摘要:為了解決現階段大資料存算分離痛點問題,華為雲大資料推出重量級資料湖Catalog服務。
随着5G、IoT等技術的發展,企業積累了越來越多的資料,需要激發更多的資料價值變現。傳統大資料平台從建設到落地的長周期,不利于業務的高速發展;平台建成後,維護、更新、擴容均以叢集為機關,管理離散,操作繁重。
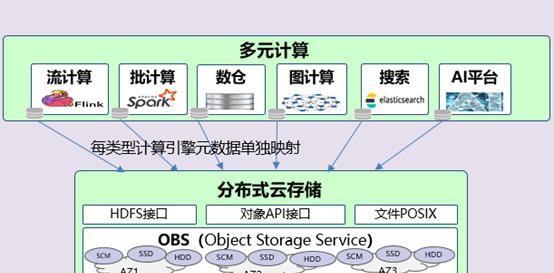
衆多使用者采用了華為雲大資料存算分離方案,存算分離解決方案指的是業務資料分離,共享的是資料,中繼資料不共享,每類引擎單獨映射建構。也正因為中繼資料不共享,導緻現階段大資料存算分離方案存在如下幾點痛點:
缺少統一管理視圖:中繼資料分散,難于統一管理;
缺少統一的細粒度權限管理:缺少統一的對資料庫、表、列的權限控制,缺少有效的邏輯及權限隔離;
計算資源無法快速擴縮容:計算叢集需要考慮中繼資料的備份和恢複,增加資源成本和運維成本;
為了解決現階段大資料存算分離痛點問題,華為雲大資料推出重量級資料湖Catalog服務。
資料湖Catalog是面向多元計算引擎提供統一進制資料服務。支援多元計算統一并共享中繼資料,實作引擎級中繼資料分離,全湖一張視圖,支援業務靈活通路,助力存算分離架構更新變遷。資料湖Catalog主要有如下五點關鍵特性:
存算分離更專業、簡化;
支援多引擎、多叢集,靈活易用,性能更高;
多元度可靠性保駕護航;
細粒度權限管控,通路共享更安全;
支援中繼資料多版本以及DAG跟蹤和分析;
經過資料湖Catalog加持後,在原有業務資料分離的基礎上,實作引擎級中繼資料分離,主要有如下三大優勢:
統一進制資料管理,全湖統一資料資産視圖,多引擎統一可視;
中繼資料多引擎共享,資料無需單獨映射,軟體多版本自由選擇;
可靠性:計算與資料完全解耦,叢集故障,資料可靠,中繼資料可靠;

下面主要介紹資料湖Catalog五大關鍵特性。
傳統存算分離解決方案一般指的是業務資料分離,共享的是資料,中繼資料不共享,每類引擎單獨映射建構。而資料湖Catalog通過統一多叢集、多類型計算的中繼資料管理,實作全湖統一資料資産視圖,多引擎統一可視,資料無需單獨映射,多引擎多版本自由選擇。
資料湖Catalog獨立部署,MRS叢集釋放不會清理中繼資料,中繼資料無需備份和遷移,節約運維管理成本,随用随釋放;
MRS叢集可以做不同的業務,所有叢集都可以很友善的實作資料共享和資料通路;
MRS叢集可以真正聚焦業務,根據業務需要進行叢集的建立和釋放,真正的可以做到按需建立、用完即釋放,節約資源和運維成本。
傳統大資料大多以MetaStore進行中繼資料管理,以thrift api方式對外提供中繼資料管理能力,且僅針對Hive生态相關中繼資料。而資料湖Catalog提供相容Hive MetaStore API和RESTfull API,支援結構化、非結構化資料源以結構化的模型進行中繼資料管理助力高層次的協作。
相容Hive MetaStore API,支援Hive生态諸如Hive/Spark/Presto/Impala/Flink等引擎,可以通過簡單的配置即可快速實作資料湖Catalog對接內建;
支援華為雲其他雲服務以開放RESTfull API的方式進行對接內建;
基于MetaStore核心自底向上逐層優化,性能更高,某客戶場景下性能較開源提升3-5倍;
随着業務快速增長,資料湖Catalog提供了多元度可靠性增強能力,快速滿足客戶業務增長的訴求,為客戶保駕護航。
支援跨AZ容災部署、節點故障容錯、特性級故障發現和自愈,為使用者提供了高可用部署架構,極大提升業務的可靠性;
支援動态流控、靜态流控、服務降級、接口級熔斷,保障業務平滑應對業務激增;
支援公共服務依賴故障放通,當周邊服務異常時,最大程度保證業務連續性;
支援豐富的叢集監控和告警能力,實時發現系統異常,保障業務穩定運作;
資料湖Catalog基于華為雲IAM實作細粒度權限管控,将中繼資料作為資源進行統一權限管理。各雲服務必須相應的權限才可以通路資料湖Catalog,例如表或分區。
支援基于角色的通路政策,資料湖Catalog對所有中繼資料的操作均支援基于角色的IAM政策。通過講政策附加到賬戶中的使用者或組,可向其授予資料湖Catalog中建立、通路或修改資料湖Catalog資源(例如表、分區)的權限。通過将政策附加到IAM角色,使用者可以向其他華為雲賬戶中的IAM角色授予跨賬戶通路權限;
支援使用資源政策控制對資料湖Catalog資源的通路,這些資源包括資料庫、表、分區和使用者定義的函數,以及與這些資源互動的APIs;
支援基于角色或資源的通路政策跨賬戶授予通路權限,實作多賬号間中繼資料的共享和通路控制。
在經典機器學習場景和深度學習場景下,資料類型、資料版本、工程(模型、腳本等)随時間變化,難以複用,難以監管。資料湖Catalog提供中繼資料多版本能力,讓AI資料開發項目如同GIT管理代碼一樣管理涉及到的資料和工程模型、腳本。與此同時,資料湖Catalog提供DAG跟蹤和分析能力,可以幫助AI資料開發按照時間線、流水線檢視不同時期、不同階段的模型名額以及上下遊資訊。資料湖Catalog可以幫助極大提升AI資料開發的效率。
使用者基于華為雲MapReduce服務建構自己的資料湖資料處理分析平台,随着企業快速發展,叢集規模和資料也急劇膨脹,使用者迫切需要完全解耦計算和資料,讓計算資源可以按需使用,集中統一管理不同存儲中的中繼資料。
資料湖Catalog價值
多MRS叢集中繼資料統一管理,避免資料孤島;
自底向上逐層優化,性能更高;
多元度可靠性保駕護航,更可靠;
支援細粒度權限管控,更安全;
大資料是AI的基礎,AI也是大資料的未來。資料湖可以很好的在經典機器學習場景和深度學習場景下服務使用者:經驗和資料靠個人、無管理;難以複用,難以監管;資料類型多,不同團隊用的工具不同,随時間變化;無資料版本和分支管理;缺乏資料回流機制,需要資料湖具備能夠統一“表”、“資料集”等概念,形成高層次的協作,需要資料湖具備能夠實作中繼資料統一并借此進行資料版本和分支管理。
提供多引擎SDK和REST API,友善使用者內建;
支援多版本管理,包括資料版本、分支、事務等;
支援AI和大資料DAG血緣跟蹤和分析;
統一進制資料模型,助力異構資料源統一資料服務;
資料湖Catalog極大增強MRS服務存算分離方面的能力,讓MRS更聚焦算力,真正能按需建立、用完即釋放,為使用者節約了資源成本和運維管理成本;同時對ModelArts建構資料湖AI開發平台提供企業級經驗和資料複用、異構資料源統一通路、多版本管理和DAG血緣管理提供了堅實的中繼資料管理基礎。對于使用者建構企業級資料湖大資料處理分析平台和資料湖AI開發平台,資料湖Catalog将會成為使用者統一進制資料管理平台首選。
同時作為一款新的重量級統一進制資料管理服務,我們在引擎中繼資料領域還在持續學習和探索過程中,資料湖Catalog後面會持續從性能優化、可靠性、生态建設、資料價值挖掘多個角度進行優化和改進,包括統計分析、CBO以及擴充應用、AI融合進階特性等。
本文分享自華為雲社群《統一進制資料,華為雲MRS 資料湖Catalog重磅推出!》,原文作者:ryanlunar。
點選關注,第一時間了解華為雲新鮮技術~