一、prometheus和grafana 簡介
Prometheus 是繼 Kubernetes 之後的第二個 CNCF “畢業” 項目,其監控理念傳承于由谷歌研發的一款内部監控軟體,現主要開發語言為 go,代碼目前已經托管在 github 中,遵從 apache 2.0 開源協定,受歡迎的程度非常高,github 位址為:https://github.com/prometheus/。
監控通常可以分為白盒監控和黑盒監控。
白盒監控:一般是指通過監控應用程式内部的運作狀态及相應的名額來判斷可能會發生的問題,進而提前做出預判或者對應用程式進行相關優化。
黑盒監控:監控系統或服務的運作狀态,比如報錯、逾時等,在發生異常時做出相應處理措施。
prometheus的優勢:
易于管理,通俗易懂,prometheus在使用時隻有一個二進制的執行檔案,安裝非常簡單,不依賴于任何别的應用。
能夠輕易擷取服務内部狀态,比如jvm等。
高效靈活的查詢語句,每秒可以處理百萬級的監控名額
支援本地和遠端存儲,支援時序資料庫
采用http協定,預設pull模式拉取資料,也可以通過中間網關push資料(需要安裝push gateway)
支援自動發現(通過服務的方式進行自動發現待監控的目标,可以通過Consul實作服務發現)
可擴充,支援使用者自定義開發
易內建,可以和grafana 快速內建。
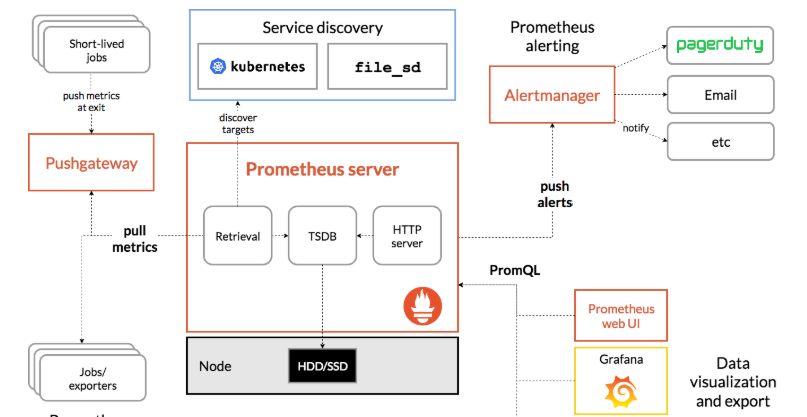
備注:此架構圖摘自prometheus官方網站
prometheus根據配置定時可以去拉取各個節點的資料,預設使用的拉取方式是pull,當然也可以支援使用pushgateway提供的push方式去擷取各個監控節點的資料。将擷取到的資料存入TSDB(時序型資料庫),pushgateway 就是 外部的應用可以将監控的資料主動推送給pushgateway,然後prometheus 自動從pushgateway進行拉取。此時prometheus已經擷取到了監控資料,可以使用内置的PromQL進行查詢。它的報警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和發送報警的一個元件。prometheus原生的圖示功能由于過于簡單,尤其是可視化的界面比較簡單,是以建議将prometheus資料接入grafana,由grafana進行統一管理。
Grafana是開源的可視化監控、資料分析利器,支援多種資料庫類型和豐富的套件,目前已支援超過50多個資料源,50多個面闆,17個應用程式和1700多個不同的儀表圖。(本文作者:張永清,轉載請注明來源部落格園:https://www.cnblogs.com/laoqing/p/14538635.html)
擁有快速靈活的用戶端圖表,面闆插件有許多不同方式的可視化名額和日志,官方提供的庫中包含了豐富的儀表盤插件,比如甘特圖、熱圖、折線圖、各種圖表等多種展示方式。
支援許多不同的時間序列資料(資料源)存儲後端。每個資料源都有一個特定查詢編輯器。官方支援資料源:Graphite、infloxdb、opensdb、prometheus、elasticsearch、cloudwatch,mysql ,zabbix等。每個資料源的查詢語言和功能有較大差異。可以将來自多個資料源的資料組合到一個儀表闆上,但每個面闆都要綁定到指定的資料源中,如下圖所示。

告警允許将規則附加到儀表闆面闆上。儲存儀表闆時會将警報規則提取到單獨的警報規則存儲中,并安排它們進行評估。報警消息還能支援釘釘、郵箱等推送至移動端。
支援內建豐富多樣的插件,也可以支援自定義的插件開發。
二、incubator-dolphinscheduler 簡介
incubator-dolphinscheduler是一個由國内公司發起的大資料領域的開源排程項目,incubator-dolphinscheduler 能夠支撐非常多的應用場景,包括:
以DAG圖的方式将Task按照任務的依賴關系關聯起來,可實時可視化監控任務的運作狀态
支援豐富的任務類型:Shell、MR、Spark、SQL(mysql、postgresql、hive、sparksql),Python,Sub_Process、Procedure,flink,datax,sqoop,http等
支援工作流定時排程、依賴排程、手動排程、手動暫停/停止/恢複,同時支援失敗重試/告警、從指定節點恢複失敗、Kill任務等操作
支援工作流優先級、任務優先級及任務的故障轉移及任務逾時告警/失敗
支援工作流全局參數及節點自定義參數設定
支援資源檔案的線上上傳/下載下傳,管理等,支援線上檔案建立、編輯
支援任務日志線上檢視及滾動、線上下載下傳日志等
實作叢集HA,通過Zookeeper實作Master叢集和Worker叢集去中心化
支援對<code>Master/Worker</code> cpu load,memory,cpu線上檢視
支援工作流運作曆史樹形/甘特圖展示、支援任務狀态統計、流程狀态統計
支援補數
支援多租戶
支援國際化
備注:此架構圖摘自社群官方網站
三、incubator-dolphinscheduler 如何快速接入到prometheus和grafana 中進行監控
1、通過prometheus中push gateway的方式采集監控名額資料。
需要借助push gateway一起,然後将資料發送到push gateway 位址中,比如位址為http://10.25x.xx.xx:8085,那麼就可以寫一個shell 腳本,通過crontab排程或者incubator-dolphinscheduler排程,定期運作shell腳本,來發送名額資料到prometheus中。
這段腳本中failedSchedulingTaskCounts 就是定義的prometheus中的一個名額。腳本通過sql語句查詢出失敗的任務數,然後發送到prometheus中。
然後在grafana 中就可以選擇資料源為prometheus,并且選擇對應的名額。
比如可以通過如下shell 腳本采集正在運作的任務數,然後通過push gateway 發送到prometheus中。(本文作者:張永清,轉載請注明來源部落格園:https://www.cnblogs.com/laoqing/p/14538635.html)
采集好了後,就可以達到如下的效果了,從這個圖就可以看出每個采集到的名額随着時間的變化趨勢了。
在配置好名額後,還可以配置該名額的告警,如下圖所示,點選Create Alert 按鈕,按照頁面提示,即可以配置告警通知。
通過上述方式還可以采集到的一些其他的常見名額如下:
1)、失敗的工作流執行個體數
2)、等待中的工作任務流數
3)、運作中的工作流執行個體數
2、通過grafana 直接查詢dolphinscheduler自身 的Mysql資料庫(也可以是别的資料庫)
首先需要在grafana 中定義一個資料源,這個資料源就是dolphinscheduler自身 的Mysql資料庫。
然後在grafana 中選擇這個資料源,Format as 格式選擇table,輸入對應的sql語句。(本文作者:張永清,轉載請注明來源部落格園:https://www.cnblogs.com/laoqing/p/14538635.html)
比如如下sql,統計本周以及當日正在運作的排程任務的情況。
這些配置完後,儲存就可以得到如下的表格:(本文作者:張永清,轉載請注明來源部落格園:https://www.cnblogs.com/laoqing/p/14538635.html)
通過類似上述方式的配置,在輸入sql後,選擇Graph視圖時,還可以生成任務耗時的曲線圖,如下所示
還可以支援甘特圖等多種圖,此處不再一一介紹了。
作者的原創文章,轉載須注明出處。原創文章歸作者所有,歡迎轉載,但是保留版權。對于轉載了部落客的原創文章,不标注出處的,作者将依法追究版權,請尊重作者的成果。