版權聲明:歡迎轉載,但是看在我辛勤勞動的份上,請注明來源:http://blog.csdn.net/yinwenjie(未經允許嚴禁用于商業用途!)
https://blog.csdn.net/yinwenjie/article/details/51064242
目錄(?)[+]
(接上文《架構設計:系統間通信(23)——提高ActiveMQ工作性能(中)》)
7、ActiveMQ的持久消息存儲方案
前文已經講過,當ActiveMQ接收到PERSISTENT Message消息後就需要借助持久化方案來完成PERSISTENT
Message的存儲。這個媒體可以是磁盤檔案系統、可以是ActiveMQ的内置資料庫,還可以是某種外部提供的關系型資料庫。本節筆者将向讀者講解三種ActiveMQ推薦的存儲方案的配置使用。
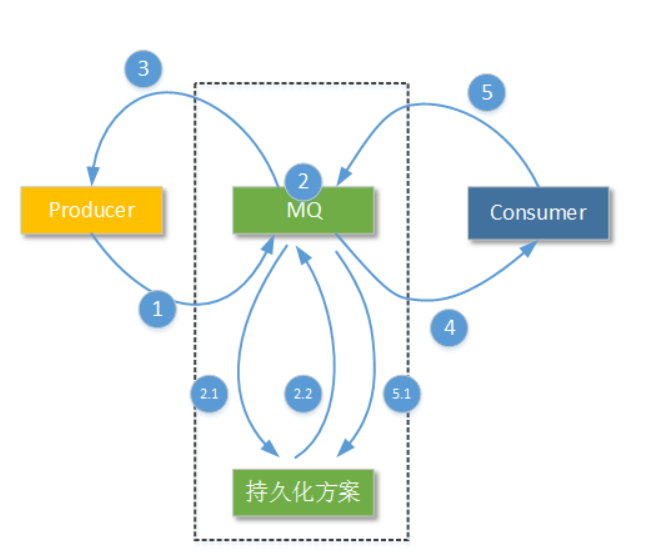
如上圖2.1的步驟所示,所有PERSISTENT Message都要執行持久化存儲操作,持久化存儲操作方案的性能直接影響着整個MQ服務端的PERSISTENT Message吞吐性能。另外NON_PERSISTENT Message雖然不會進行持久化存儲,但是NON_PERSISTENT Message也不是永遠都隻存在與記憶體區域。
有的讀者會問,Topic模式的工作隊列在沒有任何活動訂閱者的情況下也會對PERSISTENT
Message進行持久化存儲嗎?當然會,因為Topic模式的工作隊列還要考慮“Durable Topic
Subscribers”形式的訂閱者。即使沒有“Durable Topic
Subscribers”形式的訂閱者,先存儲再标記的過程也不會改變(隻是不一定真正進入實體磁盤)。
有的讀者還會問,在用戶端啟動事務的情況下,如果沒有事務的commit操作,PERSISTENT
Message也會進行持久化存儲嗎?當然還是會,前文我們已經講過沒有做事務的commit隻是說這些事務中的消息不會進行确認操作,不會分發到某個指定的具體隊列中;但是隻要使用了send方法,PERSISTENT Message就會被發送到服務端,就會進行持久化存儲操作。
如上圖中被标示為2.2的操作步驟所示,在ActiveMQ設定的持久化方案完成某條消息的持久化後,會在ActiveMQ服務節點的内部發出一個“完成”信号。這是為了告訴ActiveMQ服務節點自己,是否可以進行下一步操作。但是為了加快ActiveMQ服務節點内部的處理效率,這個過程可以設定為“異步”。
那麼進行了持久化存儲的PERSISTENT
Message什麼時候被删除呢?就如同之前我們提到的一樣,ActiveMQ服務端隻有在收到消費者端某一條消息或某一組消息的ACK标示後,才會認為消息被消費者端正确處理了。就是在這個時候,ActiveMQ會通知持久化方案,進行删除這一條或者這一組消息的操作,并空閑出相應的存儲空間。如上圖被标示為5.1的操作步驟所示。
在介紹ActiveMQ的存儲方案之前,首先需要明确的是ActiveMQ中的幾種“容量”描述:
ActiveMQ的核心是Java編寫的,也就是說如果服務端沒有Java運作環境ActiveMQ是無法運作的。ActiveMQ啟動時,啟動腳本使用wrapper包裝器來啟動JVM。JVM相關的配置資訊在啟動目錄的“wrapper.conf”配置檔案中。各位讀者可以通過改變其中的配置項,設定JVM的初始記憶體大小和最大記憶體大小(當然還可以進行其他和JVM有關的設定,例如開啟debug模式),如下:
以上配置項設定JVM的初始記憶體大小為100MB,設定JVM的最大記憶體大小為512MB。如果您在更改後使用console參數啟動ActiveMQ,那麼會看到目前ActiveMQ的JVM設定發生了變化:

明确了ActiveMQ的記憶體區域來源,才好了解後續的設定内容。ActiveMQ每一個服務節點都是一個獨立的程序。在ActiveMQ主配置檔案中,讀者可以找到一個“systemUsage”标記,類似定義如下:
systemUsage:該标記用于設定整個ActiveMQ節點在程序級别的各種“容量”的設定情況。其中可設定的屬性包括:sendFailIfNoSpaceAfterTimeout,當ActiveMQ收到一條消息時,如果ActiveMQ這時已經沒有多餘“容量”了,那麼就會等待一段時間(這裡設定的毫秒數),如果超過這個等待時間ActiveMQ仍然沒有可用的容量,那麼就拒絕接收這條消息并在消息的發送端抛出javax.jms.ResourceAllocationException異常;sendFailIfNoSpace,當ActiveMQ收到一條消息時,如果ActiveMQ這時已經沒有多餘“容量”了,就直接拒絕這條消息(不用等待一段時間),并在消息的發送端抛出javax.jms.ResourceAllocationException異常。
memoryUsage:該子标記設定整個ActiveMQ節點的“可用記憶體限制”。這個值不能超過上文中您設定的JVM
maxmemory的值。其中的percentOfJvmHeap屬性表示使用“百分數值”進行設定,除了這個屬性以外,您還可以使用limit屬性進行固定容量授權,例如:limit=”1000
mb”。這些記憶體容量将供所有隊列使用。
storeUsage:該标記設定整個ActiveMQ節點,用于存儲“持久化消息”的“可用磁盤空間”。該子标記的limit屬性必須要進行設定。在使用後續介紹的KahaDB方案或者LevelDB方案進行PERSISTENT
Message持久化存儲時,這個storeUsage屬性都會起作用;但是如果使用資料庫存儲方案,這個屬性就不會起作用了。
tempUsage:在ActiveMQ 5.X+
版本中,一旦ActiveMQ服務節點存儲的消息達到了memoryUsage的限制,NON_PERSISTENT Message就會被轉儲到
temp store區域。雖然我們說過NON_PERSISTENT Message不進行持久化存儲,但是ActiveMQ為了防止“資料洪峰”出現時NON_PERSISTENT Message大量堆積緻使記憶體耗盡的情況出現,還是會将NON_PERSISTENT Message寫入到磁盤的臨時區域——temp store。這個子标記就是為了設定這個temp store區域的“可用磁盤空間限制”。最後提醒各位讀者storeUsage和tempUsage并不是“最大可用空間”,而是一個閥值。
說到ActiveMQ中持久化存儲方案的演化問題,如果您仔細閱讀ActiveMQ官方文檔中關于持久化部分的描述,您就不難發現ActiveMQ的開發團隊在針對持久化性能問題的優化上可謂與時俱進。這也符合一款健壯軟體的生命周期特征:任何功能特性都在進行不斷累計完善:
從最初的AMQ Message Store方案,到ActiveMQ V4版本中推出的High performance
journal(高性能事務支援)附件 ,并且同步推出了關于關系型資料庫的存儲方案。ActiveMQ
5.3版本中又推出了對KahaDB的支援(V5.4版本後稱為ActiveMQ預設的持久化方案),後來ActiveMQ
V5.8版本開始支援LevelDB,到現在,V5.9+版本提供了标準的Zookeeper+LevelDB叢集化方案。下面我們重點介紹一下ActiveMQ中KahaDB、LevelDB和關系型資料庫這三種持久化存儲方案。并且會和讀者一起,使用Zookeeper搭建LevelDB叢集存儲方案。
對于最初的AMQ Message Store方案,ActiveMQ官方已不再推薦使用(實際上在筆者的實際工作中,也不會使用AMQ Message Store)。如果各位讀者想進行了解可以自行搜尋相關資料,這裡不再進行介紹。
KahaDB is a file based persistence database that is local to the message broker that is using it. It has been optimised for fast persistence and is the the default storage mechanism from ActiveMQ 5.4 onwards. KahaDB uses less file descriptors and provides faster recovery than its predecessor, the AMQ Message Store.
以上引用自Apache ActiveMQ
官方對KahaDB的定義。首先KahaDB基于檔案系統,其次KahaDB支援事務。在ActiveMQ
V5.4版本及後續版本KahaDB都是ActiveMQ的預設持久化存儲方案。最後Apache ActiveMQ官方表示它用來替換之前的AMQ
Message Store存儲方案。
KahaDB主要元素包括:一個記憶體Metadata Cache用來在記憶體中檢索消息的存儲位置、若幹用于記錄消息内容的Data
log檔案、一個在磁盤上檢索消息存儲位置的Metadata
Store、還有一個用于在系統異常關閉後恢複Btree結構的redo檔案。如下圖所示(官網引用):
以下是KahaDB在磁盤檔案上的現實展示。注意,可能您檢視自己測試執行個體中所運作的KahaDB,看到的效果和本文中給出的效果不完全一緻。例如您的data
log檔案可能叫db-1.log,也有可能會多出一個db.free的檔案,但是這些都不影響我們對檔案結構的分析:
db-3.log:這個檔案就是我們上文提到的Data log檔案。一個KahaDB中,可能同時存在多個Data
log檔案,他們存儲了每一條持久化消息的真正内容。這些Data log檔案統一采用db-*.log的格式進行命名,并且每個Data
log檔案預設的大小都是32M(當然是可以進行設定的)。當一個Data log檔案中的所有消息全部被成功消息後,這個Data log檔案會在Metadata Cache中被标記為删除,并在下個checkpoint周期進行删除操作。
各位讀者可能已經注意到一個現象:為什麼db-3.log的預設占用大小就是32M,但是目錄顯示的“總用量”卻隻有29M呢?在這個檔案夾中,除了db-3.log檔案本身,加上其他幾個檔案所占用的大小,已經遠遠超過了32M!這是因為,為了加快寫檔案的性能,Data log檔案采用順序寫的方式進行操作,為了保證檔案使用的扇區在實體上是連續的,是以Data log檔案需要預占這些扇區(這個和Hadoop中每一個block大小都是固定的原因相似)。雖然您看到Data log檔案占用的32M的磁盤空間,但是這些磁盤空間并沒有全部使用。另外,關于随機讀寫和連續讀寫的巨大性能差異,我會在今年下半年新的“資料存儲專欄”中,進行詳細介紹。
為了更快的找到某個具體消息在Data
log檔案中的具體位置。消息的位置索引采用BTree的結構被存儲在記憶體中,這個記憶體區域就是上文提到的Metadata
Cache(大小也是可以設定的)。要知道Mysql的Innodb
存儲引擎也是采用BTree結構構造索引結構(用了都說快哦~~)。是以一般情況下,隻要某個隊列有活動的消費者存在,消息的定位、讀取操作是可以很快完成的。
記憶體中沒有被處理的消息索引會以一定的周期(或者一定的數量規模)為依據,同步(checkpoint)到Metadata Store中,這就是我們在上文中看到的“db.data”檔案。當然db.redo檔案也會被更新,以便在ActiveMQ服務節點在重新開機後對Metadata Cache進行恢複。最後,消息同步(checkpoint)依據,可以在ActiveMQ的主配置檔案中進行設定。
由于在ActiveMQ V5.4+的版本中,KahaDB是預設的持久化存儲方案。是以即使您不配置任何的KahaDB參數資訊,ActiveMQ也會啟動KahaDB。這種情況下,KahaDB檔案所在位置是您的ActiveMQ安裝路徑下的/data/${broker.Name}/KahaDB子目錄。其中${broker.Name}代表這個ActiveMQ服務節點的名稱。
正式的生産環境還是建議您在主配置檔案中明确設定KahaDB的工作參數。如下所示:
以上配置項設定使用kahaDB為持久化存儲方法,并且設定kahaDB的工作目錄為ActiveMQ安裝路勁下/data/kahadb目錄。如果您需要Data
log檔案預設的32M的大小,可以使用journalMaxFileLength屬性進行設定,如下所示:
您還可以設定為:當Metadata Cache中和Metadata Store中不同的索引條數達到500條時,就進行checkpoint同步。如下所示:
以下表格為讀者示例了KahaDB中所有的配置選項和其含義(引用自網絡,加“*”部分是筆者認為重要的配置選項):
property name
default value
Comments
*directory
activemq-data
消息檔案和日志的存儲目錄
*indexWriteBatchSize
1000
當Metadata cache區域和Metadata store區域不同的索引數量達到這個值後,Metadata cache将會發起checkpoint同步
*indexCacheSize
10000
記憶體中,索引的頁大小。超過這個大小Metadata cache将會發起checkpoint同步
*enableIndexWriteAsync
false
索引是否異步寫到消息檔案中,将以不要設定為true
*journalMaxFileLength
32mb
一個消息檔案的大小
*enableJournalDiskSyncs
true
如果為true,保證使用同步寫入的方式持久化消息到journal檔案中
*cleanupInterval
30000
清除(清除或歸檔)不再使用的db-*.log檔案的時間周期(毫秒)。
*checkpointInterval
5000
寫入索引資訊到metadata store中的時間周期(毫秒)
ignoreMissingJournalfiles
是否忽略丢失的journal檔案。如果為false,當丢失了journal檔案時,broker啟動時會抛異常并關閉
checkForCorruptJournalFiles
檢查消息檔案是否損壞,true,檢查發現損壞會嘗試修複
checksumJournalFiles
産生一個checksum,以便能夠檢測journal檔案是否損壞。
5.4版本之後有效的屬性:
*archiveDataLogs
當為true時,歸檔的消息檔案被移到directoryArchive,而不是直接删除
*directoryArchive
null
存儲被歸檔的消息檔案目錄
databaseLockedWaitDelay
在使用負載時,等待獲得檔案鎖的延遲時間,機關ms
maxAsyncJobs
等待寫入journal檔案的任務隊列的最大數量。應該大于或等于最大并發producer的數量。配合并行存儲轉發屬性使用。
concurrentStoreAndDispatchTopics
如果為true,轉發消息的時候同時送出事務
concurrentStoreAndDispatchQueues
如果為true,轉發Topic消息的時候同時存儲消息的message store中
5.6版本之後有效的屬性:
archiveCorruptedIndex
是否歸檔錯誤的索引到Archive檔案夾下
5.10版本之後有效的屬性:
IndexDirectory
單獨設定KahaDB中,db.data檔案的存儲位置。如果不進行設定,db.data檔案的存儲位置還是将以directory屬性設定的值為準
LevelDb是能夠處理十億級别規模Key-Value型資料持久性存儲的C++ 程式庫,由Google發起并開源。LevelDB隻能由本作業系統的其他程序調用,是以它不具有網絡性。如果您需要網絡上的遠端程序操作LevelDB,那麼就要自行封裝服務層。
LevelDB中的核心設計算法是跳躍表(Skip
List),核心操作政策是對磁盤上的資料日志結構進行歸并(LSM)。跳躍表實際上是二叉平衡樹的一種變形結構,它通過将一個有序連結清單進行“升維”操作,進而減少每一層上需要周遊的資料數量,達到快速查找的目的。下圖示意了一個跳躍表結構(在實際工作中,跳躍表的層級和“升維”政策的不同,跳躍表的結構也不一樣):
您可以将上圖中的每個元素節點,想象成每一條消息的key值。為了講解友善,上圖中我将擁有全部資料的元素的跳躍層稱為Level 2(最高層),但實際上規範的跳躍表結構中,擁有全部元素的層次稱為Level 0(最底層)。跳躍表的結構并非一成不變,當有一條新的記錄需要插入到結構時,可能會引起表中的多個Level都發生變化。
那麼LevelDB是如何應用跳躍表結構的?又是如何進行歸并操的?我們首先來看看LevelDB的簡要結構:
Log檔案
當LevelDB收到新的消息是會同步寫兩個地方:記憶體中的MemTable區域和磁盤上的Log檔案。直接寫Log檔案是為了在系統異常退出并重新開機時,能夠将LevelDB恢複到退出前的結構;那麼有的讀者會問,由于是直接寫磁盤會不會成為性能瓶頸呢?答案是,LevelDB的log檔案操作采用預占磁盤空間(預設為100MB),進行順序寫的方式。并且這個過程可以設定為異步的(當然如果設定成異步的,可能需要接受異常情況下資料丢失的風險)。
MemTable和Immutable
LevelDB還寫将消息寫入記憶體的MemTable區域,MemTable區域的的資料組織結構就是跳躍表(Skip
List),這樣的資料組織結構可以在讀取記憶體中資訊的時候,快速完成資訊定位。當MemTable區域的資料量達到indexWriteBufferSize屬性設定的大小時(預設為6MB),LevelDB就會把這個MemTable區域标記為Immutable,并開啟一個新的MemTable區域。一定注意,是标記為Immutable,而不是把MemTable區域的資料拷貝到某一個Immutable區域。
新标記的Immutable區域中的資料會被執行Compact操作,進而寫入到磁盤上的.sst檔案中。所謂Compact操作是指:LevelDB會剔除Immutable區域中那些已經被标示為“删除”的資料(成功消費的資料就會被标記為“删除”),排除那些格式錯誤的資料,并可能進行資料壓縮。
SSTable檔案
SSTable檔案是指存在于硬碟上,字尾名為.sst的檔案。這些檔案是LevelDB磁盤上最重要的資料記錄檔案,每一個SSTable檔案的預設大小為2MB,也就是說LevelDB的檔案夾下會有很多的.sst檔案。SSTable檔案并不是順序寫的,而是按照資料的key排序進行随機寫,是以SSTable檔案無需預占存儲磁盤存儲空間。
借鑒于跳躍表的設計思想,SSTable檔案也是分層次的。每一層可存儲的資料量是上一層的的10倍。舉個例子,第Level
2層可存儲的資料量80MB,那麼第Level
3層可存儲的資料量就是800MB。當某一層可存儲的資料量達到最大值,LevelDB就會從當層選取一個.sst檔案,向下層做Compact操作,由于來自于上層的新資料,是以下層的.sst檔案内容将産生變化(上文說過,.sst檔案中的内容是按照資料的key排序的)。
每一個SSTable檔案,由多個Block塊構成(預設大小為4KB),block塊是LevelDB讀寫磁盤上SSTable檔案的最小單元。每一個SSTable檔案最後一個Block塊稱為Index
Block,它指明了SSTable檔案中每一個Data block的起始位置。
但是每次讀取某個Block塊時,如果都在磁盤上先去找Index
Block,然後再根據其中記錄的index,找到Block在檔案的起始位置的話,查找效率顯然不高。是以LevelDB的記憶體區域中,有一個稱為Block
Cache的區域。這個區域存儲着衆多的Index Block,這樣就不需要到磁盤上查找Index Block了。
Manifest
那麼衆多的.sst檔案是如何被管理的呢?要知道如果在衆多.sst檔案中進行某條消息的查找時,如果将某一層的.sst檔案全部進行周遊,那麼性能肯定是不能接受的。在LevelDB中有一類檔案被稱為Manifest,這些Manifest檔案記錄了sst檔案的關鍵資訊,包括(但不限于):某個.sst檔案屬于哪一個Level、這個.sst檔案中最小的key值、這個.sst檔案中最大的key值。
在ActiveMQ中配置使用LevelDB作為持久化存儲方案實際上很簡單,使用主配置檔案中的persistenceAdapter标記就可以完成。最簡配置如下所示:
以上示例配置中,directory屬性表示LevelDB的結構檔案所放置的目錄位置。請注意,由于log檔案是順序寫的機制,是以log檔案也會預占磁盤空間,并且log檔案預設的大小就是100MB。那麼隻要生成一個log檔案,就至少會占據100MB的存儲空間(但這不代表總的已使用量)。也就是說,如果您将主配置檔案中storeUsage标記的limit屬性設定為200mb,那麼透過ActiveMQ管理界面看到的現象就是:隻要有任何一條PERSISTENT
Message被接受,Store percent
used立刻就會變成50%。如果您将storeUsage标記的limit屬性為100mb,那麼隻要有任何一條PERSISTENT
Message被接受,ActiveMQ服務端的Producer Flow Control政策就會立刻開始工作。
是以一定不要吝啬配置設定memoryUsage、storeUsage。依據您的團隊在生産環境下的存儲方案,也可以通過logSize屬性改變LevelDB中單個log檔案的大小。如下示例:
上一小節我們介紹到,預設的LevelDB存儲政策中,當ActiveMQ接收到一條消息後,就會同步将這條消息寫入到log檔案中,并且同時在記憶體區域向Memtable寫入位置索引。通過配置您也可以将這個過程改為“異步”:
以下清單展示了您可以使用的LevelDB的配置屬性,使用“*”辨別出來的屬性是筆者認為重要的配置項:
“LevelDB”
資料檔案的存儲目錄
sync
是否進行磁盤的同步寫操作
*logSize
104857600 (100 MB)
log日志檔案的最大值
verifyChecksums
是否對從檔案系統中讀取的資料進行強制校驗校驗
paranoidChecks
如果LevelDB檢測到資料錯誤,則盡快将錯誤在存儲位置進行标記
indexFactory
org.fusesource.leveldbjni.JniDBFactory, org.iq80.leveldb.impl.Iq80DBFactory
建立LevelDB時使用的工廠類,由于LevelDB的本質是C++程式庫,是以Java是通過Jni進行底層調用的
*indexMaxOpenFiles
可供索引使用的打開檔案的數量,這是因為Level内部使用了多線程進行檔案讀寫操作
indexWriteBufferSize
6291456 (6 MB)
記憶體MemTable的最大值,如果MemTable達到這個值,就會被标記為Immutable
indexBlockSize
4096 (4 K)
每個讀取到記憶體的SSTable——Index Block資料的大小
268435456 (256 MB)
使用一個記憶體區域記錄多個Level中,SSTable——Index Block資料,以便讀操作時,不經過周遊就可直接定位資料在某個level中的位置,建議增大該區域
indexCompression
snappy
适用于索引塊的壓縮類型,影響Compression政策
logCompression
none
适用于日志記錄的壓縮類型,影響Compression政策
從ActiveMQ
V4版本開始,ActiveMQ就支援使用關系型資料庫進行持久化存儲——通過JDBC實作的資料庫連接配接。可以支援的關系型資料庫包括(但不限于):Apache
Derby、DB2、HSQL、Informix、MySQL、Oracle、Postgresql、SQLServer、Sybase。
下面向各位讀者示範如何為ActiveMQ配置Mysql資料庫服務。前提是您已經某個網絡位置準備好了Mysql服務,并可以成功進行遠端登入。
在配置關系型資料庫作為ActiveMQ的持久化存儲方案時,要注意幾個事項:
配置資訊建議放置在您的jetty.xml配置檔案中,也可以放置在activemq.xml配置檔案中。除此之外,還要記得需要使用到的相關jar檔案放置到ActiveMQ安裝路徑下的./lib目錄。例如使用mysql
+ c3p0的配置中,需要的jar包至少包括:mysql-jdbc驅動的jar包和c3p0的jar包。
在jdbcPersistenceAdapter标簽中,我們設定了createTablesOnStartup屬性為true,這是為了在第一次啟動ActiveMQ時,ActiveMQ服務節點會自動建立所需要的資料表。啟動完成後,可以去掉這個屬性,或者更改createTablesOnStartup屬性為false。
在配置和測試的過程中,您可以會遇到這樣的問題:“java.lang.IllegalStateException:
BeanFactory not initialized or already
closed”這是因為您的作業系統的機器名中有“_”符号。更改機器名并且重新開機後,即可解決問題。
在同樣的硬體資源條件下,相比KahaDB和LevelDB這樣的“記憶體+存儲媒體”這樣的持久化方案而言,使用關系型資料庫作為ActiveMQ的持久化方案絕對不能說“性能”最好,但是在大多數情況下這個持久化方案也不會成為整個頂層架構的設計瓶頸(因為關系型資料庫一般都有自己的熱備和負載方案)。是以很多團隊還是會使用這樣的持久化方案,很大一部分原因就是這些團隊對關系型資料庫有更豐富的使用經驗,且有專門的資料庫管理人員。
以上我們介紹了三種持久化存儲方案:KahaDB、LevelDB、關系型資料庫。其中KahaDB和LevelDB的工作原理基本類似,都采用記憶體+磁盤媒體的方案:記憶體用于存放資訊的位置索引,磁盤媒體上存放消息内容。而關系型資料庫的方案,ActiveMQ将完全通過JDBC對資料庫進行操作完成消息的存儲和修改。
但是不是如網絡上一些資料所說的那樣,一定要對三種持久化存儲方案的速度做比較後,選擇最快的那種存儲方案呢?這裡面至少有兩個誤區:
某種存儲方案的速度一定比另一種存儲方案的速度快。
一定要選擇速度快的那種存儲方案。
下面我們進行詳細的讨論:
根據不同的硬體層配置,同一種持久化存儲方案的性能是完全不一樣的。例如在單節點計算的情況下,選用DDR
2133雙通道記憶體組和DDR3
1333單通道記憶體條從理論上至少就可以多獲得4Gbps的帶寬;選用同樣支援SATA3規範的機械硬碟和SSD固态硬碟,雖然兩者理論上的對外速度都标稱6Gbps,但是由于機械硬碟上單磁頭的讀寫速度存在瓶頸,是以就算進行連續讀操作,速度也隻能達到200MB/s左右;但是固态硬碟的連續讀速度卻可以達到500MB/s左右(基本已經接近6Gbps)。
如果是企業級硬體存儲方案,那麼速度差異還會繼續擴大。例如電信行業經常采用的IBM
各個系列磁盤陣列,一般都會配置諸如RAID5這樣的軟存儲方案。這樣一來,同一份檔案有多個副本,并且有多個磁頭負責讀寫。磁盤陣列的對外輸出一般會采用光纖通道(FC),而光纖通道行業協會(Fibre
Channel Industry Association)最新推出的(2015年實施)Gen
6第6代光纖通道标準中,設計的對外傳輸理論速度是128Gbps。
當然,除非您的公司/團隊能夠接受這些企業級存儲方案高昂的費用。否則還是建議在生産環境搭建成本效益較高的折中方案。例如采用20台左右PC Server搭建Ceph/MFS分布式存儲系統。這個方案,我們将在下一篇文章中進行詳細說明。
是以某種存儲方案的性能,除了這種存儲方案的工作原理以外對其有直接影響外,還要考慮它的工作環境。隻有根據軟體團隊預估的系統壓力、綜合建設方案、考慮後續擴容方式,來确定采用哪一種存儲方案,才是科學的。