Unicode規範中有一個BOM的概念。BOM——Byte Order Mark,就是位元組序标記。在這裡找到一段關于BOM的說明:
在UCS 編碼中有一個叫做"ZERO WIDTH NO-BREAK SPACE"的字元,它的編碼是FEFF。而FFFE在UCS中是不存在的字元,是以不應該出現在實際傳輸中。UCS規範建議我們在傳輸位元組流前,先傳輸 字元"ZERO WIDTH NO-BREAK SPACE"。這樣如果接收者收到FEFF,就表明這個位元組流是Big-Endian的;如果收到FFFE,就表明這個位元組流是Little- Endian的。是以字元"ZERO WIDTH NO-BREAK SPACE"又被稱作BOM。
UTF-8不需要BOM來表明位元組順序,但可以用BOM來表明編碼方式。字元"ZERO WIDTH NO-BREAK SPACE"的UTF-8編碼是EF BB BF。是以如果接收者收到以EF BB BF開頭的位元組流,就知道這是UTF-8編碼了。
Windows就是使用BOM來标記文本檔案的編碼方式的。
另外unicode網站的FAQ-BOM詳細介紹了BOM。官方的自然權威,不過是英文的,看起來比較費勁。
UTF- 8編碼的檔案中,BOM占三個位元組。如果用記事本把一個文本檔案另存為UTF-8編碼方式的話,用UE打開這個檔案,切換到十六進制編輯狀态就可以看到開 頭的FFFE了。這是個辨別UTF-8編碼檔案的好辦法,軟體通過BOM來識别這個檔案是否是UTF-8編碼,很多軟體還要求讀入的檔案必須帶BOM。可 是,還是有很多軟體不能識别BOM。我在研究Firefox的時候就知道,在Firefox早期的版本裡,擴充是不能有BOM的,不過Firefox 1.5以後的版本已經開始支援BOM了。現在又發現,PHP也不支援BOM。
PHP在設計時就沒有考慮BOM的問題,也就是說他不會忽略 UTF-8編碼的檔案開頭BOM的那三個字元。由于必須在<?或者<?php後面的代碼才會作為PHP代碼執行,是以這三個字元将會直接輸 出。如果遇到header(),session(),cookie()等問題,将會導緻亂碼或顯示白屏等問題.
下面附上editplus去BOM頭的方法
EditPlus編輯UTF-8檔案時删除BOM方法
編輯器調整為UTF8編碼格式後,儲存的檔案前面會多出一串隐藏的字元(也即是BOM),用于編輯器識别這個檔案是否是以UTF8編碼。一般的文本檔案會忽略這一串隐藏的字元,但對于PHP等檔案會解析這一串字元,這樣會導緻出錯。
運作Editplus,點選工具,選擇首選項,如下圖:
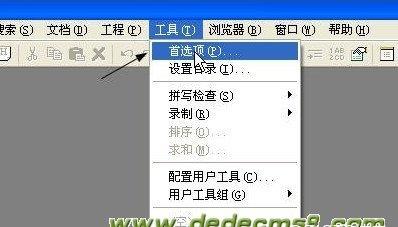
選中檔案,UTF-8辨別選擇 總是删除簽名,如下圖:

然後對PHP檔案編輯和儲存後的PHP檔案就是不帶BOM的了
BOM定義了JavaScript可以進行操作的浏覽器的各個功能部件的接口,提供通路文檔各個功能部件(如視窗本身、螢幕功能部件、浏覽曆史記錄等)的 途徑以及操作方法。遺憾的是,BOM隻是JavaScript腳本實作的一部分,沒有任何相關的标準,每種浏覽器都有自己的BOM實作,這可以說是BOM 的軟肋所在。
通常情況下浏覽器特定的JavaScript擴充都被看作BOM的一部分,主要包括:
·關閉、移動浏覽器及調整浏覽器視窗大小;
·彈出新的浏覽器視窗;
·提供浏覽器詳細資訊的定位對象;
·提供載入到浏覽器視窗的文檔詳細資訊的定位對象;
·提供使用者螢幕分辨率詳細資訊的螢幕對象;
·提供對cookie的支援;
·加入ActiveXObject類擴充BOM,通過JavaScript執行個體化ActiveX對象。
BOM有一些事實上的标準,如視窗對象、導航對象等,但每種浏覽器都為這些對象定義或擴充了屬性及方法。