本文以 PyTorch on Horovod 為切入點,分析一下 Horovod 彈性訓練的恢複流程,具體涉及知識點有:ElasticSampler與PyTorch 原生DistributedSampler 的差別,Horovod 彈性訓練如何恢複等。
目錄
[源碼解析] 深度學習分布式訓練架構 horovod (21) --- 之如何恢複訓練
0x00 摘要
0x01 總論
0x02 Sampler
2.1 PyTorch Distributed Optimizer
2.1.1 定義
2.1.2 問題點
2.2 ElasticSampler
2.2.1 定義
2.2.2 彈性方案
2.2.2.1 正常流程
2.2.2.2 異常處理
2.2.1 如何使用
2.2.1.1 主體代碼
2.2.1.2 訓練代碼
0x03 儲存和定期檢查
3.1 定期儲存
3.2 異常處理
3.3 Commit
0x04 State
4.1 恢複訓練
4.2 TorchState
4.3 設定 handler
4.4 SamplerStateHandler
4.5 儲存
4.6 HostsUpdatedInterrupt
4.7 HorovodInternalError
4.8 ElasticSampler.iter
0xFF 參考
本文以 PyTorch on Horovod 為切入點,分析一下 Horovod 彈性訓練的恢複流程,具體涉及知識點有:
ElasticSampler與PyTorch 原生DistributedSampler 的差別,Horovod 彈性訓練如何恢複等。
本系列其他文章連結如下:
[源碼解析] 深度學習分布式訓練架構 Horovod (1) --- 基礎知識
[源碼解析] 深度學習分布式訓練架構 horovod (2) --- 從使用者角度切入
[源碼解析] 深度學習分布式訓練架構 horovod (3) --- Horovodrun背後做了什麼
[源碼解析] 深度學習分布式訓練架構 horovod (4) --- 網絡基礎 & Driver
[源碼解析] 深度學習分布式訓練架構 horovod (5) --- 融合架構
[源碼解析] 深度學習分布式訓練架構 horovod (6) --- 背景線程架構
[源碼解析] 深度學習分布式訓練架構 horovod (7) --- DistributedOptimizer
[源碼解析] 深度學習分布式訓練架構 horovod (8) --- on spark
[源碼解析] 深度學習分布式訓練架構 horovod (9) --- 啟動 on spark
[源碼解析] 深度學習分布式訓練架構 horovod (10) --- run on spark
[源碼解析] 深度學習分布式訓練架構 horovod (11) --- on spark --- GLOO 方案
[源碼解析] 深度學習分布式訓練架構 horovod (12) --- 彈性訓練總體架構
[源碼解析] 深度學習分布式訓練架構 horovod (13) --- 彈性訓練之 Driver
[源碼解析] 深度學習分布式訓練架構 horovod (14) --- 彈性訓練發現節點 & State
[源碼解析] 深度學習分布式訓練架構 horovod (15) --- 廣播 & 通知
[源碼解析] 深度學習分布式訓練架構 horovod (16) --- 彈性訓練之Worker生命周期
[源碼解析] 深度學習分布式訓練架構 horovod (17) --- 彈性訓練之容錯
[源碼解析] 深度學習分布式訓練架構 horovod (18) --- kubeflow tf-operator
[源碼解析] 深度學習分布式訓練架構 horovod (19) --- kubeflow MPI-operator
[源碼解析] 深度學習分布式訓練架構 horovod (20) --- Elastic Training Operator
本文緣起于一個兄弟的留言:
請問在彈性訓練中,如果節點數目發生變化,資料怎麼重新劃分呢?比如一個epoch還沒有進行完,這時添加了新節點,新資料重新劃分的話,目前記憶體中用舊資料訓練的模型還有效嗎?
我恰好在分析PyTorch分布式的時候也有類似疑問,是以就回頭再看看Horovod是如何實作的。
我們之前對于 Horovod 的分析和示例大多以 TensorFlow 為例。大家對各種架構如何在Horovod之中适配的總體邏輯和思路應該有了一個大緻的認識,是以我們本部分主要看看一些PyTorch 相關的特殊之處。
使用PyTorch做切入的另外一個原因是:在恢複訓練這個流程上,PyTorch相關部分确實相對清晰明确。
在 horovod/torch/elastic/ 目錄下,有兩個檔案 :state.py 和 sampler.py。既然是彈性相關,是以我們先來看看其特殊之處。
在 horovod/torch/elastic/sampler.py 之中,有一個 ElasticSampler 類,我們看看具體針對彈性做了哪些處理。
因為 ElasticSampler 類之中注明,它的實作非常類似<code>DistributedSampler</code>,也就是 PyTorch 原生的實作,是以我們要先看看 <code>DistributedSampler</code>。
<code>DistributedSampler</code>代碼位于:torch/distributed/optim/optimizer.py。
總結一下DistributedSampler的配置設定方法是:每段連續的 <code>num_replicas</code> 個資料被拆成一個一個,分給 <code>num_replicas</code> 個程序,這樣就達到了不重疊不交叉的目的,但也要注意的是:這樣每個程序拿到的資料是不連續的。
<code>__iter__</code> 代碼的一個技術細節是 本worker如何周遊?
<code>indices = indices[self.rank:self.total_size:self.num_replicas]</code>
這裡,num_replicas 實際就是rank的總數,起始位置是self.rank,結束位置是總資料長度,按照num_replicas(就是world size)作為步長來遞增,是以這裡每個worker就會嚴格傳回自己rank對應的那部分資料序号。
我們用一個例子來看看,比如:
得到:
具體代碼如下:
DistributedSampler 如果直接用到 彈性訓練,是有一定問題的,讓我們分析一下,有幾個問題:
如果使用者已經訓練了5輪,那麼就意味着已經使用了前面5個批次的資料。假設此時加入了新的worker節點,那麼就應該恢複訓練。那麼對于已經使用過的前面 5 個批次的資料,按說就不應該再次被用來訓練了。
問題1: 恢複訓練之後,應該怎麼去除已經處理的資料index?
如果加入或者減少節點,如果告訴 Sampler,我們需要更改提取規則,最起碼,num_replicas 需要被更新,以後按照新的 num_replicas 進行提取,比如原來5個節點,num_replicas = 5,現在6個節點,num_replicas 應該為 6。
問題2: 恢複訓練之後,何時調用 <code>__iter__</code>以進行新的訓練?
問題3: 恢複訓練之後,何時修改 num_replicas?
我們看看 DistributedSampler 就會發現,其<code>__iter__</code>之中,沒有任何儲存狀态的相關資訊。即如果重新開始訓練,依然會從全體資料中提取,而非從剩餘資料中提取。也沒有發現對後面兩個問題的解決辦法。
是以,很難利用 DistributedSampler進行彈性訓練,是以 Horovod 就使用 ElasticSampler 來解決這個問題。
從注釋中我們可以看到,ElasticSampler 自稱與 DistributedSampler 非常類似。我們随後針對兩個類代碼比較可以看到,功能基本一緻。
但是有兩個新加入的變量值得注意,即:
定義如下:
具體彈性方案就圍繞之前提到的兩個變量來進行。
我們回憶其注釋中提到的如何使用:
我們可以推導出來其内在邏輯:
進行本 epoch 訓練。
當使用 <code>__iter__</code> 擷取下一批次資料時候,<code>self.indices = self.remaining_indices[:]</code> 就會 隻從未訓練的資料裡面提取。
每處理一個批次資料 之後,使用者使用 <code>record_batch</code> 或者 <code>record_indices</code> 來把已經訓練完的資料批次資訊儲存在 <code>processed_indices</code>。這樣就記錄了已經訓練完的資料。
如果産生了問題,或者有節點變更,則:
會調用 reset 函數,reset 會把已經訓練完的資料 <code>processed_indices</code> 從總資料中移除,剩下的 <code>self.remaining_indice</code>就是沒有訓練的資料。
恢複訓練, 隻從未訓練的資料裡面提取。
當完成這個epoch 之後,會調用 <code>set_epoch</code> 來重置 <code>processed_indices</code>,也會調用 reset 方法進行清零。
具體功能代碼是:
在 horovod/torch/elastic/state.py 之中,當重新訓練時候,會調用到 ElasticSampler 的 load_state_dict 方法。
而 load_state_dict 之中,會調用 reset,這樣就把已經訓練完的資料移除,得到的資料都是沒有經過訓練的。
是以重新訓練時候,本epoch之内,不會用已經訓練的資料再次重複訓練。
我們後續會詳細分析這個流程。
ElasticSampler 的使用如下,代碼位于:examples/elastic/pytorch/pytorch_imagenet_resnet50_elastic.py。
本節我們主要介紹如何使用,就是正常使用/處理流程,後續會介紹異常處理,這裡省略部分次要代碼。
主體代碼主要注意就是使用ElasticSampler分别配置了兩個彈性采樣器。
以下代碼是具體訓練代碼。
某一個epoch具體邏輯(正常處理)如下:
如果是最初運作,則調用reset進行初始化,其中會依據 dataset 長度建構一個 index list。用這個index list 減去 processed_indices ,就得到了本次epoch應該處理的資料 index,指派給 remaining_indices,就是剩下來應該處理的資料index;
在 <code>__iter__</code> 函數中,調用 <code>self.indices = self.remaining_indices[:]</code> ,這樣 indices 就可以用來做疊代提取;
訓練函數中,調用 iter(indices) 進行疊代提取,然後調用 record_indices 把本次使用過的index 更新到 processed_indices 之中。processed_indices 就記錄了目前使用的所有index;
epoch 結束之後,調用 set_epoch 進行重置,即給 processed_indices 清零,調用 reset 重置 remaining_indices;
Hovorod 建議使用者定周期性調用 state.commit() 來把狀态(state)備份到記憶體。
定期備份非常有用。在某些worker發生意外錯誤時,定期備份可以避免因為狀态被損壞而在重新訓練時候無法恢複現場。比如,如果一個worker剛好在更新參數過程中突然出錯,此時部分梯度更新完畢,部分梯度可能隻更新到一半,這個狀态是不可逆轉而又無法繼續。是以,當此狀态發生時,會抛出一個 HorovodInternalError 異常,當 hvd.elastic.run 捕獲到這個異常後,會利用最新一次commit中恢複所有狀态。
因為commit狀态代價高昂(比如如參數量太大會導緻耗時過長),是以需要在"每個batch的處理時間"與"如果出錯,訓練需要從多久前的狀态恢複"之間選取一個平衡點。比如,如果你每訓練10個batches就commit一次,你就把複制時間降低了10倍。但是當發生錯誤時,你需要復原到10個batches前的狀态。
Elastic Horowod可以通過執行我們稱之為“優雅地移除worker”操作來避免這些復原。如果driver程序發現主機已可用或标記為删除,它将向所有workers推送一個通知。于是在下次調用state.commit()或更輕量級的state.check_host_updates()時,一個HostsUpdatedInterrupt異常将被抛出。此異常的處理方式與“HorovodInternalError”類似,隻是參數狀态不會還原到上次commit,而是從目前實時參數中恢複。
一般來說,如果你的硬體設施是可靠與穩定的,并且你的編排系統會在任務節點移除時提供足夠的告警,你就可低頻次調用 state.commit() 函數,同時隻在每個batch結束時調用相對不耗時的 state.check_host_updates() 來檢查節點變更情況。
具體示例代碼如下:
我們可以看到,HorovodInternalError 和 HostsUpdatedInterrupt 這兩個異常最大的差別:
HorovodInternalError 異常:當 hvd.elastic.run 捕獲到這個異常後,會利用最新一次commit中恢複所有狀态。
HostsUpdatedInterrupt 異常:處理方式與“HorovodInternalError”類似,隻是參數狀态不會還原到上次commit,而是從目前實時參數中恢複。
之是以要強調這個,因為後面就要介紹如何做到不同恢複。
在使用者調用 State.commit 的時候,有兩個動作:一個是儲存狀态。一個是調用 check_host_updates 檢查更新。
這裡 save 就會調用到 State 的 save 操作,結合本文,就是下面要介紹的 TorchState 的 save 操作。
另外,check_host_updates 會抛出HostsUpdatedInterrupt異常。HostsUpdatedInterrupt 異常裡面,是否需要 sync,從下面 check_host_updates 代碼可以看出來,就是如果節點數目有變化了,就需要sync。HostUpdateResult.removed 數值為1,這裡其實可以改進,HostUpdateResult.removed 在目前這個情況之下,設定過細了。
我們接下來介紹異常處理邏輯,具體圍繞着 State 來介紹。對于State,我們先回憶一下其在恢複訓練時候的邏輯。
重新訓練時候,會抛出兩種異常:
如果是 ring allreduce 相關,就轉為抛出異常 HorovodInternalError(e)。
如果當驅動程序通過節點發現腳本發現一個節點被标記為新增或者移除時,會抛出異常 HostsUpdatedInterrupt。
然後會進行如下處理:
邏輯如下:
因為這裡涉及了大量的state操作,是以我們接下來要看看 TorchState:
首先,我們要看看 TorchState 如何使用。當調用時候,使用如下方法來生成一個TorchState:
其次,我們看看 TorchState 的定義,這裡的 sync,restore,reset方法就在恢複訓練中被調用。
在初始化函數 <code>__init__</code> 之中,會設定 handler,以我們的調用為例,就是 train_sampler,val_sampler這兩個對應的sampler會配置對應的handler,即SamplerStateHandler。
TorchState 繼承了 ObjectState,ObjectState 繼承了 State,是以前面提到的 commit 代碼中的 self.save(),就會調用到TorchState.save,而這裡又會調用到 SamplerStateHandler.save。
基類代碼中有:
上節中,我們可以看到,無論是reset,還是restore,都會調用到 _handlers 來進行處理,是以我們需要進一步分析。
首先就是如何設定handler。具體參見如下代碼,主要是通過一個全局配置 _handler_registry 來指定哪個 handler 處理哪種類型執行個體,比如這裡有 <code>(ElasticSampler, SamplerStateHandler)</code>,就代表着 SamplerStateHandler 是用來處理 ElasticSampler的 handler。
既然知道了 ElasticSampler 由 SamplerStaeHandler 處理,就來分析一下 SamplerStateHandler。
初始化之後,self.value 就是 sampler,針對我們之前的分析,就是ElasticSampler。
SamplerStateHandler 具體代碼是,這裡需要注意的是:初始化時候,會把ElasticSampler的狀态儲存起來,以後如果出錯,會用此來恢複。
同時,save 也會被調用,用來恢複,我們馬上就會分析。
SamplerStateHandler 的 基類是:
我們拓展一下save相關操作序列。
TorchState 繼承了 ObjectState,ObjectState 繼承了 State,是以:
前面提到的 commit 代碼中的 self.save(),就會調用到TorchState.save。
而TorchState.save又會調用到 SamplerStateHandler.save。
SamplerStateHandler.save 會儲存 ElasticSampler 的屬性和資料,就是儲存了 ElasticSampler 的 epoch 和 processed_indices。
這樣,在定期 commit 的時候,就定期儲存了模型的狀态和 ElasticSampler 的狀态,這些會在恢複訓練中用到。具體下圖所示:
隻看靜态定義,還是很難了解,需要分析動态流程。因為有兩種異常,是以我們分開剖析。
回憶一下兩個異常最大的差別:
如果當驅動程序通過節點發現腳本發現一個節點被标記為新增或者移除時,會抛出異常 HostsUpdatedInterrupt。此時不是關鍵異常,是以可以繼續訓練本epoch,隻是從後續訓練資料中,移除本epoch已經處理的資料。是以可以做到 參數狀态不會還原到上次commit,而是從目前實時參數中恢複。
下面代碼之中,我們隻保留 HostsUpdatedInterrupt 相關代碼。
發生異常之後,
1)HostsUpdatedInterrupt 表示本 epoch 需要繼續訓練,是以進行異常處理,其中隻是會:
1.1) 記錄本異常處理是否需要同步 :skip_sync = e.skip_sync。
2)這個步驟主要是重新開機 hvd,對worker數目進行更改。具體是調用 State 自身的 reset() 方法(代碼位于<code>horovod/torch/elastic/__init__.py</code>),其中會:
2.1) 調用 shutdown() 來結束本次任務。
2.2) 調用 init(),進而調用_basics.init,最終重建立立 MPI 相關 context,是以 hvd.size() 就根據最新的worker數目進行了更改。後續 <code>ElasticSampler.__iter__</code> 之中會相應修改num_replicas。
3)這個步驟是把已經訓練完的資料移除,得到的資料都是沒有經過訓練的。如果需要同步,則會調用 state.sync() ,其會調用 SamplerStateHandler.sync 方法,其内部會:
3.1) SamplerStateHandler會利用集合通信從所有worker中收集processed_indices,賦予給 world_processed_indices,這就是所有workers 已經處理過的資料 index。
3.2) 調用 ElasticSampler.state_dict方法,得到本地 ElasticSampler.epoch 和 ElasticSampler.processed_indices 的引用。然後将 world_processed_indices 指派給 state_dict['processed_indices'],這樣,本地 ElasticSampler.processed_indices 就是所有workers 已經處理過的資料 index。
3.3) <code>self.value.load_state_dict(broadcast_object(state_dict))</code> 有兩步操作:
廣播,這樣在同步之後,所有worker都有同樣的 state_dict['processed_indices'] 資料了。
load_state_dict 會再調用一次 ElasticSampler.reset,此次 reset 會更改 <code>num_replicas</code>,也會從總資料中去除<code>processed_indices</code>,得到新的 <code>remaining_indices</code>, 進而 後續 <code>__iter__</code> 之中,就會相應對提取index 的政策進行相應更改。
4)是以這樣就把已經訓練完的資料移除,是以得到的 remaining_indices 資料都是沒有經過訓練的。是以重新訓練時候,本epoch之内,不會用已經訓練的資料再次重複訓練,而是從目前實時參數中恢複。
重新訓練會調用 return func(state, *args, **kwargs) 進行訓練,這裡會處理 <code>ElasticSampler.__iter__</code> 。
具體邏輯如下:
手機如下:
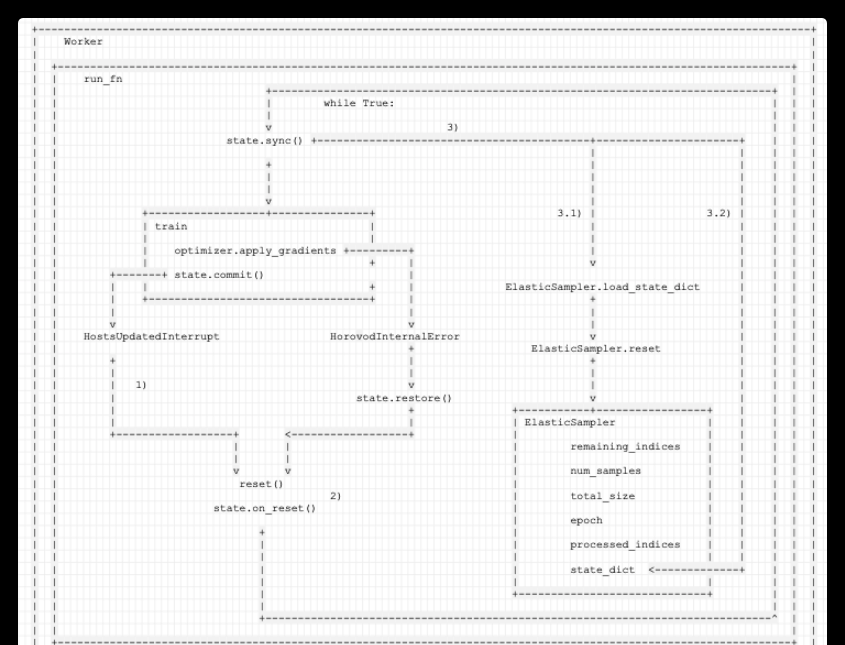
如果是 ring allreduce 相關,就轉為抛出異常 HorovodInternalError(e)。HorovodInternalError 是關鍵異常,此時本 epoch 現有狀态其實意義不大,應該利用最新一次commit中恢複所有狀态。
下面代碼之中,我們隻保留 HorovodInternalError 相關代碼。
HorovodInternalError 和 HostsUpdatedInterrupt 的代碼路徑幾乎一樣,隻是多了一步 state.restore() 。
這裡為啥也要走檢視節點變化這個代碼路徑呢?因為Horovod是定期檢查節點變化,是以可能産生HorovodInternalError時候,也有節點變化了,隻是還沒有發現而已,是以可以一并處理了。
具體邏輯為:
1)HorovodInternalError 表示本 epoch 需要恢複訓練,是以先進行異常處理:
1.1)state.restore() 會調用 SamplerStateHandler.restore(這裡是與HostsUpdatedInterrupt處理差異之處)。
進而調用 ElasticSampler.load_state_dict方法,會用在<code>SamplerStateHandler.__init__</code> 或者<code>SamplerStateHandler.save</code> 之中原始儲存的資料來恢複 ElasticSampler。儲存的資料就是 processed_indices 和 epoch。
ElasticSampler.load_state_dict方法 進而會調用 ElasticSampler.reset方法,使用 processed_indices 把已經訓練完的資料移除,最新得到的 remaining_indices 資料都是沒有經過訓練的(針對上次儲存的 processed_indices 來說)。
1.2) 記錄本異常處理需要同步 : skip_sync = False。
2)這個步驟主要是重新開機 hvd。調用 State 自身的 reset() 方法(代碼位于<code>horovod/torch/elastic/__init__.py</code>),其中會:
2.2) 調用 init(),進而調用_basics.init,最終重建立立 MPI 相關 context。
3)這個步驟是把已經訓練完的資料移除,得到的資料都是沒有經過訓練的。因為這裡需要同步,是以會調用 state.sync() ,其會調用 SamplerStateHandler.sync 方法,其内部會:
3.1) SamplerStateHandler會利用集合通信從所有worker中收集processed_indices,賦予給 world_processed_indices,這就是所有workers 已經處理過的資料 index。需要注意的是:因為是使用在<code>__init__</code> 或者 <code>save</code>之中原始儲存的資料來恢複,是以其實這一步是恢複到上次commit狀态。
3.3) 這裡 <code>self.value.load_state_dict(broadcast_object(state_dict))</code> 有兩步操作:
4)這樣就是恢複到epoch 上次 commit 的狀态進行訓練。
具體邏輯如下圖:

到目前為止,我們還有一個問題沒有仔細分析,就是何時調用 <code>ElasticSampler.__iter__</code>
我們仔細梳理一下:
以下是彈性訓練總體邏輯:
彈性邏輯使用注解來封裝了full_train,是以 func 就是 full_train。
我們看看 train 的主要代碼:
是以我們可以理出來總體邏輯:
當出錯恢複時候,train 會再次被調用,調用時候就會使用 enumerate(train_loader)調用到 <code>ElasticSampler.__iter__</code>。
num_replicas 在之前 reset 時候已經被設定,是以此時就是根據新的 world size 和 remaining_indices 重新确定提取資料的政策。
具體邏輯如下,其中
1)在 reset 之中設定了num_replicas。
2)在 <code>ElasticSampler.__iter__</code> 之中根據新的 world size 和 remaining_indices 重新确定提取資料的政策。
至此,彈性訓練如何恢複就分析完畢,以後可能結合 Pytorch 分布式 optimizer 來繼續分析。
PyTorch 中文手冊(2)-自動求導
pytorch中優化器optimizer.param_groups
PyTorch學習筆記6--案例2:PyTorch神經網絡(MNIST CNN)
https://github.com/chenyuntc/pytorch-book