資料庫分布式核心内容無非就是資料切分(Sharding)以及切分後對資料的定位、整合。資料切分就是将資料分散存儲到多個資料庫中,使得單一資料庫中的資料量變小,通過擴充主機的數量緩解單一資料庫的性能問題,進而達到提升資料庫操作性能的目的。
資料切分根據其切分類型,可以分為兩種方式:垂直(縱向)切分和水準(橫向)切分。
垂直切分常見有垂直分庫和垂直分表兩種。
1.1 垂直分庫 就是根據業務耦合性,将關聯度低的不同表存儲在不同的資料庫。做法與大系統拆分為多個小系統類似,按業務分類進行獨立劃分。與"微服務治理"的做法相似,每個微服務使用單獨的一個資料庫。如圖:
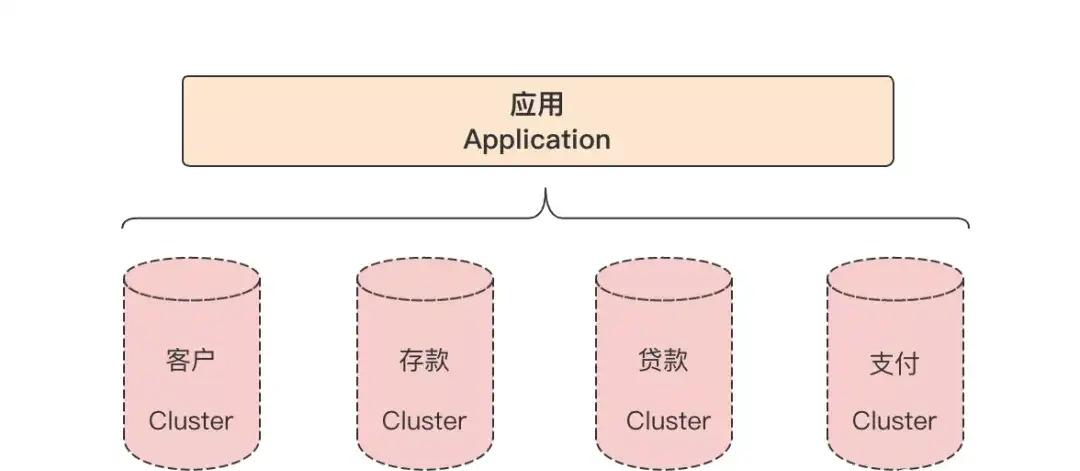
将不同子產品的資料表分庫存儲。子產品間不互相關聯查詢 如果有,就需要通過資料備援或者應層二次加工來解決。這種業務方法和資料結構最清晰。但若不能杜絕跨庫關聯查詢,宣告此路不同
1.2 垂直分表 是基于資料庫中的"列"進行,某個表字段較多,可以建立一張擴充表,将不經常用或字段長度較大的字段拆分出去到擴充表中。在字段很多的情況下(例如一個大表有100多個字段),通過"大表拆小表",更便于開發與維護,也能避免跨頁問題,MySQL底層是通過資料頁存儲的,一條記錄占用空間過大會導緻跨頁,造成額外的性能開銷。另外資料庫以行為機關将資料加載到記憶體中,這樣表中字段長度較短且通路頻率較高,記憶體能加載更多的資料,命中率更高,減少了磁盤IO,進而提升了資料庫性能。

解決業務系統層面的耦合,業務清晰
與微服務的治理類似,也能對不同業務的資料進行分級管理、維護、監控、擴充等
高并發場景下,垂直切分一定程度的提升IO、資料庫連接配接數、單機硬體資源的瓶頸
缺點:
部分表無法join,隻能通過接口聚合方式解決,提升了開發的複雜度
分布式事務處理複雜
依然存在單表資料量過大的問題(需要水準切分)
當一個應用難以再細粒度的垂直切分,或切分後資料量行數巨大,存在單庫讀寫、存儲性能瓶頸,這時候就需要進行水準切分了。
水準切分分為庫内分表和分庫分表,是根據表内資料内在的邏輯關系,将同一個表按不同的條件分散到多個資料庫或多個表中,每個表中隻包含一部分資料,進而使得單個表的資料量變小,達到分布式的效果。如圖所示:
相對縱向切分這一将表分類的做法,此法是按表内每個字段的某個規則來将資料分散存儲于不同的資料庫(或不同的表),也就是按照數行來進行切分資料。
水準切分的優點:
不存在單庫資料量過大、高并發的性能瓶頸,提升系統穩定性和負載能力
應用端改造較小,不需要拆分業務子產品
跨分片的事務一緻性難以保證
跨庫的join關聯查詢性能較差
資料多次擴充難度和維護量極大
水準切分後同一張表會出現在多個資料庫/表中,每個庫/表的内容不同。幾種典型的資料分片規則為:
按照時間區間或ID區間來切分。例如:按日期将不同月甚至是日的資料分散到不同的庫中;将userId為1~9999的記錄分到第一個庫,10000~20000的分到第二個庫,以此類推。某種意義上,某些系統中使用的"冷熱資料分離",将一些使用較少的曆史資料遷移到其他庫中,業務功能上隻提供熱點資料的查詢,也是類似的實踐。
這樣的優點在于:
單表大小可控
天然便于水準擴充,後期如果想對整個分片叢集擴容時,隻需要添加節點即可,無需對其他分片的資料進行遷移
使用分片字段進行範圍查找時,連續分片可快速定位分片進行快速查詢,有效避免跨分片查詢的問題。
熱點資料成為性能瓶頸。連續分片可能存在資料熱點,例如按時間字段分片,有些分片存儲最近時間段内的資料,可能會被頻繁的讀寫,而有些分片存儲的曆史資料,則很少被查詢
一般采用hash取模mod的切分方式,例如:将 Customer 表根據 cusno 字段切分到4個庫中,餘數為0的放到第一個庫,餘數為1的放到第二個庫,以此類推。這樣同一個使用者的資料會分散到同一個庫中,如果查詢條件帶有cusno字段,則可明确定位到相應庫去查詢。
優點:
資料分片相對比較均勻,不容易出現熱點和并發通路的瓶頸
後期分片叢集擴容時,需要遷移舊的資料(使用一緻性hash算法能較好的避免這個問題)
容易面臨跨分片查詢的複雜問題。比如上例中,如果頻繁用到的查詢條件中不帶cusno時,将會導緻無法定位資料庫,進而需要同時向4個庫發起查詢,再在記憶體中合并資料,取最小集傳回給應用,分庫反而成為拖累
技術人具備“結構化思維”意味着什麼?
Gradle 比 Maven 好為什麼用的人少?
Kafka 提供哪些日志清理政策?
為什麼ConcurrentHashMap的讀操作不需要加鎖?
Kafka 是怎麼存儲的?為什麼速度那麼快?