上節課我們主要介紹了Kernel Logistic Regression,讨論如何把SVM的技巧應用在soft-binary classification上。方法是使用2-level learning,先利用SVM得到參數b和w,然後再用通用的logistic regression優化算法,通過疊代優化,對參數b和w進行微調,得到最佳解。然後,也介紹了可以通過Representer Theorem,在z空間中,引入SVM的kernel技巧,直接對logistic regression進行求解。本節課将延伸上節課的内容,讨論如何将SVM的kernel技巧應用到regression問題上。
首先回顧一下上節課介紹的Representer Theorem,對于任何包含正則項的L2-regularized linear model,它的最佳化解w都可以寫成是z的線性組合形式,是以,也就能引入kernel技巧,将模型kernelized化。
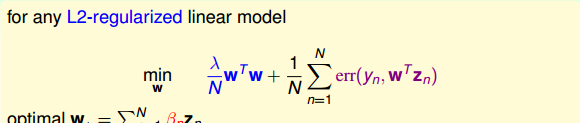
那麼如何将regression模型變成kernel的形式呢?我們之前介紹的linear/ridge regression最常用的錯誤估計是squared error,即err(y,w^Tz)=(y-w^Tz)^2。這種形式對應的解是analytic solution,即可以使用線性最小二乘法,通過向量運算,直接得到最優化解。那麼接下來我們就要研究如何将kernel引入到ridge regression中去,得到與之對應的analytic solution。
我們先把Kernel Ridge Regression問題寫下來:

其中,最佳解w_*必然是z的線性組合。那麼我們就把w_*=\sum_{n=1}^N\beta_nz_n代入到ridge regression中,将z的内積用kernel替換,把求w_*的問題轉化成求\beta_n的問題,得到:
ridge regression可以寫成矩陣的形式,其中第一項可以看成是\beta_n的正則項,而第二項可以看成是\beta_n的error function。這樣,我們的目的就是求解該式最小化對應的\beta_n值,這樣就解決了kernel ridge regression問題。
求解\beta_n的問題可以寫成如下形式:
E_{aug}(\beta)是關于β的二次多項式,要對Eaug(β)E_{aug}(\beta)求最小化解,這種凸二次最優化問題,隻需要先計算其梯度,再令梯度為零即可。\nabla E_{aug}(\beta)已經在上式中寫出來了,令其等于零,即可得到一種可能的β的解析解為: \beta=(\lambda I+K)^{-1}y
這裡需要關心的問題是(λI+K)的逆矩陣是否存在?答案是肯定的。因為我們之前介紹過,核函數K滿足Mercer’s condition,它是半正定的,而且λ>0,是以(λI+K)一定是可逆的。從計算的時間複雜上來說,由于(λI+K)是NxN大小的,是以時間複雜度是O(N^3)。還有一點,\nabla E_{aug}(\beta)是由兩項乘積構成的,另一項是K,會不會出現K=0的情況呢?其實,由于核函數K表征的是z空間的内積,一而言,除非兩個向量互相垂直,内積才為零,否則,一般情況下K不等于零。這個原因也決定了(λI+K)dense matrix,即β\beta的解大部分都是非零值。這個性質,我們之後還會說明。
是以說,我們可以通過kernel來解決non-linear regression的問題。下面比較一下linear ridge regression和kernel ridge regression的關系。
如上圖所示,左邊是linear ridge regression,是一條直線;右邊是kernel ridge regression,是一條曲線。大緻比較一下,右邊的曲線拟合的效果更好一些。這兩種regression有什麼樣的優點和缺點呢?對于linear ridge regression來說,它是線性模型,隻能拟合直線;其次,它的訓練複雜度是O(d^3+d^2N),預測的複雜度是O(d),如果N比d大很多時,這種模型就更有效率。而對于kernel ridge regression來說,它轉換到z空間,使用kernel技巧,得到的是非線性模型,是以更加靈活;其次,它的訓練複雜度是O(N^3),預測的複雜度是O(N),均隻與N有關。當N很大的時候,計算量就很大,是以,kernel ridge regression适合N不是很大的場合。比較下來,可以說linear和kernel實際上是效率(efficiency)和靈活(flexibility)之間的權衡。
我們在機器學習基石課程中介紹過linear regression可以用來做classification,那麼上一部分介紹的kernel ridge regression同樣可以來做classification。我們把kernel ridge regression應用在classification上取個新的名字,叫做least-squares SVM(LSSVM)。
先來看一下對于某個問題,soft-margin Gaussian SVM和Gaussian LSSVM結果有哪些不一樣的地方。
如上圖所示,如果隻看分類邊界的話,soft-margin Gaussian SVM和Gaussian LSSVM差别不是很大,即的到的分類線是幾乎相同的。但是如果看Support Vector的話(圖中方框标注的點),左邊soft-margin Gaussian SVM的SV不多,而右邊Gaussian LSSVM中基本上每個點都是SV。這是因為soft-margin Gaussian SVM中的αn\alpha_n大部分是等于零,\alpha_n>0的點隻占少數,是以SV少。而對于LSSVM,我們上一部分介紹了β的解大部分都是非零值,是以對應的每個點基本上都是SV。SV太多會帶來一個問題,就是做預測的矩g(x)=\sum_{n=1}^N\beta_nK(x_n,x),如果\beta_n非零值較多,那麼g的計算量也比較大,降低計算速度。基于這個原因,soft-margin Gaussian SVM更有優勢。
那麼,針對LSSVM中dense β的缺點,我們能不能使用一些方法來的得到sparse β,使得SV不會太多,進而得到和soft-margin SVM同樣的分類效果呢?下面我們将嘗試解決這個問題。
方法是引入一個叫做Tube Regression的做法,即在分類線上下分别劃定一個區域(中立區),如果資料點分布在這個區域内,則不算分類錯誤,隻有誤分在中立區域之外的地方才算error。
假定中立區的寬度為2ϵ,ϵ>0,那麼error measure就可以寫成:err(y,s)=max(0,|s-y|-\epsilon),對應上圖中紅色标注的距離。
通常把這個error叫做ϵ-insensitive error,這種max的形式跟我們上節課中介紹的hinge error measure形式其實是類似的。是以,我們接下來要做的事情就是将L2-regularized tube regression做類似于soft-margin SVM的推導,進而得到sparse β。
首先,我們把tube regression中的error與squared error做個比較:
然後,将err(y,s)與s的關系曲線分别畫出來:
上圖中,紅色的線表示squared error,藍色的線表示tube error。我們發現,當|s-y|比較小即s比較接近y的時候,squared error與tube error是差不多大小的。而在|s-y|比較大的區域,squared error的增長幅度要比tube error大很多。error的增長幅度越大,表示越容易受到noise的影響,不利于最優化問題的求解。是以,從這個方面來看,tube regression的這種error function要更好一些。
現在,我們把L2-Regularized Tube Regression寫下來:
這個最優化問題,由于其中包含max項,并不是處處可微分的,是以不适合用GD/SGD來求解。而且,雖然滿足representer theorem,有可能通過引入kernel來求解,但是也并不能保證得到sparsity β。從另一方面考慮,我們可以把這個問題轉換為帶條件的QP問題,仿照dual SVM的推導方法,引入kernel,得到KKT條件,進而保證解β是sparse的。
是以,我們就可以把L2-Regularized Tube Regression寫成跟SVM類似的形式:
值得一提的是,系數λ和C是反比例相關的,λ越大對應C越小,λ越小對應C越大。而且該式也把w_0即b單獨拿了出來,這跟我們之前推導SVM的解的方法是一緻的。
現在我們已經有了Standard Support Vector Regression的初始形式,這還是不是一個标準的QP問題。我們繼續對該表達式做一些轉化和推導:
如上圖右邊所示,即為标準的QP問題,其中\xi_n^{\bigvee}和\xi_n^{\bigwedge}分别表示upper tube violations和lower tube violations。這種形式叫做Support Vector Regression(SVR) primal。
SVR的标準QP形式包含幾個重要的參數:C和ϵ。C表示的是regularization和tube violation之間的權衡。large C傾向于tube violation,small C則傾向于regularization。ϵ表征了tube的區域寬度,即對錯誤點的容忍程度。ϵ越大,則表示對錯誤的容忍度越大。ϵ是可設定的常數,是SVR問題中獨有的,SVM中沒有這個參數。另外,SVR的QP形式共有\hat{d}+1+2N個參數,2N+2N個條件。
現在我們已經得到了SVR的primal形式,接下來将推導SVR的Dual形式。首先,與SVM對偶形式一樣,先令拉格朗日因子\alpha^{\bigvee}和\alpha^{\bigwedge},分别是與\xi_n^{\bigvee}和\xi_n^{\bigwedge}不等式相對應。這裡忽略了與\xi_n^{\bigvee}\geq0和\xi_n^{\bigwedge}\geq0對應的拉格朗日因子。
然後,與SVM一樣做同樣的推導和化簡,拉格朗日函數對相關參數偏微分為零,得到相應的KKT條件:
接下來,通過觀察SVM primal與SVM dual的參數對應關系,直接從SVR primal推導出SVR dual的形式。(具體數學推導,此處忽略!)
最後,我們就要來讨論一下SVR的解是否真的是sparse的。前面已經推導了SVR dual形式下推導的解w為:
w=\sum_{n=1}^N(\alpha_n^{\bigwedge}-\alpha_n^{\bigvee})z_n
相應的complementary slackness為:
對于分布在tube中心區域内的點,滿足|w^Tz_n+b-y_n|<\epsilon,此時忽略錯誤,\xi_n^{\bigvee}和\xi_n^{\bigwedge}都等于零。則complementary slackness兩個等式的第二項均不為零,必然得到\alpha_n^{\bigwedge}=0和\alpha_n^{\bigvee}=0,即\beta_n=\alpha_n^{\bigwedge}-\alpha_n^{\bigvee}=0。
是以,對于分布在tube内的點,得到的解\beta_n=0,是sparse的。而分布在tube之外的點,\beta_n\neq0。至此,我們就得到了SVR的sparse解。
這部分将對我們介紹過的所有的kernel模型做個概括和總結。我們總共介紹過三種線性模型,分别是PLA/pocket,regularized logistic regression和linear ridge regression。這三種模型都可以使用國立中國台灣大學的Chih-Jen Lin博士開發的Liblinear庫函數來解決。
另外,我們介紹了linear soft-margin SVM,其中的error function是\hat{err}_{svm},可以通過标準的QP問題來求解。linear soft-margin SVM和PLA/pocket一樣都是解決同樣的問題。然後,還介紹了linear SVR問題,它與linear ridge regression一樣都是解決同樣的問題,從SVM的角度,使用err_{tube},轉換為QP問題進行求解,這也是我們本節課的主要内容。
上圖中相應的模型也可以轉化為dual形式,引入kernel,整體的框圖如下:
其中SVM,SVR和probabilistic SVM都可以使用國立中國台灣大學的Chih-Jen Lin博士開發的LLibsvm庫函數來解決。通常來說,這些模型中SVR和probabilistic SVM最為常用。
本節課主要介紹了SVR,我們先通過representer theorem理論,将ridge regression轉化為kernel的形式,即kernel ridge regression,并推導了SVR的解。但是得到的解是dense的,大部分為非零值。是以,我們定義新的tube regression,使用SVM的推導方法,來最小化regularized tube errors,轉化為對偶形式,得到了sparse的解。最後,我們對介紹過的所有kernel模型做個總結,簡單概述了各自的特點。在實際應用中,我們要根據不同的問題進行合适的模型選擇。
注明:
文章中所有的圖檔均來自中國台灣大學林軒田《機器學習技法》課程