最近在分析一個 dump 的過程中發現其在 gen2 和 LOH 上有不少size較大的free,仔細看了下,這些free生前大多都是模闆引擎生成的html片段的byte[]數組,當然這篇我不是來分析dump的,而是來聊一下,當托管堆有很多length較大的 byte[] 數組時,如何讓記憶體利用更高效,如何讓gc老先生壓力更小。
不知道大家有沒有發現在 .netcore 中增加了不少池化對象的東西,比如: ArrayPool,ObjectPool 等等,确實在某些場景下還是特别實用的,是以有必要對其進行較深入的了解。
在我花了将近一個小時的源碼閱讀之後,我畫了一張 ArrayPool 的池化圖,所謂:<code>一圖在手,天下我有</code> 。
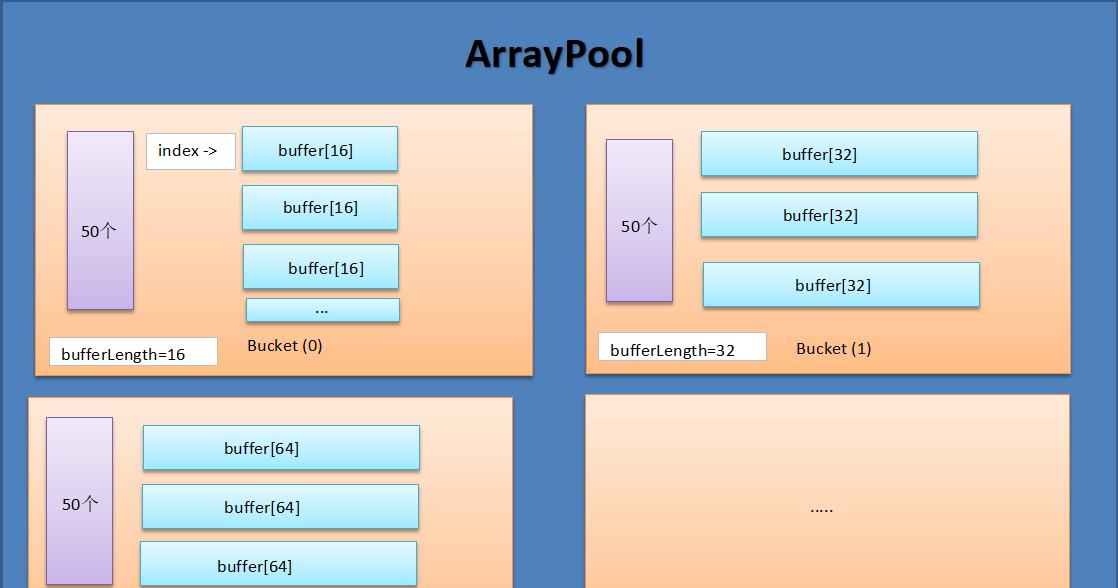
有了這張圖,接下來再聊幾個概念并配上相應源碼,我覺得應該就差不多了。
ArrayPool 是由若幹個 Bucket 組成, 而 Bucket 又由若幹個 <code>buffer[]</code> 數組組成, 有了這個概念之後,再配一下代碼。
這個問題很好回答,初始化時做了 <code>maxArraysPerBucket=50</code> 設定,當然你也可以自定義,具體參考如下代碼:
架構做了預設假定,第一個bucket中的 <code>buffer[].length=16</code>, 後續 bucket 中的 <code>buffer[].length</code> 都是 x2 累計,涉及到代碼就是 <code>GetMaxSizeForBucket()</code> 方法,參考如下:
其實在上圖中我也沒有給出 bucket 到底有多少個,那到底是多少個呢?😓😓😓 ,當我閱讀完源碼之後,這算法還挺有意思的。
先說一下結果吧,預設 17 個 bucket,你肯定會好奇怎麼算的? 先說下兩個變量:
maxArrayLength=1048576 = 2的20次方
buffer.length= 16 = 2的4次方
最後的算法就是取次方的內插補點:<code>bucket[].length= 20 - 4 + 1 = 17</code>,換句話說最後一個 bucket 下的 <code>buffer[].length=1048576</code>,詳細代碼請參考 <code>SelectBucketIndex()</code> 方法。
到這裡我相信你對 ArrayPool 的池化架構思路已經搞明白了,接下來看下如何申請和歸還 buffer[]。
既然 buffer[] 做了顆粒化,那就應該好借好還,反應到代碼上就是 <code>Rent()</code> 和 <code>Return()</code> 方法,為了友善了解,上代碼說話:

有了代碼和圖之後,再稍微捋一下流程。
從 ArrayPool 中借一個 <code>byte[10]</code> 大小的數組,為了節省記憶體,先不備貨,臨時生成一個 <code>byte[].size=16</code> 的數組出來,簡化後的代碼如下,參考 <code>if (flag)</code> 處:
這裡有一個坑,那就是你以為借了 <code>byte[10]</code>,現實給你的是 <code>byte[16]</code>,這裡稍微注意一下。
當用 ArrayPool.Return 歸還 <code>byte[16]</code> 時, 很明顯看到它落到了第一個bucket的第一個buffer[]上,參考如下簡化後的代碼:
這裡也有一個值得注意的坑,那就是還回去的 <code>byte[16]</code> 裡面的資料預設是不會清掉的,從上面的代碼也是可以看出來的,要想做清理,需要在 Return 方法中指定 <code>clearArray=true</code>,參考如下代碼:
學習這其中的 <code>池化架構</code> 思想,對平時項目開發還是能提供一些靈感的,其次對那些一次性使用 <code>byte[]</code> 的場景,用池化是個非常不錯的方法,這也是我對朋友dump分析後提出的一個優化思路。
更多高品質幹貨:參見我的 GitHub: dotnetfly