上節課我們主要介紹了解決線性分類問題的一個簡單的方法:PLA。PLA能夠在平面中選擇一條直線将樣本資料完全正确分類。而對于線性不可分的情況,可以使用Pocket Algorithm來處理。本節課将主要介紹一下機器學習有哪些種類,并進行歸納。
我們在上節課引入的銀行根據使用者個人情況判斷是否給他發信用卡的例子,這是一個典型的二進制分類(binary classification)問題。也就是說輸出隻有兩個,一般y={-1, +1},-1代表不發信用卡(負類),+1代表發信用卡(正類)。
二進制分類的問題很常見,包括信用卡發放、垃圾郵件判别、患者疾病診斷、答案正确性估計等等。二進制分類是機器學習領域非常核心和基本的問題。二進制分類有線性模型也有非線性模型,根據實際問題情況,選擇不同的模型。
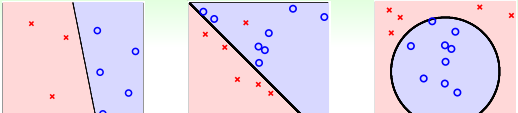
除了二進制分類,也有多元分類(Multiclass Classification)問題。顧名思義,多元分類的輸出多于兩個,y={1, 2, … , K}, K>2. 一般多元分類的應用有數字識别、圖檔内容識别等等。

二進制分類和多元分類都屬于分類問題,它們的輸出都是離散值。二對于另外一種情況,比如訓練模型,預測房屋價格、股票收益多少等,這類問題的輸出y=R,即範圍在整個實數空間,是連續的。這類問題,我們把它叫做回歸(Regression)。最簡單的線性回歸是一種典型的回歸模型。
除了分類和回歸問題,在自然語言處理等領域中,還會用到一種機器學習問題:結構化學習(Structured Learning)。結構化學習的輸出空間包含了某種結構在裡面,它的一些解法通常是從多分類問題延伸而來的,比較複雜。本系列課程不會詳細介紹Structured Learning,有興趣的讀者可以自行對它進行更深入的研究。
簡單總結一下,機器學習按照輸出空間劃分的話,包括二進制分類、多元分類、回歸、結構化學習等不同的類型。其中二進制分類和回歸是最基礎、最核心的兩個類型,也是我們課程主要介紹的部分。
如果我們拿到的訓練樣本D既有輸入特征x,也有輸出yn,那麼我們把這種類型的學習稱為監督式學習(Supervised Learning)。監督式學習可以是二進制分類、多元分類或者是回歸,最重要的是知道輸出标簽yn。與監督式學習相對立的另一種類型是非監督式學習(Unsupervised learning)。非監督式學習是沒有輸出标簽yn的,典型的非監督式學習包括:聚類(clustering)問題,比如對網頁上新聞的自動分類;密度估計,比如交通路況分析;異常檢測,比如使用者網絡流量監測。通常情況下,非監督式學習更複雜一些,而且非監督的問題很多都可以使用監督式學習的一些算法思想來實作。
介于監督式和非監督式學習之間的叫做半監督式學習(Semi-supervised Learning)。顧名思義,半監督式學習就是說一部分資料有輸出标簽yn,而另一部分資料沒有輸出标簽yn。在實際應用中,半監督式學習有時候是必須的,比如醫藥公司對某些藥物進行檢測,考慮到成本和實驗人群限制等問題,隻有一部分資料有輸出标簽yn。
監督式、非監督式、半監督式學習是機器學習領域三個主要類型。除此之外,還有一種非常重要的類型:增強學習(Reinforcement Learning)。增強學習中,我們給模型或系統一些輸入,但是給不了我們希望的真實的輸出y,根據模型的輸出回報,如果回報結果良好,更接近真實輸出,就給其正向激勵,如果回報結果不好,偏離真實輸出,就給其反向激勵。不斷通過“回報-修正”這種形式,一步一步讓模型學習的更好,這就是增強學習的核心所在。增強學習可以類比成訓練寵物的過程,比如我們要訓練狗狗坐下,但是狗狗無法直接聽懂我們的指令“sit down”。在訓練過程中,我們給狗狗示意,如果它表現得好,我們就給他獎勵,如果它做跟sit down完全無關的動作,我們就給它小小的懲罰。這樣不斷修正狗狗的動作,最終能讓它按照我們的指令來行動。實際生活中,增強學習的例子也很多,比如根據使用者點選、選擇而不斷改進的廣告系統
簡單總結一下,機器學習按照資料輸出标簽yn劃分的話,包括監督式學習、非監督式學習、半監督式學習和增強學習等。其中,監督式學習應用最為廣泛。
按照不同的協定,機器學習可以分為三種類型:
Batch Learning
Online
Active Learning
batch learning是一種常見的類型。batch learning獲得的訓練資料D是一批的,即一次性拿到整個D,對其進行學習模組化,得到我們最終的機器學習模型。batch learning在實際應用中最為廣泛。
online是一種線上學習模型,資料是實時更新的,根據資料一個個進來,同步更新我們的算法。比如線上郵件過濾系統,根據一封一封郵件的内容,根據目前算法判斷是否為垃圾郵件,再根據使用者回報,及時更新目前算法。這是一個動态的過程。之前我們介紹的PLA和增強學習都可以使用online模型。
active learning是近些年來新出現的一種機器學習類型,即讓機器具備主動問問題的能力,例如手寫數字識别,機器自己生成一個數字或者對它不确定的手寫字主動提問。active learning優勢之一是在擷取樣本label比較困難的時候,可以節約時間和成本,隻對一些重要的label提出需求。
簡單總結一下,按照不同的協定,機器學習可以分為batch, online, active。這三種學習類型分别可以類比為:填鴨式,老師教學以及主動問問題。
上面幾部分介紹的機器學習分類都是根據輸出來分類的,比如根據輸出空間進行分類,根據輸出y的标記進行分類,根據取得資料和标記的方法進行分類。這部分,我們将談談輸入X有哪些類型。
輸入X的第一種類型就是concrete features。比如說硬币分類問題中硬币的尺寸、重量等;比如疾病診斷中的病人資訊等具體特征。concrete features對機器學習來說最容易了解和使用。
第二種類型是raw features。比如說手寫數字識别中每個數字所在圖檔的mxn維像素值;比如語音信号的頻譜等。raw features一般比較抽象,經常需要人或者機器來轉換為其對應的concrete features,這個轉換的過程就是Feature Transform。
第三種類型是abstract features。比如某購物網站做購買預測時,提供給參賽者的是抽象加密過的資料編号或者ID,這些特征X完全是抽象的,沒有實際的實體含義。是以對于機器學習來說是比較困難的,需要對特征進行更多的轉換和提取。
簡單總結一下,根據輸入X類型不同,可以分為concetet, raw, abstract。将一些抽象的特征轉換為具體的特征,是機器學習過程中非常重要的一個環節。在《機器學習技法》課程中,我們再詳細介紹。
本節課主要介紹了機器學習的類型,包括Out Space、Data Label、Protocol、Input Space四種類型。
注明:
文章中所有的圖檔均來自中國台灣大學林軒田《機器學習基石》課程。