<b>摘要:</b>随着十二點的鐘聲響起,無數人盯着購物車開啟了一年一度的“剁手”之旅。可你有沒有想過這購物狂歡的背後是什麼支撐起了資料規模如此龐大的計算任務?其實不隻是“雙十一”,每一個使用者的點選和浏覽,每一件寶貝的排序和推薦,還有貼心的“猜你喜歡”,在這背後“操控”一切的“手”又是什麼?本文将帶領大家一探究竟。
<b>演講嘉賓簡介:</b>
<b>範朝盛(花名:朝聖),</b>阿裡巴巴搜尋事業部算法專家,北京大學數學與計算機科學博士,2016年加入阿裡巴巴,現主要從事推薦系統特征、模型、架構和大規模機器學習架構的研發工作。
<b>以下内容根據演講嘉賓視訊分享以及PPT整理而成。</b>
本次分享的主要圍繞以下三個方面:
一.業務背景
二.XPS機器學習平台
三.XNN深度學習算法
<b>一.業務背景</b>
<b></b>
<b>·業務場景和機器學習的問題</b>
業務場景主要包括三個方面:
(1) 搜尋:比如使用者在淘寶中輸入檢索詞,網站則會展示出相應寶貝資訊的場景。
(2)廣告:包括搜尋廣告,精準定向廣告和品牌廣告等場景。
(3)推薦:将淘寶用戶端網頁從上到下滑動,其中很多場景均為推薦子場景。
在這些業務場景中蘊含着各種各樣的問題,從技術的角度看,主要的三類問題是經典的資料挖掘問題、圖像問題(低品質圖像的識别、圖像的分類)和語義問題(NLP問題,例如研究檢索詞和寶貝的标題表示)。從上面的簡單介紹中可以看出,阿裡團隊的業務場景較為複雜,而機器學習在處理這些問題的過程中所扮演的角色是十分重要的。
對于機器學習,需要模組化的問題主要有如下幾種:
(1)點選率預估:使用者曝光,點選寶貝後預估點選率,淘寶所特有的收藏率預估和加入購物車的機率預估,同時還會預估使用者點選一個寶貝之後進行購買的轉化行為機率的預估。
(2)點選品質好壞的預估,這對于為使用者推薦商品操作極為重要。
(3)相關性預估:相關性指的是使用者所觸達的商品與使用者真正相關的可能性,比如使用者可能會點選推薦的熱門商品,但這種商品與使用者之間的相關性系數并不高。
這些問題的解決都需要從使用者行為資料擷取樣本,阿裡團隊會收集使用者日志,然後從中提取機器學習所需要的特征,并且加入相應的标簽,例如點選、收藏、加入購物車等。使用者行為轉化都是比較直覺的,而對于點選品質的好壞,則可以定義使用者停留小于一定的時間屬于一個bad case ,超過一定的時間屬于一個good case,如此來定制标簽。
<b>·面臨的挑戰及解決方法</b>
有了使用者資料之後,接下來看一下機器學習過程中可能要面臨的挑戰。淘寶的機器學習模型要面臨的挑戰主要有三種:
(1)樣本多:在搜尋領域已經可以達到每天幾百億的樣本規模,而在推薦領域比如首頁底部的“猜你喜歡”子產品的樣本也能夠達到百億規模。每天百億規模,三個月就可以達到萬億規模,這樣龐大的樣本數量十分難能可貴,同樣也具有很大的挑戰性,阿裡團隊就需要設計專用的機器學習平台來處了解決此類問題。
(2)特征多:特征多主要表現在如下幾個方面。首先特征的屬性非常繁雜,種類多,總量大。整個淘寶網購平台上有幾億的使用者和十幾億的産品,而使用者的檢索詞也是各種各樣,非常豐富;淘寶每天還會産生幾百億甚至上千億的使用者行為;而對于使用者屬性,阿裡團隊為使用者繪制了非常詳細的使用者畫像,是以每個使用者的屬性十分豐富,與此相同,寶貝的屬性也很多。同時,阿裡團隊通過阿裡基礎特征服務(ABFS)的架構引入了更多的特征,該架構大規模地引入了使用者側的實時特征統計和産品側實時特征統計。例如使用者最近點選的一系列的寶貝(可能會有上百個),使用者三天、五天、七天的點選率的統計,産品的點選率與轉化率和該産品在兩個小時内被不同類型的人群購買的分布等等。ABFS同時還引入了使用者在翻頁時上下文的一些特征,例如使用者翻頁到第三頁時可以将第二頁的資訊可以實時地推送給使用者,有助于在模組化時作為上下文(context)特征來使用。此外,在ABFS中還建立了圖像和語義的表示向量,每一張圖檔可以被形成一個向量,每個标題(title)詞和搜尋(query)詞也會形成一個向量,然後加入到機器學習的訓練集之中,是以綜合來看,在基礎屬性已經非常龐大的基礎上,阿裡基礎特征服務又提供了更多的特征資訊,這些特征經過适當的特征組合之後,總量很輕易地就能夠達到萬億規模,而處理如此規模的訓練資料是一個非常迷人的問題,同時也需要很多特别的設計來友善進行訓練。
(3)計算和存儲資源有限:在有限的資源條件下如何發揮最大效益和充分協調如此多的任務也是阿裡機器學習團隊面臨的主要挑戰之一。
為了應對這些挑戰,阿裡團隊建立了一個機器學習的平台XPS(eXtreme Parameter Server)。該平台實作了流式學習算法選型,即在XPS平台上樣本隻會經過一次訓練而不會反複,因為萬億規模的樣本不可能全部加載到記憶體中進行訓練,是以采用了這種方式。阿裡團隊還會盡量在XPS平台上開發一些創新型的算法,例如xftrl、xltr、xsvd和xnn等,同時也更鼓勵一些在此平台上工作的技術人員去開發一些微創新的算法,讓XPS平台成為一個專用的大規模機器學習的開發平台,使其具有自己的特色。在XPS平台的命名中選取了eXtreme這個詞,蘊含的寓意是追求極緻的訓練性能和線上效果,這也是阿裡團隊的理想和目标,如今團隊正向着這個目标奮力前進。想要了解整個XPS平台系統的讀者可以閱讀下面這篇文章自我學習:《扛過雙11的千億級特征分布式機器學習平台XPS》,文章的連結:https://mp.weixin.qq.com/s/TFTf1-x4s35iebiOEMXURQ 這篇文章對XPS系統作了更加詳細完整的介紹。
<b>二. XPS機器學習平台</b>
這一部分将為大家簡要介紹XPS機器學習平台的整體結構和工程特點。
<b>1.整體結構</b>
首先介紹一下Parameter Server結構,它包括三個部分,分别是Server、Coordinator和Worker,如下圖所示:
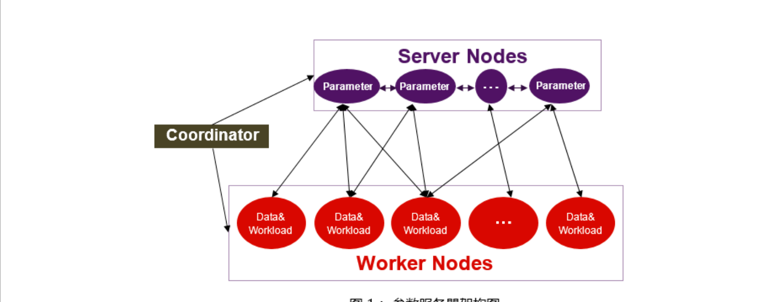
其中Coordinator主要用做中心排程控制,完成Server和Worker的分組,當出現failover的情況時,coordinator可以對failover進行恢複;Worker主要是讀取資料,計算梯度并且将其發送給server,是比較獨立的一個部分,但Worker不僅計算梯度,有時候還會發送一些特征的曝光點集到Server上進行更新;Server主要用于存儲和更新模型參數,其上存儲了整個需要用作線上預估的模型的所有參數以及這些參數的附加資訊,比如梯度、曆史梯度、版本資訊和每個特征的曝光點等等這些資訊都是存儲在Server上的。
當我們在做ps設計時,一個優雅的ps設計能夠讓使用者像單機程式設計一樣快速開發分布式程式,這樣做的好處是使用者隻需要面對Worker來進行程式設計,而Server和Coordinator的功能盡量對使用者屏蔽。XPS的架構設計使得使用者隻需要關心Worker上的損失函數和怎樣計算參數的梯度,而對于Server和Coordinator很少涉及,進而友善使用者快速地實作大規模的機器學習的算法。
接下來便進入正題,首先介紹一下XPS的結構圖,如下圖所示:

從圖中可以看出,XPS的底層資料存儲用到了MaxCompute,同時還包括Streaming DataHub和Kafka這樣的實時資料流;在排程和計算資源層,XPS系統包含了飛天叢集排程和CPU與GPU這些資源的控制,在此之上第三層是XPS整個平台;在XPS平台之上是一些對外的算法接口,例如現在提供的XNN、XFTRL、XSVD、XGBOOST和FM等一些算法;最上層的是業務方,業務方可以通過在ODPS中直接調用算法接口,就可以拉起XPS系統。
在MaxCompute叢集上,XPS系統可以高效的利用巨大規模的計算資源和存儲資源。同時XPS系統會推薦使用者搭建近線的流式學習平台。平台采用近線的流式學習模式,即盡量選擇讓曝光流等待點選流完成之後再産出訓練資料。例如使用者可以設定在其應用場景内使用者曝光之後5分鐘或者15分鐘之内點選都算點選,如此可以保證曝光和點選糾正出來的樣本是穩定的。XPS系統同樣支援實時學習模式,通過Streaming DataHub和Kafka來引入實時學習的模式,但在實際應用中基于穩定性的原因,使用更多的則是近線的流式學習模式;而在強化學習這樣的業務場景下,更多的會采用實時學習模式。
看到這裡,讀者可能會好奇XPS系統的性能表現如何。下面就列舉一些參數來讓大家直覺的看到XPS系統的性能高低:首先XPS系統的通信性能要比MPI通信提升數倍,原因在于XPS系統的底層設計相比于MPI系統更為優良。另外XPS系統的Server數能夠橫向擴充到800個,而每個Server有40G的記憶體,并且在此規模下仍然保持良好的收斂性。有經驗的讀者會知道,目前一般的平台當Server和worker數過多時會帶來一些異步性損失的問題,進而導緻模型收斂效果差,甚至不收斂。針對此問題,我們設計了一套解決異步損失的方案,進而使得worker和server線性擴充。目前XPS平台可以在7小時内運作完一個百億規模的DNN模型,這在目前來說是一個比較快的速度。
接下來介紹一下XPS系統的整個資料流轉過程:首先通過一個線上的曝光點選日志結合ABFS産生的Session Server的實時使用者特征,同時結合Item的實時特征,産出整個資料流,然後傳給ABFS進行資料生産和特征加工。ABFS會把一條資料變成一條特征,然後傳送給XPS模型訓練平台進行模型訓練。在訓練時,我們引入了一個Test Future的機制,能在訓練的時候把握一個模型的品質,當模型健康的時候将其推送到線上進行部署。而線上采用的是分布式部署,模型部署完畢之後還會進行打分,打分的同時當一些新的請求發送過來時,我們同時把使用者的實時特征、曝光點選日志和Item的特征列印到日志中去,然後形成一個如下圖所示的循環。整個循環是比較強調“換血”的過程的,即預估時的樣本狀态也就是再次需要訓練的時候的樣本狀态。
<b>2.工程特點</b>
阿裡團隊對XPS系統底層做了很多各種各樣的優化,進而使其擁有更好的性能。
(1)首先介紹的是一個多級分區增量訓練的機制,即在MaxCompute中的資料存儲可以分為分鐘、小時和天三個級别,這使得使用者在進行模型訓練時可以動态地選擇分區來進行增量級别的訓練。舉個例子,假如一個使用者訓練一個任務需要三個月的時間,那麼使用者可以選擇使用天級别的資料分區快速運作完資料,然後部署到線上之後可以選擇采用小時級别的訓練流程,使其每個小時産出一個增量的模型來進行部署。當使用者的任務需要緊急調控的時候,可以适當地選擇分鐘級别的更新來使模型具有更好地實時性。由此看來XPS整個平台的資料采用了多級分區增量訓練,它具有良好的靈活性,且可以通過簡單的配置去除不達标的“髒資料”。
(2)第二個特點是流式評估模式(Test-Future-Data),這種評估模式十分有趣。首先介紹一下流式評估模式的概念,可以拿它與經典的靜态測試來做個比較。傳統的靜态測試分為兩種,第一種測試方式會采樣一定比例的資料例如20%作為測試資料,測試的是模型分布已知的情況下的資料狀況,該測試方式缺陷明顯,目前測試的結果并不能很好的反應和預估未來的測試狀況。第二種靜态測試的方式則是Test-LastDay-Data,該方式會訓練N-1天,然後測試第N天,該方式的缺點在于使用者同時調整多個模型時必須使訓練資料完全固定下來,然後把最後一天當作測試,每次疊代資料都要等待整個過程運作完進行測試。而流式評估模式就是在靜态測試的基礎上進行了一定的擴充,以動态測試為出發點,在“未來”的資料流上評估整個模型的品質。該評估模式會在訓練過程中不斷地提取未來的Minibatch作為測試集進行測試。一個簡單的例子是假設有N個Minibatch,現在已經訓練到第M個,此時可以指定第M+1個到第M+10個Minibatch作為一個小測試集來測試整個模型品質。該測試模式的好處是可以實時反映模型的品質,當模型資料出現問題時,通過準度等名額可以快速發現問題,進而幫助使用者快速調整參數。并且當使用者突然發現收斂的模型線上上服務出現問題時,可以通過檢視模型的動态AUC來發現奇異的任務。流式評估模式已經被XPS平台使用者所熟知和采納,由于流式測試模式可以使使用者實時并行調控多個模型,是以現在的使用者已經習慣于采用這種友善高效的動态測試模式進行測試,而不是用傳統的靜态測試。
讀到這裡可能部分讀者對流式評估模式過程的了解仍舊模糊,下面就通過一個直覺圖來展示一下流式評估的過程:
對于T-1時刻的模型,基于流式評估會計算其在T到T+N時刻的資料流的評價名額。這些評價名額包括AUC、PCOPC、MAE和RMSE,其中PCOPC是指整個場景的預估準确率和真實準确率的比值,它代表了機器學習任務的偏度。例如點選率為0.5,若預估值為0.6,則預估偏高;相反,若預估值為0.4,則預估偏低。在訓練時,使用者通過PCOPC名額可以發現之前的一些算法的預估值偏度存在一定的問題,而在流式評估模式下,使用者可以在調參的時候很快地發現這些問題。與此同時,流式評估模式會統計諸如正樣本數、負樣本數和模型規模等名額,進而幫助使用者在整個學習過程中可以友善地進行模型的裁剪以及整個場景中樣本的監控。
(3)XPS系統的第三個底層優化是通信優化,這也是整個XPS系統中最重要的優化。
<b>※</b>小包的問題的優化。
首先介紹一下小包問題,在整個XPS系統中,Worker和Server之間存在非常多的小包互動,每次通信的資訊量在1到2 MB之間,如果Server的數量有100個左右,那麼配置設定到每個Server上的參數key分片的大小可以達到1到10 KB的規模。對于通信頻率的問題,假設每個Worker上有四五個資料結構的話,每次的pull和push為兩次通信,那麼每個Worker上的通信次數就可以達到8到10次,即每個batch有2到10次通信,這樣的通信頻率是非常高的。這就涉及到一個延遲敏感的問題,在計算和通信的性能占比中要盡量降低通信所占的比例,單次通信要控制在毫秒級,防止拉低整個叢集的效率,進而把更多的性能投入到計算當中去。
對于小包問題的優化方法大概分成三種。第一種是把通信請求小包合并成大包,對于dense神經網絡發送梯度時不是每一層都發送,而是把多層梯度合并成一個長向量後進行通信;而對于sparse特征組則可以将多個特征組合并成一個向量進行通信,以此來降低通信的頻率;第二種優化方式是降低Worker和Server端的鎖開銷,Worker端是一個讀取資料然後計算梯度的過程,是以是全鍊路無鎖的;而Server端引入了一個多分片的Actor模式,即每個線程管理的範圍已知,是以包内無需加鎖,如此以來鎖開銷就會大大降低;最後一種優化的方式降低序列化、反序列化對象的建立和記憶體拷貝。
<b>※</b>稀疏矩陣通信優化
在整個XPS系統或Parameter Server架構的通信中有大量的SparseId(即我們通常所說的大規模離散ID),這就形成了稀疏矩陣通信優化的需求,目的是降低内部通信的頻率。對于這個問題,阿裡團隊經過長時間的探索後發現已有的如Google Dense和Google Sparse等類庫均不能滿足XPS平台稀疏矩陣的高頻通信需求。在此基礎上,XPS系統利用多重數組跳表的技術實作了自定義的數組哈希表(ArrayHashmap),它采用了realloc和mremap的方式來手工管理記憶體,目的是為了保證數組哈希表的鍵(key)和其對應的值(value)分别處于連續的空間中,通俗的解釋就是所有的鍵(key)連在一起,所有的值(value)連在一起,這樣設計的優勢顯而易見,在通信時直接發送記憶體塊的内容即可,而不需要像傳統的Hashmap一樣在通信時需要将目标key一個一個提取出來再打包發送,實作了序列化和反序列化的零拷貝。有了稀疏矩陣的通信優化之後,XPS整個系統的性能得到了質的飛躍,同時系統對于SDK層面的矩陣進行了封裝并提供了相應的通路接口,進而使使用者不需要感覺底層實作,并且支援string和int64作為矩陣的索引,使得整個平台訓練的key既可以是原始明文也可以是哈希化之後的對應值,友善開發人員進行調試和很多一次性的測試工作。以上就是XPS系統的整體工程優化的内容,通過這些優化讓整個XPS系統能夠在7個小時内完成百億資料規模的訓練,而每個訓練樣本具有100個特征。
<b>三. XNN深度學習算法</b>
<b>1.算法思想</b>
在介紹XNN的基本算法思想之前,首先介紹一下XPS算法體系的設計理念:
<b>※</b>如果非必要情況,無需采樣。對于點選率較大的場景,盡量選擇不采樣。因為樣本空間蘊含了所有使用者和産品的各個次元的資訊,不采樣能夠保持資料和特征的完整性。因為如果采樣,丢掉的正樣本或負樣本若再次出現對整展現實效果的影響是未知的。通過不采樣,我們可以還原每個特征在整個資料流中出現的曝光次數、關注次數和點選次數等資訊,并使得這些資訊變得可追蹤,使得整個離線訓練時的點選率、預估的情況與線上真實的點選率相比對,而不存在PCOPC準度偏高或偏低的情況。
<b>※</b>整個算法體系的設計需要适應千億規模的特征和萬億規模的樣本。
<b>※</b>模型需要能适應業務的動态性變化。例如阿裡“雙十一”期間的各種業務需要進行動态調控,那麼就需要模型能夠迅速的提供實時回報,進而幫助“雙十一”取得更好的成交。
鑒于上述的三個設計理念,阿裡團隊建立了有層次的模型體系。其中主要的内容是從XPS系統開發起始至今這一段時間内提出的四個創新的算法:
<b></b>通過擴充線性算法FTRL并落地業務場景提出了XFTRL算法,該算法對于傳統的線性算法FTRL的各種參數進行了流式的衰減,并且通過指數衰減的方式引入了二正則以避免參數突然偏離的情況。
<b></b>通過擴充推薦領域著名的矩陣分解學派算法SVD,在其中引入了SLIM思想,提出了XSVD算法。XSVD算法使傳統的SVD算法能夠進行大規模的流式計算。
<b></b>提出了XLTR算法,并且在其中引入了自動做特征的過程和多目标學習的特性。
<b></b>深度優化了經典的神經網絡算法,提出了XNN算法。
下面重點介紹一下XNN算法的設計思想:
從下面的直覺圖中可以看到整個XNN算法的體系結構。XNN算法的底層是一些離散特征群組合特征,形成了每個特征或長或短的embedding,長的embedding會分為二維、四維、八維和十六維,這些特征concatenate在一起并且做group級别的Reduce_sum,然後再與其他特征組和連續特征比如點選率等concatenate在一起做聯合訓練,結合在一起的這些特征會被傳入輸入層進行轉化,這種轉化的目的是将特征均勻化和标準化,逐層上傳到最上層後經過sigmoid激活函數處理後輸出。另外會有一些blas特征(使用者在翻頁時的頁面資訊)放在上層,因為通過日常測試會發現此類特征放于XNN算法的底層其效果并不理想。
使用者可以通過不同的算子元件組合出适合不同業務場景的XNN變形算法,這種組合就用到了下面将要提到的XNN算子體系結構:
<b>※</b>XNN的初始化算子采用了正态分布和均勻分布,并且使用Lazy Initialization的初始化方式,即當使用者使用該特征時才會進行初始化,避免過早初始化對性能的不必要開銷。
<b>※</b>在優化算子方面,XNN使用了FTRL、AdaGrad、Adam和AmsGrad等算子,并且在原始基礎上做了很多适合多種業務場景的優化。
<b>※</b>由于在分布式問題上存在許多異步性的問題,是以XNN算法提出了二階梯度補償和梯度折扣等異步性算子。
<b>※</b>XNN的激活算子采用了ReLU、SeLU和Sigmoid
下圖中展示了XNN算法在Worker端和Server端的僞代碼:
<b>2.XNN算法的優化技巧</b>
(1)輸入層優化
<b></b>特征模型化:XNN模型能夠自動統計每個特征長期、中期和短期的session統計值,作為連續值特征加到輸入層。因為ABFS能統計的次元總是有限的,但是通過特征模型化(Automatic Session)的方式可以統計到任何次元的Session而無需列印日志,大家可以把它看做是對Session的動态模組化。
<b></b>特征動态Embedding:在流式學習過程中,随着特征重要性增大,Session的次元會動态增長,以此達到記憶體動态負載均衡的目的。
<b></b>輸入層的優化對于整個神經網絡來說是十分重要的,簡單來說就是用好特征Embedding向量的加減乘除。
(2)Server更新模式優化
<b></b>Hot Update: 例如使用者登入後在短時間内浏覽了大量的寶貝(瀑布流浏覽),那麼此使用者的特征則是周期性的大量聚集和更新,然後“消失”,在這個過程中需要避免高頻特征過度更新的問題。
<b></b>Lazy Update:對于長尾的特征,要累計到一定的曝光數再更新,目的是避免長尾特征獲得過多不置信權重而分走過多的長尾權重。
<b></b>梯度修正:Pull和Push時根據權重值的差别進行梯度修正。
(3)算子優化
在算子優化方面,XNN算法會保持采用一些最新的算子如Adagrad、Adam和AmsGrad等,始終追随學術界的步伐并對這些最新的算子進行更新優化以便于應用到實際業務場景中去。同時XNN算法還會采用最新的激活函數例如Sigmoid、ReLU、LeakyReLU和SeLU等。
而算子優化中最重要的是流式指數衰減,即每次更新時對所有參數乘以一個相應的衰減值,進而保證最新的樣本獲得最大的權重。與此同時,對于點選率波動較大的場景,可以周期性地設定每個分區的啟動學習速率以快速适應資料流的變化。XNN算法還提供了一些可以靈活修改的算子,充分根據梯度、曆史梯度、曆史更新次數等聯合修正經典算子,其中曆史更新次數是一個很重要的名額,它代表了一個特征在最近一段時間内的更新情況,根據這些資訊設定置信度和打折率等能夠使算子更加适應目前的業務需求。
XNN算子優化遵循“如無必要,無需正則”的原則,由于樣本分布具有連續性,是以傳統的訓練集和測試集定義的“過拟合”不适應,對于相隔的樣本可以看做近似“同分布”,是以适度過拟合效果更好。XNN利用參數指數衰減模式來替代2正則的作用,兼顧了資料的流式特點,同時利用特征動态擦除模式來替代1正則的作用,保證了稀疏性。
<b>3.XNN的落地實用技巧</b>
(1)特征的哈希化和動态擦除
在訓練的過程中,特征的序列化會耗費許多時間,而特征的字元串化會占用很多記憶體,是以最好采用特征的哈希化。而訓練中的特征變化較多,可以使用動态擦除的方式來去除一些較弱(如曝光較低)的特征,以此達到節約記憶體的目的。在訓練時要保留組合特征,因為在資料挖掘和深度學習中的組合特征非常重要,對于持續的長尾優化來說這一點更是如此。
(2)樣本和特征處理
XNN訓練的樣本務必充分打散,因為未能充分打散的樣本會引發局部過拟合問題。對于特征的離散化問題,無需過度離散化,隻需要保留到小數點後幾位即可。而為了增強模型的表達能力,則可以用模型技術批量設計“新特征”,如Automatic Session。
(3)調參技巧
強烈建議讀者使用Test-Future-Data評估模式,因為該模式可以監控PCOPC走勢并及時調整訓練的過程,能夠極大地加速調參過程。當訓練中不小心引入部分周期性特征時,需要移除此類周期特征以避免造成PCOPC的波動。訓練時還可以随機列印百萬分之一特征的梯度變化資訊到Server端,以便于線上出現問題進行排查。
(4)快速一緻性調試和分布式預估
建議使用者将特征明文和特征哈希值均列印出來以便于進行調試,這與線上預估的設計存在一定聯系。線上預估技術若采用标準分布式,則模型表會同時保留特征哈希值和分布式分列資訊,因為分布式分列資訊是動态變化的,是以增加了通信和存儲的代價;比較快速的方法是基于Map-Reduce手工統計原始特征和分到哪些組,然後再和産出模型的哈希值作結合後進行分布式地上線。
(5)服務的動态性
由于資源和時間有限,是以需要快速響應業務的需求。例如“雙十一”當天,其業務變化十分迅速,需要快速适應業務的變化。可以通過調整衰減指數和打折力度來增強或者削弱目前樣本的重要性。當樣本由于近期資料變化幅度較大(換血量過大)而出現“抖動”狀況時,可以通過逐漸降低曆史梯度平方的最大值,加快機器學習的速率來适應業務的變化。
(6)快速疊代訓練的建議
用好特征:如上文提到的分布式特征的重要性篩選,同時還需要移除周期特征,防止引起PCOPC的抖動;加入一些組合特征,這對于整個模型的點和邊的渲染是非常重要的。
在快速疊代的過程中可以使用模型熱啟動的思想,即老模型的特征Embedding表達了複用,而新加的特征對應的神經網絡的邊設定一些初始值,然後直接續跑,比如在短期内運作新特征模型,結果也是收斂的,這樣就可以做到快速上線。
<b>四.總結</b>
XPS團隊打造的系列算法在集團内得到的廣泛的應用,我們希望用技術去拓展商業的邊界。得益于XPS系列算法,每天數百億級别樣本的場景可以進行全量不采樣地進行流式訓練,通過實時Session特征次元拓展特征體系,使得模型特征達到千億規模。千億特征的時代已經到來,讓我們享受這資料的饕餮盛宴。