從HDFS的應用層面來看,我們可以非常容易的使用其API來操作HDFS,實作目錄的建立、删除,檔案的上傳下載下傳、删除、追加(Hadoop2.x版本以後開始支援)等功能。然而僅僅局限與代碼層面是不夠的,了解其實作的具體細節和過程是很有必要的,本文筆者給大家從以下幾個方面進行剖析:
Create
Delete
Read
Write
Heartbeat
下面開始今天的内容分享。
在HDFS上實作檔案的建立,該過程并不複雜,Client到NameNode的相關操作,如:修改檔案名,建立檔案目錄或是子目錄等,而這些操作隻涉及Client和NameNode的互動,過程如下圖所示:
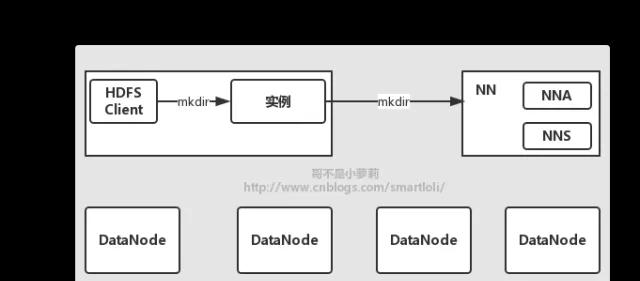
我們很熟悉,在我們使用Java 的API去操作HDFS時,我們會在Client端通過調用HDFS的FileSystem執行個體,去完成相應的功能,這裡我們不讨論FileSystem和DistributedFileSystem和關系,留在以後在閱讀這部分源碼的時候在去細說。而我們知道,在使用API實作建立這一功能時是非常友善的,代碼如下所示:
在代碼層面上,我們隻需要擷取操作HDFS的執行個體即可,調用其建立方法去實作目錄的建立。但是,其中的實作細節和相關步驟,我們是需要清楚的。在我們使用HDFS的FileSystem執行個體時,DistributedFileSystem對象會通過IPC協定調用NameNode上的mkdir()方法,讓NameNode執行具體的建立操作,在其指定的位置上建立新的目錄,同時記錄該操作并持久化操作記錄到日志當中,待方法執行成功後,mkdir()會傳回true表示建立成功來結束建立過程。在此期間,Client和NameNode不需要和DataNode進行資料互動。
在執行建立的過程當中不涉及DataNode的資料互動,而在執行一些較為複雜的操作時,如删除,讀、寫操作時,需要DataNode來配合完成對應的工作。下面以删除HDFS的檔案為突破口,來給大家展開介紹。删除流程圖如下所示:

在使用API操作删除功能時,我使用以下代碼,輸入要删除的目錄位址,然後就發現HDFS上我們所指定的删除目錄就被删除了,而然其中的删除細節和過程卻并不一定清楚,删除代碼如下所示:
通過閱讀這部分删除的API實作代碼,代碼很簡單,調用删除的方法即可完成删除功能。但它是如何完成删除的,下面就為大家這剖析一下這部分内容。
在NameNode執行delete()方法時,它隻是标記即将要删除的Block(操作删除的相關記錄是被記錄并持久化到日志當中的,後續的相關HDFS操作都會有此記錄,便不再提醒),NameNode是被動服務的,它不會主動去聯系儲存這些資料的Block的DataNode來立即執行删除。而我們可以從上圖中發現,在DataNode向NameNode發送心跳時,在心跳的響應中,NameNode會通過DataNodeCommand來指令DataNode執行删除操作,去删除對應的Block。而在删除時,需要注意,整個過程當中,NameNode不會主動去向DataNode發送IPC調用,DataNode需要完成資料删除,都是通過DataNode發送心跳得到NameNode的響應,擷取DataNodeCommand的執行指令。
在讀取HDFS上的檔案時,Client、NameNode以及DataNode都會互相關聯。按照一定的順序來實作讀取這一過程,讀取過程如下圖所示:
通過上圖,讀取HDFS上的檔案的流程可以清晰的知道,Client通過執行個體打開檔案,找到HDFS叢集的具體資訊(我們需要操作的是ClusterA,還是ClusterB,需要讓Client端知道),這裡會建立一個輸入流,這個輸入流是連接配接DataNode的橋梁,相關資料的讀取Client都是使用這個輸入流來完成的,而在輸入流建立時,其構造函數中會通過一個方法來擷取NameNode中DataNode的ID和Block的位置資訊。Client在拿到DataNode的ID和Block位置資訊後,通過輸入流去讀取資料,讀取規則按照“就近原則”,即:和最近的DataNode建立聯系,Client反複調用read方法,并将讀取的資料傳回到Client端,在達到Block的末端時,輸入流會關閉和該DataNode的連接配接,通過向NameNode擷取下一個DataNode的ID和Block的位置資訊(若對象中為緩存Block的位置資訊,會觸發此步驟,否則略過)。然後拿到DataNode的ID和Block的位置資訊後,在此連接配接最佳的DataNode,通過此DataNode的讀資料接口,來擷取資料。
另外,每次通過向NameNode回去Block資訊并非一次性擷取所有的Block資訊,需得多次通過輸入流向NameNode請求,來擷取下一組Block得位置資訊。然而這一過程對于Client端來說是透明的,它并不關系是一次擷取還是多次擷取Block的位置資訊,Client端在完成資料的讀取任務後,會通過輸入流的close()方法來關閉輸入流。
在讀取的過程當中,有可能發生異常,如:節點掉電、網絡異常等。出現這種情況,Client會嘗試讀取下一個Block的位置,同時,會标記該異常的DataNode節點,放棄對該異常節點的讀取。另外,在讀取資料的時候會校驗資料的完整性,若出現校驗錯誤,說明該資料的Block已損壞,已損壞的資訊會上報給NameNode,同時,會從其他的DataNode節點讀取相應的副本内容來完成資料的讀取。Client端直接聯系NameNode,由NameNode配置設定DataNode的讀取ID和Block資訊位置,NameNode不提供資料,它隻處理Block的定位請求。這樣,防止由于Client的并發資料量的迅速增加,導緻NameNode成為系統“瓶頸”(磁盤IO問題)。
HDFS的寫檔案過程較于建立、删除、讀取等,它是比較複雜的一個過程。下面,筆者通過一個流程圖來為大家剖析其中的細節,如下圖所示:
Client端通過執行個體的create方法建立檔案,同時執行個體建立輸出流對象,并通過遠端調用,通知NameNode執行建立指令,建立一個新檔案,執行此指令需要進行各種校驗,如NameNode是否處理Active狀态,被建立的檔案是否存在,Client建立目錄的權限等,待這些校驗都通過後,NameNode會建立一個新檔案,完成整個此過程後,會通過執行個體将輸出流傳回給Client。
這裡,我們需要明白,在向DataNode寫資料的時候,Client需要知道它需要知道自身的資料要寫往何處,在茫茫Cluster中,DataNode成百上千,寫到DataNode的那個Block塊下,是Client需要清楚的。在通過create建立一個空檔案時,輸出流會向NameNode申請Block的位置資訊,在拿到新的Block位置資訊和版本号後,輸出流就可以聯系DataNode節點,通過寫資料流建立資料流管道,輸出流中的資料被分成一個個檔案包,并最終打包成資料包發往資料流管道,流經管道上的各個DataNode節點,并持久化。
Client在寫資料的檔案副本預設是3份,換言之,在HDFS叢集上,共有3個DataNode節點會儲存這份資料的3個副本,用戶端在發送資料時,不是同時發往3個DataNode節點上寫資料,而是将資料先發送到第一個DateNode節點,然後,第一個DataNode節點在本地儲存資料,同時推送資料到第二個DataNode節點,依此類推,直到管道的最後一個DataNode節點,資料确認包由最後一個DataNode産生,并逆向回送給Client端,在沿途的DataNode節點在确認本地寫入成功後,才會往自己的上遊傳遞應答資訊包。這樣做的好處總結如下:
分攤寫資料的流量:由每個DataNode節點分攤寫資料過程的網絡流量。
降低功耗:減小Client同時發送多份資料到DataNode節點造成的網絡沖擊。
另外,在寫完一個Block後,DataNode節點會通過心跳上報自己的Block資訊,并送出Block資訊到NameNode儲存。當Client端完成資料的寫入之後,會調用close()方法關閉輸出流,在關閉之後,Client端不會在往流中寫資料,因而,在輸出流都收到應答包後,就可以通知NameNode節點關閉檔案,完成一次正常的寫入流程。
在寫資料的過程當中,也是有可能出現節點異常。然而這些異常資訊對于Client端來說是透明的,Client端不會關心寫資料失敗後DataNode會采取哪些措施,但是,我們需要清楚它的處理細節。首先,在發生寫資料異常後,資料流管道會被關閉,在已經發送到管道中的資料,但是還沒有收到确認應答封包件,該部分資料被重新添加到資料流,這樣保證了無論資料流管道的哪個節點發生異常,都不會造成資料丢失。而目前正常工作的DateNode節點會被賦予新的版本号,并通知NameNode。即使,在故障節點恢複後,上面隻有部分資料的Block會因為Blcok的版本号與NameNode儲存的版本号不一緻而被删除。之後,在重建立立新的管道,并繼續寫資料到正常工作的DataNode節點,在檔案關閉後,NameNode節點會檢測Block的副本數是否達标,在未達标的情況下,會選擇一個新的DataNode節點并複制其中的Block,建立新的副本。這裡需要注意的是,DataNode節點出現異常,隻會影響一個Block的寫操作,後續的Block寫入不會收到影響。
前面說過,NameNode和DataNode之間資料互動,是通過DataNode節點向NameNode節點發送心跳來擷取NameNode的操作指令。心跳發送之前,DataNode需要完成一些步驟之後,才能發送心跳,流程圖如下所示:
從上圖來看,首先需要向NameNode節點發送校驗請求,檢測是否NameNode節點和DataNode節點的HDFS版本是否一緻(有可能NameNode的版本為2.6,DataNode的版本為2.7,是以第一步需要校驗版本)。在版本校驗結束後,需要向NameNode節點注冊,這部分的作用是檢測該DataNode節點是否屬于NameNode節點管理的成員之一,換言之,ClusterA的DataNode節點不能直接注冊到ClusterB的NameNode節點上,這樣保證了整個系統的資料一緻性。在完成注冊後,DataNode節點會上報自己所管理的所有的Block資訊到NameNode節點,幫助NameNode節點建立HDFS檔案Block到DataNode節點映射關系(即儲存Meta),在完成此流程之後,才會進入到心跳上報流程。
另外,如果NameNode節點長時間接收不到DataNode節點到心跳,它會認為該DataNode節點的狀态處理Dead狀态。如果NameNode有些指令需要DataNode配置操作(如:前面的删除指令),則會通過心跳後的DataNodeCommand這個傳回值,讓DataNode去執行相關指令。
簡而言之,關于HDFS的建立、删除、讀取以及寫入等流程,可以一言以蔽之,内容如下:
Create:Client直接與NameNode互動,不涉及DataNode
Delete:Client将删除指令存于NameNode,DataNode通過心跳擷取NameNode的操作指令
Read:Client通過NameNode擷取讀取資料的位置,找到DataNode節點對應的Block位置讀取資料
Write:Client通過NameNode後區寫資料的位置,找到DataNode節點對應的Block位置進行寫入