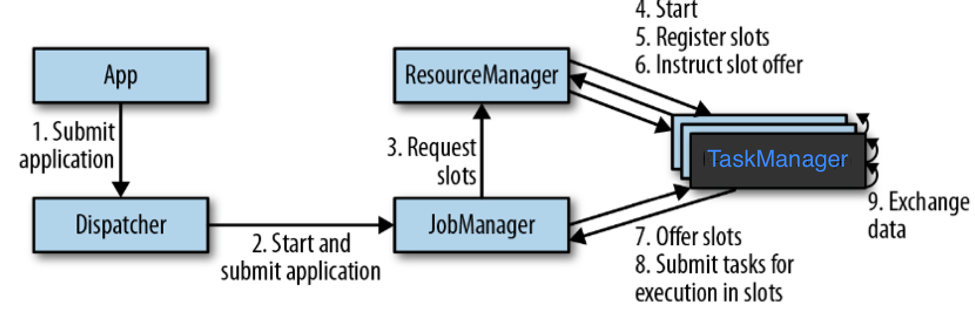
上圖是一個較為High-Level的角度。取決于部署的叢集不同(例如YARN,standalone等),一些步驟可以被省略,亦或是有些元件會運作在同一個JVM程序中。
應用部署
Flink application 可以使用以下兩種不同的方式部署:
1. 架構方式
·在這個模式下,Flink應用被打包成一個Jar檔案,并由用戶端送出到一個運作的服務(running service)。這個服務可以是一個Flink Dispatcher,一個FlinkJobManager,或是Yarn ResourceManager。如果application被送出給一個JobManager,則它會立即開始執行這個application。如果application被送出給了一個Dispatcher,或是Yarn RM,則它會啟動一個JobManager,然後将application交給它,JobManager開始執行此應用。
2. 庫(Library)模式
·在這個模式下,Flink Application 會被打包在一個container 鏡像,例如一個Docker 鏡像。此鏡像包含了運作JobManager和ResourceManager的代碼。當一個容器從鏡像啟動後,它會自動啟動ResourceManager和JobManager,并送出打包好的應用。另一種方法是:将應用打包到鏡像後,用于部署TaskManager容器。從此鏡像啟動的容器會自動啟動一個TaskManager,它會連接配接ResourceManager并注冊它的slots。一般來說,這些鏡像的啟動以及失敗重新開機由一個外部的資料總管管理(如Kubernetes)。
架構模式遵循了傳統的送出任務到叢集的方式。在庫模式下,沒有運作的Flink服務。它是将Flink作為一個庫,與application一同打包到了一個容器鏡像。這個部署模式在微服務架構中較為常見
任務執行
一個TaskManager可以同時執行多個任務。這些task可以是同一個operator(也就是資料并行)的、或是不同的operator(也就是task并行)的,亦或是另一個不同application的(job并行)一組tasks的子集。TaskManager提供了明确個數的processing slots,用于控制可以并行執行的任務數。一個slot可以執行application的一個分片(一個operator的一個并行task)。下圖展示了TaskManager,slots,tasks以及operators之間的關系:

最左邊是一個JobGraph – application的非并行表示,包含了5個operator。A和C是資料源,E是輸出端(sink)。C和E有2個并行,其他的有4個并行。因為最高的并行度是4,是以應用需要至少四個slot執行任務。給定兩個TaskManager,每個各有兩個slot,這種情況下需求是滿足的。JobManager将JobGraph轉化為ExecutionGraph,并将任務配置設定到四個可用的slot上。對于有4個并行任務的operator,它的task會配置設定到每個slot上。對于有2個并行任務的operator C和E,它們的任務被配置設定到slot 1.1、2.1 以及 slot 1.2、2.2。将tasks排程到slots上,可以讓多個tasks跑在同一個TaskManager内,也就可以是的tasks之間的資料交換更高效。然而将太多任務排程到同一個TaskManager上會導緻TaskManager過載,繼而影響效率。之後我們會讨論如何控制任務的排程。
TaskManager在同一個JVM中以多線程的方式執行任務。線程較程序會更輕量級,但是線程之間并沒有非常嚴格的将任務互相隔離。是以,單個誤操作的任務可能會kill掉整個TaskManager程序,以及運作在此程序上的所有任務。通過為每個TaskManager配置單獨的slot,可以将application互相隔離。依賴于TaskManager内部的多線程,以及在一台執行個體上配置部署多個TaskManager,Flink可以為性能與資源隔離提供更靈活的權衡。
高可用設定
流應用一般設計為7 x 24 小時運作。是以很重要的一點是:即使在出現了程序挂掉的情況,應用仍需要繼續保持執行。為了從故障恢複,系統需要重新開機程序、重新開機應用并恢複它的狀态。接下來我們會介紹Flink如何重新開機失敗的程序。
1. TaskManager 失敗
正如前文提到,Flink需要足夠數目的slot,以執行一個應用的所有任務。假設一個Flink配置有4個TaskManager,每個TM提供2個slot,則一個流程式最高可以以8個并行機關執行。如果其中一個TaskManager失敗,可用的slots會降到6。在這種情況下,JobManager會要求ResourceManager提供更多的slots。如果此要求無法完成 - 例如應用跑在一個standalone叢集 – JobManager在有足夠的slots之前,無法重新開機此application。應用的重新開機邏輯決定了JobManager的重新開機頻率,以及兩次嘗試之間的時間間隔。
2. JobManager失敗
比TaskManager失敗更嚴重的問題是JobManager失敗。JM控制整個流應用的執行,并維護執行中的中繼資料,例如指向已完成的檢查點的指針。若是對應的JobManager消失,則流程式無法繼續運作。也就是說JobManager在Flink應用中是單點故障。為了克服這個問題,Flink支援高可用模式,在源JM消失後,可以将一個job的狀态與中繼資料遷移到另一個JobManager,并繼續執行。
Flink的高可用模式基于ZooKeeper。若是在HA模式下運作,則JobManager将JobGraph以及所有必須的metadata(例如應用的jar檔案)寫入到一個遠端持久性存儲系統中。此外,JM會寫一個指針資訊(指向存儲位置)到Zookeeper的資料存儲中。在執行一個application的過程中,JM接收每個獨立task檢查點的state句柄(也就是存儲位置)。根據一個檢查點的完成情況(當所有任務已經成功地将它們的state寫入到遠端存儲), JobManager寫入state句柄到遠端存儲,以及寫入指針(指向遠端存儲的指針)到ZooKeeper。是以,所有需要(在一個JM失敗後)被還原的資訊被存儲在遠端存儲,而ZooKeeper持有指向此存儲位置的指針。下圖描述了此設計:
當一個JM失敗,所有屬于這個application的任務會自動取消。一個新的JM接管失敗JM的工作,并執行以下操作:
1.從ZooKeeper請求存儲位置(storage location),從遠端存儲擷取JobGraph,Jar檔案,以及application上次checkpoint的狀态句柄(state handles)
2.從ResourceManager請求slots,以繼續執行application
3.重新開機application并重制它所有的tasks到上一個完成了的checkpoint
當一個application是以庫部署的形式運作(如Kubernetes),失敗的JobManager或TaskManager 容器會由容器服務自動重新開機。當運作在YARN或Mesos之上時,JobManager或TaskManager程序會由Flink自動觸發重新開機。在standalone模式下,Flink并未提供為失敗程序重新開機的工具。是以次模式下可以運作一個standby JM和TM,用于接管失敗的程序。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019