工廠模式一般都是建立一個産品,注重的是把這個産品建立出來,而不關心這個産品的組成部分。從代碼上看,工廠模式就是一個方法,用這個方法來生産出産品
建造者模式也是建立一個産品,但是不僅要把這個産品建立出來,還要關心這個産品的組成細節,組成過程。從代碼上看,建造者模式在建立産品的時候,這個産品有很多方法,建造者模式會根據這些相同的方法按不同的執行順序建造出不同組成細節的産品
淺拷貝:複制對象時隻複制對象本身,包括基本資料類型的屬性,但是不會複制引用資料類型屬性指向的對象,即拷貝對象的與原對象的引用資料類型的屬性指向同一個對象
淺拷貝沒有達到完全複制,即原對象與克隆對象之間有關系,會互相影響
深拷貝:複制一個新的對象,引用資料類型指向對象會拷貝新的一份,不再指向原有引用對象的位址
深拷貝達到了完全複制的目的,即原對象與克隆對象之間不會互相影響
Java泛型深度解析以及面試題_周将的部落格-CSDN部落格
Java泛型是在JDK5引入的新特性,它提供了編譯時類型安全檢測機制。該機制允許程式員在編譯時檢測到非法的類型,泛型的本質是參數類型。
泛型可以增強編譯時錯誤檢測,減少因類型問題引發的運作時異常。
泛型可以避免類型轉換。
泛型可以泛型算法,增加代碼複用性。
泛型類:它的定義格式是<code>class name<T1, T2, ..., Tn></code>,如下, 傳回一個對象中包含了code和一個data, data是一個對象,我們不能固定它是什麼類型,這時候就用T泛型來代替,大大增加了代碼的複用性。
泛型接口:和泛型類使用相似
泛型方法:它的定義是<code>[public] [static] <T> 傳回值類型 方法名(T 參數清單)</code>,隻有在前面加<code><T></code>這種的才能算是泛型方法,比如上面的setData方法雖然有泛型,但是不能算泛型方法
K 鍵
V 值
N 數字
T 類型
E 元素
S, U, V 等,泛型聲明的多個類型
鑽石操作符是在 java 7 中引入的,可以讓代碼更易讀,但它不能用于匿名的内部類。在 java 9 中, 它可以與匿名的内部類一起使用,進而提高代碼的可讀性。
JDK7以下版本需要 <code>Box<Integer> box = new Box<Integer>();</code>
JDK7及以上版本 <code>Box<Integer> integerBox1 = new Box<>();</code>
它的作用是對泛型變量的範圍作出限制,格式:
單一限制:<code><U extends Number></code>
多種限制:<code><U extends A & B & C></code>
多種限制的時候,類必須寫在第一個
通配符用<code>?</code>辨別,分為受限制的通配符和不受限制的通配符,它使代碼更加靈活,廣泛運用于架構中。
比如<code>List<Number></code>和<code>List<Integer></code>是沒有任何關系的。如果我們将print方法中參數清單部分的List聲明為<code>List<Number> list</code>, 那麼編譯是不會通過的,但是如果我們将List定義為<code>List<? extends Number> list</code>或者<code>List<?> list</code>,那麼在編譯的時候就不會報錯了。
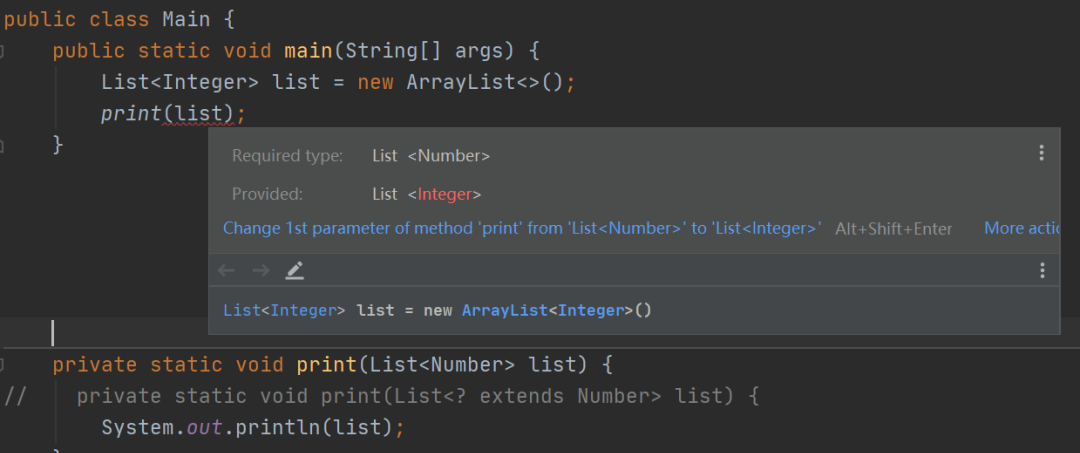

受限制的通配符:文法為<code><? extends XXX></code>,它可以擴大相容的範圍(XXX以及它的子類)
比如上面例子中print中如果改為List<Number>,雖然它能存儲Integer和Double等類型的元素,但是作為參數傳遞的時候,它隻能接受List<Number>這一種類型。如果聲明為List<? extends Number> list就不一樣了,相當于擴大了類型的範圍,使得代碼更加的靈活,代碼複用性更高。
<code><? super T></code>和extends一樣,隻不過extends是限定了上限,而super是限定了下限
非受限制的通配符:不适用關鍵字extends或者super。比如上面print參數清單聲明為List<?> list也可以解決問題。<code>?</code>代表了未知類型。是以所有的類型都可以了解為List<?>的子類。它的使用場景一般是泛型類中的方法不依賴于類型參數的時候,比如list.size(), 周遊集合等,這樣的話并不關心List中元素的具體類型。
PECS原則的全拼是"Producer Extends Consumer Super"。 當需要 頻繁取值,而不需要寫值 則使用上界通配符<code>? extends T</code>作為資料結構泛型。= 相反,當需要 頻繁寫值,而不需要取值 則使用下屆通配符<code>? super T</code>作為資料結構泛型。
案例分析:建立Apple,Fruit兩個類,其中Apple是Fruit的子類
其中Err1和Err2行處報錯,因為這些操作并不符合PECS原則,逐一分析:
Err1
使用<code>? super T</code>規定泛型的資料結構,其存儲的值是T的父類,而這裡superFruit.get()的對象為Fruit的父類對象,而指向該對象的引用類型為Fruit,父類缺少子類中的一些資訊,這顯然是不對的,是以編譯器直接禁止在使用<code>? super T</code>泛型的資料結構中進行取值,隻能進行寫值,正是開頭所說的CS原則。
Err2
使用<code>? extends T</code>規定泛型的資料結構,其存儲的值是T的子類,這裡exdentFruit.add()也就是向其中添加Fruit的子類對象,而Fruit可以有多種子類對象,是以當我們進行寫值時,我們并不知道其中存儲的到底是哪個子類,是以寫值操作必然會出現問題,是以編譯器接禁止在使用<code>? extends T</code>泛型的資料結構中進行寫,隻能進行取值,正是開頭所說的PE原則。
類型擦除作用:因為Java中的泛型實在JDK1.5之後新加的特性,為了相容性,在虛拟機中運作時是不存在泛型的,是以Java泛型是一種僞泛型,類型擦除就保證了泛型不在運作時候出現。
場景:編譯器會把泛型類型中所有的類型參數替換為它們的上(下)限,如果沒有對類型參數做出限制,那麼就替換為Object類型。是以,編譯出的位元組碼僅僅包含了正常類,接口和方法。
在必要時插入類型轉換以保持類型安全。
生成橋方法以在擴充泛型時保持多态性
Bridge Methods 橋方法
當編譯一個擴充參數化類的類,或一個實作了參數化接口的接口時,編譯器有可能是以要建立一個合成方法,名為橋方法。它是類型擦除過程中的一部分。下面對橋方法代碼驗證一下:
上面<code>Node<T></code>是一個泛型類型,沒有聲明上下限,是以在類型擦除後會變為Object類型。而MyNode類已經聲明了實際類型參數為String類型,這樣在調用父類set方法的時候就會出現不比對的情況,是以虛拟機在編譯的時候為我們生成了一個橋方法,我們通過javap -c MyNode.class檢視位元組碼檔案,看到确實為我們生成了一個橋方法
Java的泛型是JDK5新引入的特性,為了向下相容,虛拟機其實是不支援泛型,是以Java實作的是一種僞泛型機制,也就是說Java在編譯期擦除了所有的泛型資訊,這樣Java就不需要産生新的類型到位元組碼,所有的泛型類型最終都是一種原始類型,在Java運作時根本就不存在泛型資訊。
類型擦除其實在類常量池中儲存了泛型資訊,運作時還能拿到資訊,比如Gson的TypeToken的使用。
泛型算法實作的關鍵:利用受限類型參數。
檢查泛型類型,擷取目标類型
擦除類型變量,并替換為限定類型
如果泛型類型的類型變量沒有限定,則用Object作為原始類型
如果有限定,則用限定的類型作為原始類型
如果有多個限定(T extends Class1&Class2),則使用第一個邊界Class1作為原始類
在必要時插入類型轉換以保持類型安全
生成橋方法以在擴充時保持多态性
不能,簡單的來講是因為如果可以建立泛型數組,泛型擦除會導緻編譯能通過,但是運作時會出現異常。是以如果禁止建立泛型數組,就可以避免此類問題。
如果你隻需要從集合中獲得類型T , 使用<? extends T>通配符
如果你隻需要将類型T放到集合中, 使用<? super T>通配符
如果你既要擷取又要放置元素,則不使用任何通配符。例如<code>List<String></code>
<code><?></code> 非限定通配符既不能存也不能取, 一般使用非限定通配符隻有一個目的,就是為了靈活的轉型。其實List<?> 等于 List<? extends Object>。
雖然他們都會進行類型檢查,實質上卻完全不同。List<?> 是一個未知類型的List,而List<Object>其實是任意類型的List。你可以把List<String>, List<Integer>指派給List<?>,卻不能把List<String>指派給List<Object>。
這裡向ArrayList中插入10000000條資料,分别用for循環和for each循環進行周遊測試
根據執行結果,可以看到for循環速度更快一點,但是差别不太大
我們反編譯class檔案看看
可以看到增強for循環本質上就是使用iterator疊代器進行周遊
這裡向LinkedList中插入測試10000條資料進行周遊測試,實驗中發現如果循環次數太大,for循環直接卡死;
根據結果可以看到,周遊LinkedList時for each速度遠遠大于for循環速度
反編譯class檔案的源碼
for 循環就是按順序周遊,随機通路元素
for each循環本質上是使用iterator疊代器周遊,順序連結清單通路元素;
對于arraylist底層為數組類型的結構,使用for循環周遊比使用foreach循環周遊稍快一些,但相差不大
對于linkedlist底層為單連結清單類型的結構,使用for循環每次都要從第一個元素開始周遊,速度非常慢;使用foreach可以直接讀取目前結點,速度比for快很多
ArrayList數組類型結構對随機通路比較快,而for循環中的get()方法,采用的即是随機通路的方法,是以在ArrayList裡,for循環較快
LinkedList連結清單形結構對順序通路比較快,iterator中的next()方法,采用的即是順序通路的方法,是以在LinkedList裡,使用iterator較快
<code>單連結清單b</code>
阻塞IO 和 非阻塞IO
IO操作分為兩個部分,即發起IO請求和實際IO操作,阻塞IO和非阻塞IO的差別就在于第二個步驟是否阻塞
若發起IO請求後請求線程一直等待實際IO操作完成,則為阻塞IO
若發起IO請求後請求線程傳回而不會一直等待,則為非阻塞IO
同步IO 和 異步IO
IO操作分為兩個部分,即發起IO請求和實際IO操作,同步IO和異步IO的差別就在于第一個步驟是否阻塞
若實際IO操作阻塞請求程序,即請求程序需要等待或輪詢檢視IO操作是否就緒,則為同步IO
若實際IO操作不阻塞請求程序,而是由作業系統來進行實際IO操作并将結果傳回,則為異步IO
NIO、BIO、AIO
BIO表示同步阻塞式IO,伺服器實作模式為一個連接配接一個線程,即用戶端有連接配接請求時伺服器端就需要啟動一個線程進行處理,如果這個連接配接不做任何事情會造成不必要的線程開銷,當然可以通過線程池機制改善。
NIO表示同步非阻塞IO,伺服器實作模式為一個請求一個線程,即用戶端發送的連接配接請求都會注冊到多路複用器上,多路複用器輪詢到連接配接有I/O請求時才啟動一個線程進行處理。
AIO表示異步非阻塞IO,伺服器實作模式為一個有效請求一個線程,用戶端的I/O請求都是由作業系統先完成IO操作後再通知伺服器應用來啟動線程進行處理。
反射是在運作狀态中,對于任意一個類,都能夠知道這個類的所有屬性和方法;對于任意一個對象,都能夠調用它的任意一個方法和屬性;這種動态擷取的資訊以及動态調用對象的方法的功能稱為 Java 語言的反射機制。
反射實作了把java類中的各種結構法、屬性、構造器、類名)映射成一個個的Java對象
優點:可以實作動态建立對象和編譯,展現了很大的靈活性
缺點:對性能有影響,使用反射本質上是一種接釋操作,慢于直接執行java代碼
應用場景:
JDBC中,利用反射動态加載了資料庫驅動程式。
Web伺服器中利用反射調用了Sevlet的服務方法。
Eclispe等開發工具利用反射動态刨析對象的類型與結構,動态提示對象的屬性和方法。
很多架構都用到反射機制,注入屬性,調用方法,如Spring。
Java基礎學習總結——Java對象的序列化和反序列化 - 孤傲蒼狼 - 部落格園 (cnblogs.com)
序列化是指将Java對象轉化為位元組序列的過程,而反序列化則是将位元組序列轉化為Java對象的過程
我們知道不同線程/程序進行遠端通信時可以互相發送各種資料,包括文本圖檔音視訊等,Java對象不能直接傳輸,是以需要轉化為二進制序列傳輸,是以需要序列化
把對象的位元組序列永久地儲存到硬碟上,通常存放在一個檔案中
在很多應用中,需要對某些對象進行序列化,讓它們離開記憶體空間,入住實體硬碟,以便長期儲存。比如最常見的是Web伺服器中的Session對象,當有10萬使用者并發通路,就有可能出現10萬個Session對象,記憶體可能吃不消,于是Web容器就會把一些seesion先序列化到硬碟中,等要用了,再把儲存在硬碟中的對象還原到記憶體中
在網絡上傳送對象的位元組序列
當兩個程序在進行遠端通信時,彼此可以發送各種類型的資料。無論是何種類型的資料,都會以二進制序列的形式在網絡上傳送。發送方需要把這個Java對象轉換為位元組序列,才能在網絡上傳送;接收方則需要把位元組序列再恢複為Java對象
<code>java.io.ObjectOutputStream</code>代表對象輸出流,它的writeObject(Object obj)方法可對參數指定的obj對象進行序列化,把得到的位元組序列寫到一個目标輸出流中
<code>java.io.ObjectInputStream</code>代表對象輸入流,它的readObject()方法從一個源輸入流中讀取位元組序列,再把它們反序列化為一個對象,并将其傳回
隻有實作了<code>Serializable</code>和<code>Externalizable</code>接口的類的對象才能被序列化。Externalizable接口繼承自Serializable接口,實作Externalizable接口的類完全由自身來控制序列化的行為,而僅實作Serializable接口的類可以 采用預設的序列化方式
對象序列化包括如下步驟:
建立一個對象輸出流,它可以包裝一個其他類型的目标輸出流,如檔案輸出流
通過對象輸出流的writeObject()方法寫對象
對象反序列化的步驟如下:
建立一個對象輸入流,它可以包裝一個其他類型的源輸入流,如檔案輸入流
通過對象輸入流的readObject()方法讀取對象
<code>serialVersionUID</code>: 字面意思上是序列化的版本号,凡是實作Serializable接口的類都有一個表示序列化版本辨別符的靜态變量
如果實作Serializable接口的類如果類中沒有添加serialVersionUID,那麼就會出現警告提示
serialVersionUID有兩種生成方式:
采用Add default serial version ID方式生成的serialVersionUID是1L,例如:
2.采用Add generated serial version ID這種方式生成的serialVersionUID是根據類名,接口名,方法和屬性等來生成的,例如:
當想要給實作了某個接口的類中的方法,加一些額外的處理。比如說加日志,加事務等。可以給這個類建立一個代理,故名思議就是建立一個新的類,這個類不僅包含原來類方法的功能,而且還在原來的基礎上添加了額外處理的新類。這個代理類并不是定義好的,是動态生成的。具有解耦意義,靈活,擴充性強。
應用:
Spring的AOP
加事務
權重限
加日志
在java的java.lang.reflect包下提供了一個Proxy類和一個InvocationHandler接口,通過這個類和這個接口可以生成JDK動态代理類和動态代理對象
java.lang.reflect.Proxy是所有動态代理的父類。它通過靜态方法newProxyInstance()來建立動态代理的class對象和執行個體。
每一個動态代理執行個體都有一個關聯的InvocationHandler。通過代理執行個體調用方法,方法調用請求會被轉發給InvocationHandler的invoke方法。
首先定義一個<code>IncocationHandler</code>處理器接口實作類,實作其<code>invoke()</code>方法
通過<code>Proxy.newProxyInstance</code>生成代理類對象
有兩種方式:
1.、實作Cloneable接口并重寫Object類中的clone()方法;
2、實作Serializable接口,通過對象的序列化和反序列化實作克隆,可以實作真正的深度克隆