1.Spark Graph簡介
GraphX 是 Spark 一個元件,專門用來表示圖以及進行圖的并行計算。GraphX 通過重新定義了圖的抽象概念來拓展了 RDD: 定向多圖,其屬性附加到每個頂點和邊。為了支援圖計算, GraphX 公開了一系列基本運算符(比如:mapVertices、mapEdges、subgraph)以及優化後的 Pregel API 變種。此外,還包含越來越多的圖算法和建構器,以簡化圖形分析任務。GraphX在圖頂點資訊和邊資訊存儲上做了優化,使得圖計算架構性能相對于原生RDD實作得以較大提升,接近或到達 GraphLab 等專業圖計算平台的性能。GraphX最大的貢獻是,在Spark之上提供一棧式資料解決方案,可以友善且高效地完成圖計算的一整套流水作業。
圖計算的模式:
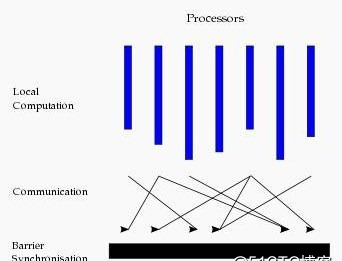
基本圖計算是基于BSP的模式,BSP即整體同步并行,它将計算分成一系列超步的疊代。從縱向上看,它是一個串行模式,而從橫向上看,它是一個并行的模式,每兩個超步之間設定一個栅欄(barrier),即整體同步點,确定所有并行的計算都完成後再啟動下一輪超步。
每一個超步包含三部分内容:
計算compute:每一個processor利用上一個超步傳過來的消息和本地的資料進行本地計算
消息傳遞:每一個processor計算完畢後,将消息傳遞個與之關聯的其它processors
整體同步點:用于整體同步,确定所有的計算和消息傳遞都進行完畢後,進入下一個超步
2.來看一個例子
圖描述
計算所有的頂點,所有的邊,所有的triplets,頂點數,邊數,頂點距離大于1000的有那幾個,按頂點的距離排序,降序輸出
代碼實作
輸出結果
3.圖的一些相關知識
例子是demo級别的,實際生産環境下,如果使用到必然比這個複雜很多,但是總的來說,一定場景才會使用到吧,要注意圖計算情況下,要注意緩存資料,RDD預設不存儲于記憶體中,是以可以盡量使用顯示緩存,疊代計算中,為了獲得最佳性能,也可能需要取消緩存。預設情況下,緩存的RDD和圖儲存在記憶體中,直到記憶體壓力迫使它們按照LRU【最近最少使用頁面交換算法】逐漸從記憶體中移除。對于疊代計算,先前的中間結果将填滿記憶體。經過它們最終被移除記憶體,但存儲在記憶體中的不必要資料将減慢垃圾回收速度。是以,一旦不再需要中間結果,取消緩存中間結果将更加有效。這涉及在每次疊代中實作緩存圖或RDD,取消緩存其他所有資料集,并僅在以後的疊代中使用實作的資料集。但是,由于圖是有多個RDD組成的,是以很難正确地取消持久化。對于疊代計算,建議使用Pregel API,它可以正确地保留中間結果。
吳邪,小三爺,混迹于背景,大資料,人工智能領域的小菜鳥。