摘要: Flink是jvm之上的大資料處理引擎。
Flink是jvm之上的大資料處理引擎,jvm存在java對象存儲密度低、full gc時消耗性能,gc存在stw的問題,同時omm時會影響穩定性。同時針對頻繁序列化和反序列化問題flink使用堆内堆外記憶體可以直接在一些場景下操作二進制資料,減少序列化反序列化的消耗。同時基于大資料流式處理的特點,flink定制了自己的一套序列化架構。flink也會基于cpu L1 L2 L3高速緩存的機制以及局部性原理,設計使用緩存友好的資料結構。flink記憶體管理和spark的tungsten的記憶體管理的出發點很相似。
Flink可以使用堆内和堆外記憶體,記憶體模型如圖所示:
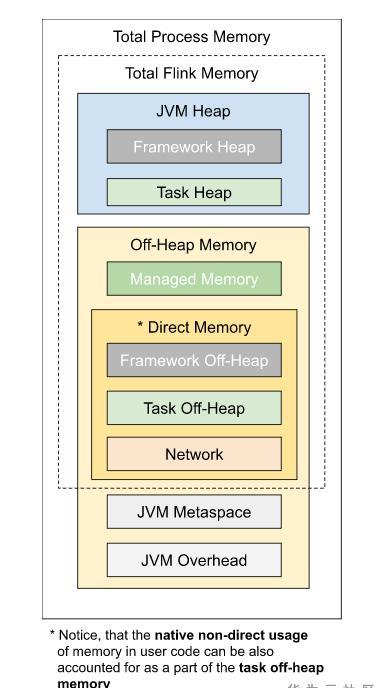

flink使用記憶體劃分為堆内記憶體和堆外記憶體。按照用途可以劃分為task所用記憶體,network memory、managed memory、以及framework所用記憶體,其中task network managed所用記憶體計入slot記憶體。framework為taskmanager公用。
堆内記憶體包含使用者代碼所用記憶體、heapstatebackend、架構執行所用記憶體。
堆外記憶體是未經jvm虛拟化的記憶體,直接映射到作業系統的記憶體位址,堆外記憶體包含架構執行所用記憶體,jvm堆外記憶體、Direct、native等。
Direct memory記憶體可用于網絡傳輸緩沖。network memory屬于direct memory的範疇,flink可以借助于此進行zero copy,進而減少核心态到使用者态copy次數,進而進行更高效的io操作。
jvm metaspace存放jvm加載的類的中繼資料,加載的類越多,需要的空間越大,overhead用于jvm的其他開銷,如native memory、code cache、thread stack等。
Managed Memory主要用于RocksDBStateBackend和批處理算子,也屬于native memory的範疇,其中rocksdbstatebackend對應rocksdb,rocksdb基于lsm資料結構實作,每個state對應一個列族,占有獨立的writebuffer,rocksdb占用native記憶體大小為 blockCahe + writebufferNum * writeBuffer + index ,同時堆外記憶體是程序之間共享的,jvm虛拟化大量heap記憶體耗時較久,使用堆外記憶體的話可以有效的避免該環節。但堆外記憶體也有一定的弊端,即監控調試使用相對複雜,對于生命周期較短的segment使用堆内記憶體開銷更低,flink在一些情況下,直接操作二進制資料,避免一些反序列化帶來的開銷。如果需要處理的資料超出了記憶體限制,則會将部分資料存儲到硬碟上。
類似于OS中的page機制,flink模拟了作業系統的機制,通過page來管理記憶體,flink對應page的資料結構為dataview和MemorySegment,memorysegment是flink記憶體配置設定的最小機關,預設32kb,其可以在堆上也可以在堆外,flink通過MemorySegment的資料結構來通路堆内堆外記憶體,借助于flink序列化機制(序列化機制會在下一小節講解),memorysegment提供了對二進制資料的讀取和寫入的方法,flink使用datainputview和dataoutputview進行memorysegment的二進制的讀取和寫入,flink可以通過HeapMemorySegment 管理堆内記憶體,通過HybridMemorySegment來管理堆内和堆外記憶體,MemorySegment管理jvm堆記憶體時,其定義一個位元組數組的引用指向記憶體端,基于該内部位元組數組的引用進行操作的HeapMemorySegment。
HeapMemorySegment用來配置設定堆上記憶體。
HybridMemorySegment即支援onheap和offheap記憶體,flink通過jvm的unsafe操作,如果對象o不為null,為onheap的場景,并且後面的位址或者位置是相對位置,那麼會直接對目前對象(比如數組)的相對位置進行操作。如果對象o為null,操作的記憶體塊不是JVM堆記憶體,為off-heap的場景,并且後面的位址是某個記憶體塊的絕對位址,那麼這些方法的調用也相當于對該記憶體塊進行操作。
flink通過MemorySegmentFactory來建立memorySegment,memorySegment是flink記憶體配置設定的最小機關。對于跨memorysegment的資料方位,flink抽象出一個通路視圖,資料讀取datainputView,資料寫入dataoutputview。
dataoutputview是資料寫入的視圖,outputview持有多個memorysegment的引用,flink可以順序的寫入segment。
上一小節中講到的managedmemory記憶體部分,flink使用memorymanager來管理該記憶體,managedmemory隻使用堆外記憶體,主要用于批進行中的sorting、hashing、以及caching(社群消息,未來流處理也會使用到該部分),在流計算中作為rocksdbstatebackend的部分記憶體。memeorymanager通過memorypool來管理memorysegment。
對于上一小節中提到的NetWorkMemory的記憶體,flink使用networkbuffer做了一層buffer封裝。buffer的底層也是memorysegment,flink通過bufferpool來管理buffer,每個taskmanager都有一個netwokbufferpool,該tm上的各個task共享該networkbufferpool,同時task對應的localbufferpool所需的記憶體需要從networkbufferpool申請而來,它們都是flink申請的堆外記憶體。
上遊算子向resultpartition寫入資料時,申請buffer資源,使用bufferbuilder将資料寫入memorysegment,下遊算子從resultsubpartition消費資料時,利用bufferconsumer從memorysegment中讀取資料,bufferbuilder與bufferconsumer一一對應。同時這一流程也和flink的反壓機制相關。如圖
flink對自身支援的基本資料類型,實作了定制的序列化機制,flink資料集對象相對固定,可以隻儲存一份schema資訊,進而節省存儲空間,資料序列化就是java對象和二進制資料之間的資料轉換,flink使用TypeInformation的createSerializer接口負責建立每種類型的序列化器,進行資料的序列化反序列化,類型資訊在建構streamtransformation時通過typeextractor根據方法簽名類資訊等提取類型資訊并存儲在streamconfig中。
對于嵌套的資料類型,flink從最内層的字段開始序列化,内層序列化的結果将組成外層序列化結果,反序列時,從記憶體中順序讀取二進制資料,根據偏移量反序列化為java對象。flink自帶序列化機制存儲密度很高,序列化對應的類型值即可。
flink中的table子產品在memorysegment的基礎上使用了BinaryRow的資料結構,可以更好地減少反序列化開銷,需要反序列化是可以隻序列化相應的字段,而無需序列化整個對象。
同時你也可以注冊子類型和自定義序列化器,對于flink無法序列化的類型,會交給kryo進行處理,如果kryo也無法處理,将強制使用avro來序列化,kryo序列化性能相對flink自帶序列化機制較低,開發時可以使用env.getConfig().disableGenericTypes()來禁用kryo,盡量使用flink架構自帶的序列化器對應的資料類型。
cpu中L1、L2、L3的緩存讀取速度比從記憶體中讀取資料快很多,高速緩存的通路速度是主存的通路速度的很多倍。另外一個重要的程式特性是局部性原理,程式常常使用它們最近使用的資料和指令,其中兩種局部性類型,時間局部性指最近通路的内容很可能短期内被再次通路,空間局部性是指位址互相臨近的項目很可能短時間内被再次通路。
結合這兩個特性設計緩存友好的資料結構可以有效的提升緩存命中率和本地化特性,該特性主要用于排序操作中,正常情況下一個指針指向一個<key,v>對象,排序時需要根據指針pointer擷取到實際資料,然後再進行比較,這個環節涉及到記憶體的随機通路,快取區域化會很低,使用序列化的定長key + pointer,這樣key就會連續存儲到記憶體中,避免的記憶體的随機通路,還可以提升cpu緩存命中率。對兩條記錄進行排序時首先比較key,如果大小不同直接傳回結果,隻需交換指針即可,不用交換實際資料,如果相同,則比較指針實際指向的資料。
flink社群已走向流批一體的發展,後繼将更多的關注與流批一體的引擎實作及結合存儲層面的實作。flink服務請使用華為雲 EI DLI-FLINK serverless服務。
[1]: https://ci.apache.org/projects/flink/flink-docs-stable/
[2]: https://github.com/apache/flink
[3]: https://ververica.cn/
點選關注,第一時間了解華為雲新鮮技術~