<b>摘要:</b>MXNet是深度學習領域的主流架構之一,本文從特點,架構及程式設計模式等方面展開了對MXNet的全面介紹。解答如何在阿裡雲上快速部署和運作MXNet,以及介紹了阿裡雲上的MXNet一些性能實踐。
<b>演講嘉賓簡介:</b>
謝峰(撷峰),阿裡雲異構計算技術專家。有豐富的X86、ARM、GPU虛拟化技術經驗,加入阿裡雲之前,曾作為主要開發者參與基于API Remoting方案的GPU虛拟化項目,并負責基于Xen的NVIDIA vGPU虛拟化技術的引入和産品落地,并對智能手機虛拟化技術有深入研究。目前從事阿裡雲GPU異構計算基礎設施的研發以及GPU在深度學習等領域的應用研究和性能調優等工作。
以下内容根據演講嘉賓視訊分享以及PPT整理而成。
本次的分享主要圍繞以下三個方面:
一、MXNet 簡介
二、阿裡雲上部署和運作MXNet
三、阿裡雲上的MXNet性能實踐
<b>一、MXNet 簡介</b>
<b>1.MXNet特點</b>
MXNet是一個全功能,靈活可程式設計和高擴充性的深度學習架構。所謂深度學習,顧名思義,就是使用深度神經網絡進行的機器學習。神經網絡本質上是一門語言,我們通過它可以描述應用問題的了解。比如,卷積神經網絡(CNN)可以表達空間相關性的問題,使用循環神經網絡(RNN)可以表達時間連續性方面的問題。MXNet支援深度學習模型中的最先進技術,當然包括卷積神經網絡(CNN),循環神經網絡(RNN)中比較有代表性的長期短期記憶網絡(LSTM)。根據問題的複雜性和資訊如何從輸入到輸出一步一步提取,我們通過将不同大小,不同層按照一定的原則連接配接起來,最終形成完整的深層的神經網絡。MXNet有三個特點,便攜(Portable),高效(Efficient),擴充性(Scalable)。
首先看第一個特點,便攜(Portable)指友善攜帶,輕便以及可移植。MXNet支援豐富的程式設計語言,如常用的C++,python,Matlab,Julia,JavaScript,Go等等。同時支援各種各樣不同的作業系統版本,MXNet可以實作跨平台的移植,支援的平台包括Linux,Windows,IOS和Android等等。
第二點,高效(Efficient)指的是MXNet對于資源利用的效率。而資源利用效率中很重要的一點是記憶體,因為在實際的運算當中,記憶體通常是一個非常重要的瓶頸,尤其對于GPU,嵌入式裝置而言,記憶體顯得更為寶貴。神經網絡通常需要大量的臨時空間,例如每層的輸入,輸出變量,每個變量需要獨立的記憶體空間,這回帶來高額度的記憶體開銷。如何優化記憶體開銷,對于深度學習架構而言是非常重要的事情。MXNet在這方面做了特别的優化,有資料表明,在運作多達1000層的深層神經網絡任務時,MXNet隻需要消耗4GB的記憶體。阿裡也與Caffe做過類似的比較之後也驗證了這項特點。
第三點,擴充性(Scalable)在深度學習當中一個非常重要的性能名額。更高效的擴充可以讓訓練新模型的速度得到顯著提高,或者在相同的時間内,大幅度提高模型複雜性。擴充性指兩方面,首先是單機擴充性,另一個是多機擴充性。MXNet在單機擴充性和多機擴充性方面都有非常優秀的表現。是以擴充性(Scalable)是MXNet最大的一項優勢,也是最突出的特點。
<b>2.MXNet程式設計模式</b>
對于一個優秀的深度學習系統,或者一個優秀的科學計算系統,最重要的是如何設計程式設計接口,它們都采用一個特定領域的語言,并将其嵌入到主語言當中。比如numpy将矩陣運算嵌入到python當中。嵌入一般分為兩種,其中一種嵌入較淺,每種語言按照原來的意思去執行,叫指令式程式設計,比如numpy和Torch都屬于淺深入,指令式程式設計。另一種則是使用更深的嵌入方式,提供了一整套針對具體應用的迷你語言,通常稱為聲明式程式設計。使用者隻需要聲明做什麼,具體執行交給系統去完成。這類程式設計模式包括Caffe,Theano和TensorFlow等。
目前現有的系統大部分都采用上圖所示兩種程式設計模式的一種,兩種程式設計模式各有優缺點。是以MXNet嘗試将兩種模式無縫的結合起來。在指令式程式設計上MXNet提供張量運算,而聲明式程式設計中MXNet支援符号表達式。使用者可以自由的混合它們來快速實作自己的想法。例如我們可以用聲明式程式設計來描述神經網絡,并利用系統提供的自動求導來訓練模型。另一方面,模型的疊代訓練和更新模型法則中可能涉及大量的控制邏輯,是以我們可以用指令式程式設計來實作。同時我們用它來進行友善地調式和與主語言互動資料。
<b>3.MXNet架構</b>
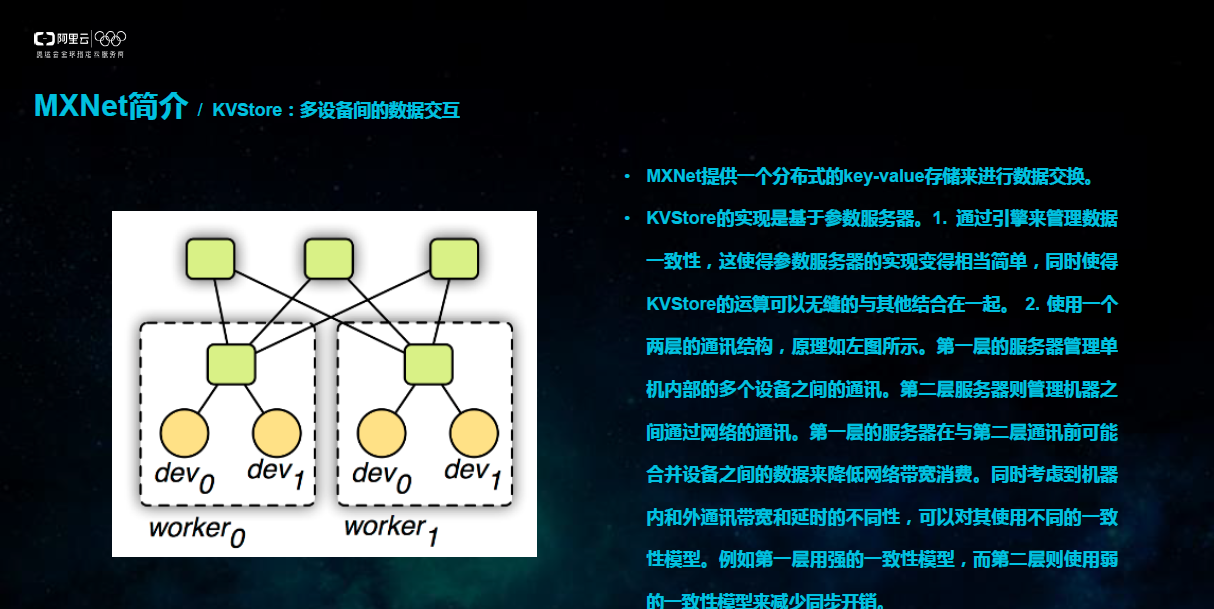
下圖中左邊是MXNet架構圖,從上到下是分别為各種主從語言的嵌入,程式設計接口(矩陣運算NDArray,符号表達式Symbolic Expression,分布式通訊KVStore),還有兩種程式設計模式的統一系統實作,其中包括依賴引擎,還有用于資料通信的通信接口,以及CPU,GPU等各硬體的支援,還有對Android,IOS等多種作業系統跨平台支援。在三種主要程式設計接口(矩陣運算NDArray,符号表達式Symbolic Expression,分布式通訊KVStore)中,重點介紹KVStore.
KVStore是MXNet提供的一個分布式的key-value存儲,用來進行資料交換。KVStore的本質上的實作是基于參數伺服器。1.通過引擎來管理資料一緻性,這使得參數伺服器的實作變得相當簡單,同時使得KVStore的運算可以無縫的與其他部分結合在一起。2.使用一個兩層的通訊結構,原理如下圖所示。第一層的伺服器管理單機内部的多個裝置之間的通訊。第二層伺服器則管理機器之間通過網絡的通訊。第一層的伺服器在與第二層通訊前可能合并裝置之間的資料來降低網絡帶寬消費。同時考慮到機器内和外通訊帶寬和延時的不同性,可以對其使用不同的一緻性模型。例如第一層用強的一緻性模型,而第二層則使用弱的一緻性模型來減少同步開銷。在第三部分會介紹KVStore對于實際通訊性能的影響。
<b></b>
<b>二、阿裡雲上部署和運作MXNet</b>
<b>1.阿裡雲提供的彈性GPU服務</b>
深度學習的發展依賴于三個重要的要素。第一,算法的大幅改進;第二個是大資料的提供;第三個是算力的大幅提升。其中GPU的性能大幅度提升是對算力的巨大貢獻。阿裡雲提供的彈性GPU計算計算服務,提供了豐富的GPU執行個體、軟體(鏡像市場)和服務(如容器服務)來給客戶。
1)GPU執行個體支援M40、P4、P100、V100多種GPU,和豐富的CPU、記憶體配置,覆寫深度學習訓練和推理場景。
2)鏡像市場提供了預裝NVIDIA GPU 驅動和CUDA 庫的鏡像,以及預裝開源深度學習架構(包括MXNet)的鏡像。
3)提供容器服務一鍵部署、運作深度學習任務,提供ROS資源編排服務建立需要的GPU執行個體資源等等。

阿裡雲的容器服務可以提供分布式的運算模型,并且可以利用阿裡雲豐富的存儲資源,如使用高效雲盤或者SSD雲盤,OSS對象存儲,可以使用NAS檔案存儲來存儲使用者訓練資料。
阿裡雲可以基于容器,實作彈性GPU服務一鍵式部署,包括支援GPU資源排程,挂載共享存儲,負載均衡,彈性伸縮,CPU、GPU監控以及豐富的日志管理。
基于容器的工作方式相對于很多傳統的方式有非常多巨大便利。我們需要搭建深度學習環境,對資料做準備,對模型進行開發,然後對開發的模型進行訓練和預測。而傳統的部署過程全部都需要手動完成,這是極其複雜的過程。利用容器的一鍵式部署可以極大縮短部署時間
<b>2.使用容器服務部署MXNet</b>
下面是使用容器服務部署MXNet的過程。首先可以在阿裡雲控制台上找到容器服務解決方案,如下圖所示。在當中選擇機器學習,可以看到支援模型開發,模型訓練及模型預測。選擇建立資料卷,可以選擇OSS,NAS雲盤等多種不同的儲存設備,之後将訓練資料放到儲存設備上;可以選擇模型開發,并且建立一個GPU叢集,選擇需要的訓練架構,GPU資料,資料來源。資料來源可以是主機目錄,或者是之前建立的資料源。之後便可以部署MXNet架構任務,部署過程是非常友善的。
<b>3.基于Docker使用NVIDIA GPU CLOUD部署</b>
我們還可以使用開源Docker部署NVIDIA GPU CLOUD鏡像。NVIDIA GPU CLOUD實際上是一個開放的深度學習的容器鏡像的倉庫。我們可以通過安裝最新的Docker,以及安裝nvidia-docker的插件,之後注冊NGC,pull最新的MXNet容器鏡像。在MXNet容器鏡像當中,NVIDIA裝了最新的CUDA Driver,最新的深度學習加速庫cuDNN,以及多GPU加速庫NCCL等。是以我們可以使用已經優化好的整套軟體來部署到系統之上。
<b>4.一個簡單MXNet單機訓練任務的運作例子</b>
1)選擇一個單機圖像分類模型的訓練作為示例
2)選擇CNN網絡Inception-v3,選擇Imagenet資料集
3)Github下載下傳最新的MXNet源碼,并且在Example中找到圖像分類
4) 并執行指令,運作train_imagenet.py(這是一個性能benchmark):python train_imagenet.py --benchmark1 --gpus 0 --network inception-v3 --batch-size 64 --image-shape 3,299,299 --num -epochs 1 --kv-store local
運作效果如下圖中所示,我們可以發現運作之後螢幕會實時列印出目前運作的性能及精度,性能機關:每秒處理的圖像張數。
<b>三、阿裡雲上的MXNet性能實踐 </b>
<b>1.阿裡雲GPU伺服器MXNet性能資料</b>
首先來看單GPU性能資料,選擇Inception-V3網絡,用MXNet在ImageNet資料集上做圖像分類模型訓練的Benchmark性能測試。從下圖中的測試資料來看,我們發現搭載V100的GN6執行個體因為使用TensorCore混合精度,性能接近搭載P100的GN5執行個體的3倍。可以看到由于NVIDIA每年在GPU硬體上的性能巨大的提升,使得在GPU上運作深度學習的速度大幅度提升。
之後看單機多GPU性能資料,使用GN5(P100)8卡執行個體,同樣測試了MXNet的圖像分類模型訓練的單機擴充性。從下圖中發現AlexNet,GoogleNet,Inception-V3和ResNet152等四種經典的卷積神經網絡測試當中,單機多卡接近線性加速。這證明了MXNet在單機的擴充性上的确非常優秀。
<b>2.KVStore政策對性能的影響</b>
在第一部分有提到KVStore是MXNet資料通訊的子產品。KVStore政策對最終性能有巨大影響。深度學習過程有兩部分組成,前向和後向。前向指的是通過正向運算取得結果,然後利用損失函數,計算結果與基準結果的偏差,再對偏差進行反向求導,計算偏差減小的最大梯度方向,在最大梯度方向減少偏差進而更新新的權值,再利用新的權值運算新的結果。不斷反複疊代運算,最終結果會無限逼近最終想要達到的基準結果。那麼在疊代運算的過程當中,會涉及到兩個主要資料流向。并行計算當中,會有很多的裝置。以GPU為例,就是有很多GPU worker,每個workers計算完自己的梯度之後要彙集到一起合成完整梯度,是以會有梯度聚合的梯度流向。第二個資料流向,計算完梯度後,在梯度反向對網絡權值進行更新,之後更新後的權值會更新到每個GPU worker上。
KVStore的不同參數主要是兩個不同資料流向的選擇,目前的KVStore可以支援local和device兩種參數,在1.0版本之後,新增了nccl參數。
1)local:所有的梯度都拷貝到CPU記憶體完成聚合,同時在CPU記憶體上完成權值的更新并拷貝回每個GPUworker。這種方式主要在于CPU與GPU,主要的性能負載在于CPU拷貝的負載。
2)device:梯度聚合和權值更新都在GPU上完成。GPU之間的如果支援Peer to Peer通信(PCIe or NVLink),将避免CPU拷貝的負載,可以大大減輕CPU的負擔,僅受限于通信帶寬。PCIe 與NVLink通信帶寬不同,NVLink具備告訴的Peer to Peer通信帶寬
3)ccl:1.0版本後新增,類似于device,利用NVIDIA的NCCL通信庫,相比device,會有潛在的性能提升(尤其是針對NVLink有特别優化),但是NCCL本身會消耗GPU資源,是以往往GPU數量較多時效果明顯,目前MXNet對NCCL的支援還屬于實驗版本,在PCIe上的效果并不好。從下圖資料來看,對于Inception-V3網絡來說,使用local參數性能最優,使用device較差,nccl最差。當然因為nccl對于NVLink有特别優化,後續阿裡雲上會推出最新NVLink版本的V100的執行個體。可以期待在新的裝置之上,會有更優的表現。
<b>3.分布式通信性能</b>
前面提到的都是單機通信,主要取決于通信基礎設施,比如PCle和NVLink帶寬。在多機通信中性能主要瓶頸在于網絡通信。普通的我們使用的以太網因為通信延遲的原因,會大大影響多機擴充性。從下圖中可以看到,InfiniBand(IB)網絡和RoCE網絡因為支援RDMA,大大降低了通信延遲,相比之下,20G的以太網格延遲會大大提升。為了改善延遲,阿裡雲超級計算機叢集使用InfiniBand或者RoCE網絡,支援GPURDMA,可以大大降低延遲,增加多機擴充性。
當然,對于現有的普通以太網絡,也可以通過别的方法優化通信帶寬的減少,比方說梯度壓縮。通過梯度壓縮,減少通信帶寬消耗的同時,保證收斂速度和精度不會有明顯下降。MXNet官方提供了梯度壓縮算法,按照官方資料,最佳的時候可以達到兩倍的訓練速度提升,同時收斂速度和精度的下降不會超過百分之一。
本文由雲栖志願小組董黎明整理,編輯百見