第一部分 Spark Core
從狹義的角度上看:Hadoop是一個分布式架構,由存儲、資源排程、計算三部分組 成; Spark是一個分布式計算引擎,由 Scala 語言編寫的計算架構,基于記憶體的快速、通 用、可擴充的大資料分析引擎; 從廣義的角度上看,Spark是Hadoop生态中不可或缺的一部分;
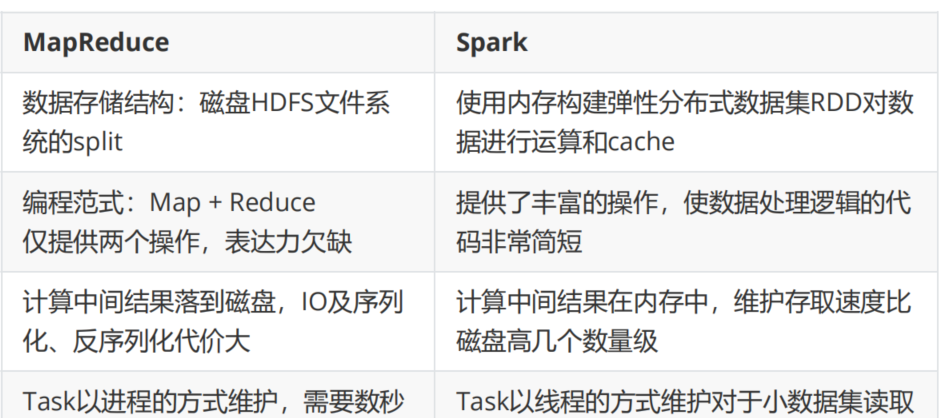
Spark在借鑒MapReduce優點的同時,很好地解決了MapReduce所面臨的問題。
備注:Spark的計算模式也屬于MapReduce;Spark架構是對MR架構的優化 ;
在實際應用中,大資料應用主要包括以下三種類型:
批量處理(離線處理):通常時間跨度在數十分鐘到數小時之間
互動式查詢:通常時間跨度在數十秒到數分鐘之間
流處理(實時處理):通常時間跨度在數百毫秒到數秒之間
當同時存在以上三種場景時,傳統的Hadoop架構需要同時部署三種不同的軟體。 如:
MapReduce / Hive 或 Impala / Storm
這樣做難免會帶來一些問題:
不同場景之間輸入輸出資料無法做到無縫共享,通常需要進行資料格式的轉換
不同的軟體需要不同的開發和維護團隊,帶來了較高的使用成本
比較難以對同一個叢集中的各個系統進行統一的資源協調和配置設定
Spark所提供的生态系統足以應對上述三種場景,即同時支援批處理、互動式查詢和 流資料處理:
Spark的設計遵循“一個軟體棧滿足不同應用場景”的理念(all in one),逐漸形成了一套完整的生态系統
夠提供記憶體計算架構,也可以支援SQL即席查詢、實時流式計算、機器學習 和圖計算等
Spark 在資料總管YARN之上,提供一站式的大資料解決方案
Spark 為什麼比 MapReduce 快: 1 Spark積極使用記憶體。MR架構中一個Job 隻能擁有一個 map task 和一個 reduce task。如果業務處理邏輯複雜,一個map和一個reduce是表達不出來的,這時就需 要将多個 job 組合起來;然而前一個job的計算結果必須寫到HDFS,才能交給後一個 job。這樣一個複雜的運算,在MR架構中會發生很多次寫入、讀取操作操作;Spark 架構則可以把多個map reduce task組合在一起連續執行,中間的計算結果不需要落 地; 複雜的MR任務:mr + mr + mr + mr +mr ... 複雜的Spark任務:mr -> mr -> mr ......
2、多程序模型(MR) vs 多線程模型(Spark)。MR架構中的的Map Task和Reduce Task是程序級别的,而Spark Task是基于線程模型的。MR架構中的 map task、 reduce task都是 jvm 程序,每次啟動都需要重新申請資源,消耗了不必要的時間。 Spark則是通過複用線程池中的線程來減少啟動、關閉task所需要的系統開銷。
Spark運作架構包括:
Cluster Manager
Worker Node
Driver
Executor
Cluster Manager 是叢集資源的管理者。Spark支援3種叢集部署模式:
Standalone、Yarn、Mesos;
Worker Node 工作節點,管理本地資源;
Driver Program。運作應用的 main() 方法并且建立了 SparkContext。由Cluster Manager配置設定資源,SparkContext 發送 Task 到 Executor 上執行;
Executor:在工作節點上運作,執行 Driver 發送的 Task,并向 Dirver 彙報計算結果;
Spark支援3種叢集部署模式:Standalone、Yarn、Mesos;
1、Standalone模式 *獨立模式,自帶完整的服務,可單獨部署到一個叢集中,無需依賴任何其他資源管理系統。從一定程度上說,該模式是其他兩種的基礎
Cluster Manager:Master
Worker Node:Worker
僅支援粗粒度的資源配置設定方式
2、Spark On Yarn模式
3、Spark On Mesos模式
粗粒度模式(Coarse-grained Mode):每個應用程式的運作環境由一個Dirver和 若幹個Executor組成,其中,每個Executor占用若幹資源,内部可運作多個Task。 應用程式的各個任務正式運作之前,需要将運作環境中的資源全部申請好,且運作過 程中要一直占用這些資源,即使不用,最後程式運作結束後,回收這些資源。
細粒度模式(Fine-grained Mode):鑒于粗粒度模式會造成大量資源浪費,Spark On Mesos還提供了另外一種排程模式:細粒度模式,這種模式類似于現在的雲計 算,核心思想是按需配置設定。
三種叢集部署模式如何選擇: 生産環境中選擇Yarn,國内使用最廣的模式
Spark的初學者:Standalone,簡單
開發測試環境,可選擇Standalone
資料量不太大、應用不是太複雜,建議可以從Standalone模式開始 mesos不會涉及到
第2節 Spark安裝配置
![pyspark學習(一)—pyspark的安裝與基礎文法一 Pysaprk的安裝二:pyspark的簡單文法END[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)