注:本分類下文章大多整理自《深入分析linux核心源代碼》一書,另有參考其他一些資料如《linux核心完全剖析》、《linux c 程式設計一站式學習》等,隻是為了更好地理清系統程式設計和網絡程式設計中的一些概念性問題,并沒有深入地閱讀分析源碼,我也是草草翻過這本書,請有興趣的朋友自己參考相關資料。此書出版較早,分析的版本為2.4.16,故出現的一些概念可能跟最新版本核心不同。
此書已經開源,閱讀位址 http://www.kerneltravel.net
一、時間系統
大部分PC 機中有兩個時鐘源,他們分别叫做RTC 和OS(作業系統)時鐘。RTC(Real Time Clock,實時時鐘)也叫做CMOS 時鐘,它是PC 主機闆上的一塊晶片(或者叫做時鐘電路),它靠電池供電,即使系統斷電,也可以維持日期和時間。由于它獨立于作業系統,是以也被稱為硬體時鐘,它為整個計算機提供一個計時标準,是最原始最底層的時鐘資料。
OS 時鐘産生于PC 主機闆上的定時/計數晶片(8253/8254),由作業系統控制這個晶片的工作,OS 時鐘的基本機關就是該晶片的計數周期。在開機時作業系統取得RTC 中的時間資料來初始化OS時鐘,然後通過計數晶片的向下計數形成了OS 時鐘,是以OS 時鐘并不是本質意義上的時鐘,它更應該被稱為一個計數器。OS 時鐘隻在開機時才有效,而且完全由作業系統控制,是以也被稱為軟時鐘或系統時鐘。
Linux 的OS 時鐘的實體産生原因是可程式設計定時/計數器産生的輸出脈沖,這個脈沖送入CPU,就可以引發一個中斷請求信号,我們就把它叫做時鐘中斷。Linux 中用全局變量jiffies 表示系統自啟動以來的時鐘滴答數目。每個時鐘滴答,時鐘中斷得到執行。時鐘中斷執行的頻率很高:100 次/秒(Linux 設計者将一個“時鐘滴答”定義為10ms),時鐘中斷的主要工作是處理和時間有關的所有資訊、決定是否執行排程程式。和時間有關的所有資訊包括系統時間、程序的時間片、延時、使用CPU 的時間、各種定時器,程序更新後的時間片為程序排程提供依據,然後在時鐘中斷傳回時決定是否要執行排程程式。
每個時鐘中斷(timer interrupt)發生時,由3 個函數協同工作,共同完成程序的選擇和切換,它們是:schedule()、do_timer()及ret_form_sys_call()。我們先來解釋一下這3 個函數。
• schedule():程序排程函數,由它來完成程序的選擇(排程)。
• do_timer():暫且稱之為時鐘函數,該函數在時鐘中斷服務程式中被調用,是時鐘中斷服務程式的主要組成部分,該函數被調用的頻率就是時鐘中斷的頻率即每秒鐘100 次(簡稱100 赫茲或100Hz);由這個函數完成系統時間的更新、程序時間片的更新等工作,更新後的程序時間片counter 作為排程的主要依據。
• ret_from_sys_call():系統調用、異常及中斷傳回函數。當一個系統調用或中斷完成時,該函數被調用,用于處理一些收尾工作,例如信号處理、核心任務等。函數檢測need_resched 标志,如果此标志為非0,那麼就調用排程程式schedule()進行程序的選擇。排程程式schedule()會根據具體的标準在運作隊列中選擇下一個應該運作的程序。當從排程程式傳回時,如果發現又有排程标志被設定,則又調用排程程式,直到排程标志為0,這時,從排程程式傳回時由RESTORE_ALL恢複被標明程序的環境,傳回到被標明程序的使用者空間,使之得到運作。
個人腳注:OS不是一直運作着的代碼,而是一堆躺在記憶體裡等着被調用的代碼,中斷處理在核心态,核心就是一個由 interrupt 驅動的程式。
可以是一個系統調用,x86 下很多OS的系統調用是靠 software interrupt 實作的,比如int 0x80,進入核心後就調用特定的核心函數執行。
也可以是一個使用者程式産生的異常。比如執行cpu 指令違法,segment fault 什麼的,作業系統一般會發送信号到程序,終止程序。
也可以是一個硬體産生的事件中斷。比如由IO裝置引起的可屏蔽中斷,作業系統會調用特定的裝置驅動程式進行服務。
一個使用者程式運作的時候,Linux 程序就在記憶體裡呆着,等着一個中斷的到來。
一般的時分系統裡,都會有個timer interrupt 每隔一段時間到來,也就是上面說的時鐘中斷了。
二、linux 的排程程式 schedule()
程序的狀态(簡略版):
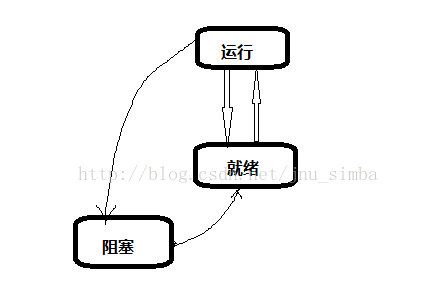
運作狀态(Running):程序占用處理器資源;處于此狀态的程序的數目小于等于處理器的數目。在沒有其他程序可以執行時(如所有程序都在阻塞狀态),通常會自動執行系統的空閑程序。
就緒狀态(Ready):程序已獲得除處理器外的所需資源,等待配置設定處理器資源;隻要配置設定了處理器程序就可執行。就緒程序可以按多個優先級來劃分隊列。例如,當一個程序由于時間片用完而進入就緒狀态時,排人低優先級隊列;當程序由I/O操作完成而進入就緒狀态時,排入高優先級隊列。
阻塞狀态(Blocked):當程序由于等待I/O操作或程序同步等條件而暫停運作時,它處于阻塞狀态。
(一)、下面來了解一下主要的排程算法及其基本原理。
1.時間片輪轉排程算法
時間片(Time Slice)就是配置設定給程序運作的一段時間。
在分時系統中,為了保證人機互動的及時性,系統使每個程序依次地按時間片輪流的方式執行,此時即應采用時間片輪轉法進行排程。在通常的輪轉法中,系統将所有的可運作(即就緒)程序按先來先服務的原則,排成一個隊列,每次排程時把CPU 配置設定給隊首程序,并令其執行一個時間片。時間片的大小從幾ms 到幾百ms 不等。當執行的時間片用完時,系統發出信号,通知排程程式,排程程式便據此信号來停止該程序的執行,并将它送到運作隊列的末尾,等待下一次執行。然後,把處理機配置設定給就緒隊列中新的隊首程序,同時也讓它執行一個時間片。這樣就可以保證運作隊列中的所有程序,在一個給定的時間(人所能接受的等待時間)内,均能獲得一時間片的處理機執行時間。
2.優先權排程算法
為了照顧到緊迫型程序在進入系統後便能獲得優先處理,引入了最高優先權排程算法。當将該算法用于程序排程時,系統将把處理機配置設定給運作隊列中優先權最高的程序,這時,又可進一步把該算法分成兩種方式。
(1)非搶占式優先權算法(又稱不可剝奪排程,Nonpreemptive Scheduling)
在這種方式下,系統一旦将處理機(CPU)配置設定給運作隊列中優先權最高的程序後,該程序便一直執行下去,直至完成;或因發生某事件使該程序放棄處理機時,系統方可将處理機配置設定給另一個優先權高的程序。這種排程算法主要用于批處理系統中,也可用于某些對實時性要求不嚴的實時系統中。Linux 2.4 之前 kernel is nonpreemptive
(2)搶占式優先權排程算法(又稱可剝奪排程,Preemptive Scheduling)
該算法的本質就是系統中目前運作的程序永遠是可運作程序中優先權最高的那個。在這種方式下,系統同樣是把處理機配置設定給優先權(weight,goodness()函數求出)最高的程序,使之執行。但是隻要一出現了另一個優先權更高的程序時,排程程式就暫停原最高優先權程序的執行,而将處理機配置設定給新出現的優先權最高的程序,即剝奪目前程序的運作。是以,在采用這種排程算法時,每當出現一新的可運作程序,就将它和目前運作程序進行優先權比較,如果高于目前程序,将觸發程序排程。這種方式的優先權排程算法,能更好的滿足緊迫程序的要求,故而常用于要求比較嚴格的實時系統中,以及對性能要求較高的批處理和分時系統中。Linux 2.6開始也實作了這種排程算法。
3.多級回報隊列排程
這是時下最時髦的一種排程算法。其本質是:綜合了時間片輪轉排程和搶占式優先權排程的優點,即:優先權高的程序先運作給定的時間片,相同優先權的程序輪流運作給定的時間片。
4.實時排程
最後我們來看一下實時系統中的排程。什麼叫實時系統,就是系統對外部事件有求必應、盡快響應。在實時系統中存在有若幹個實時程序或任務,它們用來反應或控制某個(些)外部事件,往往帶有某種程度的緊迫性,因而對實時系統中的程序排程有某些特殊要求。在實時系統中,廣泛采用搶占排程方式,特别是對于那些要求嚴格的實時系統。因為這種排程方式既具有較大的靈活性,又能獲得很小的排程延遲;但是這種排程方式也比較複雜。
(二)、程序排程的時機
Linux 排程時機主要有。
(1)程序狀态轉換的時刻:程序終止、程序睡眠;
(2)目前程序的時間片用完時(current->counter=0);
(3)裝置驅動程式;
(4)程序從中斷、異常及系統調用傳回到使用者态時。
時機1,程序要調用sleep()或exit()等函數進行狀态轉換,這些函數會主動調用排程程式進行程序排程。
時機2,由于程序的時間片是由時鐘中斷來更新的,是以,這種情況和時機4 是一樣的。
時機3,當裝置驅動程式執行長而重複的任務時,直接調用排程程式。在每次反複循環中,驅動程式都檢查need_resched 的值,如果必要,則調用排程程式schedule()主動放棄CPU。
時機4,如前所述,不管是從中斷、異常還是系統調用傳回,最終都調用ret_from_sys_call(),由這個函數進行排程标志need_resched的檢測,如果必要,則調用排程程式。那麼,為什麼從系統調用傳回時要調用排程程式呢?這當然是從效率考慮。從系統調用傳回意味着要離開核心态而傳回到使用者态,而狀态的轉換要花費一定的時間,是以,在傳回到使用者态前,系統把在核心态該處理的事全部做完。
(三)、程序排程的依據
排程程式運作時,要在所有處于可運作狀态的程序之中選擇最值得運作的程序投入運作。選擇程序的依據是什麼呢?在每個程序的task_struct 結構中有如下5 項:
need_resched、nice、counter、policy 及rt_priority
(1)need_resched: 在排程時機到來時,檢測這個域的值,如果為1,則調用schedule() 。
(2)counter: 程序處于運作狀态時所剩餘的時鐘滴答數,每次時鐘中斷到來時,這個值就減1。當這個域的值變得越來越小,直至為0 時,就把need_resched 域置1,是以,也把這個域叫做程序的“動态優先級”。
(3)nice: 程序的“靜态優先級”,這個域決定counter 的初值。隻有通過nice()、POSIX.1b sched_setparam() 或 5.4BSD/SVR4 setpriority()系統調用才能改變程序的靜态優先級。
(4)rt_priority: 實時程序的優先級
(5)policy: 從整體上區分實時程序和普通程序,因為實時程序和普通程序的排程是不同的,它們兩者之間,實時程序應該先于普通程序而運作, 可以通過系統調用sched_setscheduler()來改變排程的政策。對于同一類型的不同程序,采用不同的标準來選擇程序。對于普通程序,選擇程序的主要依據為counter 和nice 。對于實時程序,Linux采用了兩種排程政策,即FIFO(先來先服務排程)和RR(時間片輪轉排程)。因為實時程序具有一定程度的緊迫性,是以衡量一個實時程序是否應該運作,Linux 采用了一個比較固定的标準。實時程序的counter 隻是用來表示該程序的剩餘滴答數,并不作為衡量它是否值得運作的标準,這和普通程序是有差別的。
(四)、程序可運作程度的衡量
函數goodness()就是用來衡量一個處于可運作狀态的程序值得運作的程度。該函數綜合使用了上面我們提到的5 項,給每個處于可運作狀态的程序賦予一個權值(weight),排程程式以這個權值作為選擇程序的唯一依據。
這個函數比較很簡單。首先,根據policy 區分實時程序和普通程序。實時程序的權值取決于其實時優先級,其至少是1000,與conter 和nice 無關。普通程序的權值需特别說明如下兩點。
(1)為什麼進行細微的調整?如果p->mm 為空,則意味着該程序無使用者空間(例如核心線程),則無需切換到使用者空間。如果
p->mm=this_mm,則說明該程序的使用者空間就是目前程序的使用者空間,該程序完全有可能再次得到運作。對于以上兩種情況,都給其權值加1,算是對它們小小的“獎勵”。
(2)程序的優先級nice 是從早期UNIX 沿用下來的負向優先級,其數值标志“謙讓”的程度,其值越大,就表示其越“謙讓”,也就是優先級越低,其取值範圍為-20~+19,是以,(20-p->nice)的取值範圍就是0~40。可以看出,普通程序的權值不僅考慮了其剩餘的時間片,還考慮了其優先級,優先級越高,其權值越大。
(五)、程序排程的實作
排程程式在核心中就是一個函數schedule().函數所做的事解釋如下:
• 如果目前程序既沒有自己的位址空間,也沒有向别的程序借用位址空間,那肯定出錯。另外,如果schedule()在中斷服務程式内部執行,那也出錯。
• 對目前程序做相關處理,為選擇下一個程序做好準備。目前程序就是正在運作着的程序,可是,當進入schedule()時,其狀态卻不一定是TASK_RUNNIG,例如,在exit()系統調用中,目前程序的狀态可能已被改為TASK_ZOMBE;又例如,在wait()系統調用中,目前程序的狀态可能被置為TASK_INTERRUPTIBLE。是以,如果目前程序處于這些狀态中的一種,就要把它從運作隊列中删除。
• 從運作隊列中選擇最值得運作的程序,也就是權值最大的程序。
• 如果已經選擇的程序其權值為0,說明運作隊列中所有程序的時間片都用完了(隊列中肯定沒有實時程序,因為其最小權值為1000),是以,重新計算所有程序的時間片,其中宏操作NICE_TO_TICKS 就是把優先級nice 轉換為時鐘滴答。
• 程序位址空間的切換。如果新程序有自己的使用者空間,也就是說,如果next->mm 與next->active_mm 相同,那麼,switch_mm()函數就把該程序從核心空間切換到使用者空間,也就是加載next 的頁目錄。如果新程序無使用者空間(next->mm 為空),也就是說,如果它是一個核心線程,那它就要在核心空間運作,是以,需要借用前一個程序(prev)的位址空間,因為所有程序的核心空間都是共享的,是以這種借用是有效的。
• 用宏switch_to()進行真正的程序切換。
三、程序切換
由于i386 CPU 要求軟體設定TR 及TSS,Linux 核心隻不過“走過場”地設定TR 及TSS,以滿足CPU 的要求。但是,核心并不使用任務門,也不使用JMP 或CALL 指令實施任務切換。核心隻是在初始化階段設定TR,使之指向一個TSS,從此以後再不改變TR 的内容了。也就是說,每個CPU(如果有多個CPU)在初始化以後的全部運作過程中永遠使用那個初始的TSS。同時,核心也不完全依靠TSS 儲存每個程序切換時的寄存器副本,而是将這些寄存器副本儲存在各個程序自己的核心棧中(task_struct中的thread_struct 結構)。
這樣以來,TSS 中的絕大部分内容就失去了原來的意義。那麼,當進行任務切換時,怎樣自動更換堆棧?我們知道,新任務的核心棧指針(SS0 和ESP0)應當取自目前任務的TSS,可是,Linux 中并不是每個任務就有一個TSS,而是每個CPU 隻有一個TSS。Intel 原來的意圖是讓TR 的内容随着任務的切換而走馬燈似地換,而在Linux 核心中卻成了隻更換TSS 中的SS0 和ESP0,而不更換TSS 本身,也就是根本不更換TR 的内容。這是因為,改變TSS 中SS0 和ESP0 所化的開銷比通過裝入TR 以更換一個TSS 要小得多。是以,在Linux核心中,TSS 并不是屬于某個程序的資源,而是全局性的公共資源。在多處理機的情況下,盡管核心中确實有多個TSS,但是每個CPU 仍舊隻有一個TSS。
參考:http://www.ibm.com/developerworks/cn/linux/l-cn-timers/