注:本分類下文章大多整理自《深入分析linux核心源代碼》一書,另有參考其他一些資料如《linux核心完全剖析》、《linux c 程式設計一站式學習》等,隻是為了更好地理清系統程式設計和網絡程式設計中的一些概念性問題,并沒有深入地閱讀分析源碼,我也是草草翻過這本書,請有興趣的朋友自己參考相關資料。此書出版較早,分析的版本為2.4.16,故出現的一些概念可能跟最新版本核心不同。
此書已經開源,閱讀位址 http://www.kerneltravel.net
一、Ext2 檔案系統
(一)、檔案系統布局
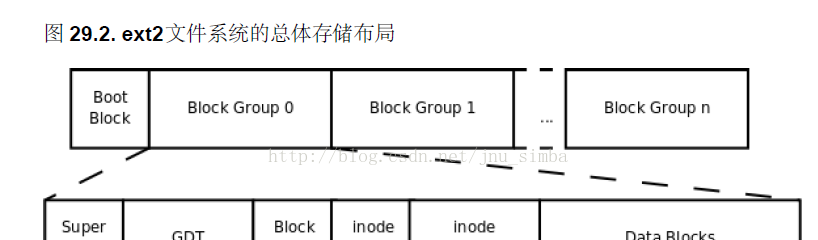
檔案系統中存儲的最小機關是塊( Block),一個塊究竟多大是在格式化時确定的,例如 mke2fs的 -b選項可以設定塊大小為 1024、 2048或 4096位元組。而上圖中引導塊/自舉塊( Boot Block)的大小是确定的,就是 1KB,引導塊是由 PC标準規定的,用來存儲磁盤分區資訊和啟動資訊,任何檔案系統都不能使用啟動塊。啟動塊之後才是 ext2檔案系統的開始, ext2檔案系統将整個分區劃成若幹個同樣大小的塊組( Block Group),每個塊組都由以下部分組成。
超級塊(Super Block)
描述整個分區的檔案系統資訊,例如塊大小、檔案系統版本号、上次 mount的時間等等。超級塊在每個塊組的開頭都有一份拷貝。
塊組描述符表(GDT, Group Descriptor Table)
由很多塊組描述符組成,整個分區分成多少個塊組就對應有多少個塊組描述符。每個塊組描述符( Group Descriptor)存儲一個塊組的描述資訊,例如在這個塊組中從哪裡開始是 inode表,從哪裡開始是資料塊,空閑的 inode和資料塊還有多少個等等。和超級塊類似,塊組描述符表在每個塊組的開頭也都有一份拷貝,這些資訊是非常重要的,一旦超級塊意外損壞就會丢失整個分區的資料,一旦塊組描述符意外損壞就會丢失整個塊組的資料,是以它們都有多份拷貝。通常核心隻用到第0 個塊組中的拷貝,當執行 e2fsck檢查檔案系統一緻性時,第 0個塊組中的超級塊和塊組描述符表就會拷貝到其它塊組,這樣當第 0個塊組的開頭意外損壞時就可以用其它拷貝來恢複,進而減少損失。
塊位圖(Block Bitmap)
一個塊組中的塊是這樣利用的:資料塊存儲所有檔案的資料,比如某個分區的塊大小是 1024位元組,某個檔案是 2049位元組,那麼就需要三個資料塊來存,即使第三個塊隻存了一個位元組也需要占用一個整塊;超級塊、塊組描述符表、塊位圖、 inode位圖、 inode表這幾部分存儲該塊組的描述資訊。那麼如何知道哪些塊已經用來存儲檔案資料或其它描述資訊,哪些塊仍然空閑可用呢?塊位圖就是用來描述整個塊組中哪些塊已用哪些塊空閑的,它本身占一個塊,其中的每個 bit代表本塊組中的一個塊,這個 bit為 1表示該塊已用,這個 bit為 0表示該塊空閑可用。 為什麼用df指令統計整個磁盤的已用空間非常快呢?因為隻需要檢視每個塊組的塊位圖即可,而不需要搜遍整個分區。相反,用 du指令檢視一個較大目錄的已用空間就非常慢,因為不可避免地要搜遍整個目錄的所有檔案。 與此相聯系的另一個問題是:在格式化一個分區時究竟會劃出多少個塊組呢?主要的限制在于塊位圖本身必須隻占一個塊。用 mke2fs格式化時預設塊大小是 1024位元組,可以用 -b參數指定塊大小,現在設塊大小指定為 b位元組,那麼一個塊可以有 8b個 bit,這樣大小的一個塊位圖就可以表示 8b個塊的占用情況,是以一個塊組最多可以有 8b個塊,如果整個分區有 s個塊,那麼就可以有 s/(8b)個塊組。格式化時可以用 -g參數指定一個塊組有多少個塊,但是通常不需要手動指定, mke2fs工具會計算出最優的數值。
inode 位圖(inode Bitmap)
和塊位圖類似,本身占一個塊,其中每個 bit表示一個 inode是否空閑可用。
inode 表(inode Table)
我們知道,一個檔案除了資料需要存儲之外,一些描述資訊也需要存儲,例如檔案類型(正常、目錄、符号連結等),權限,檔案大小,建立 /修改 /通路時間等,也就是 ls -l指令看到的那些資訊,這些資訊存在 inode中而不是資料塊中。每個檔案都有一個 inode,一個塊組中的所有 inode組成了 inode表。 inode表占多少個塊在格式化時就要決定并寫入塊組描述符中, mke2fs格式化工具的預設政策是一個塊組有多少個 8KB就配置設定多少個 inode。由于資料塊占了整個塊組的絕大部分,也可以近似認為資料塊有多少個 8KB就配置設定多少個 inode,換句話說,如果平均每個檔案的大小是 8KB,當分區存滿的時候 inode表會得到比較充分的利用,資料塊也不浪費。如果這個分區存的都是很大的檔案(比如電影),則資料塊用完的時候 inode會有一些浪費,如果這個分區存的都是很小的檔案(比如源代碼),則有可能資料塊還沒用完 inode就已經用完了,資料塊可能有很大的浪費。如果使用者在格式化時能夠對這個分區以後要存儲的檔案大小做一個預測,也可以用 mke2fs的 -i參數手動指定每多少個位元組配置設定一個 inode。
資料塊(Data Block)
根據不同的檔案類型有以下幾種情況:
對于正常檔案,檔案的資料存儲在資料塊中。 對于目錄,該目錄下的所有檔案名和目錄名存儲在資料塊中,注意檔案名儲存在它所在目錄的資料塊中,除檔案名之外, ls -l指令看到的其它資訊都儲存在該檔案的inode中。注意這個概念:目錄也是一種檔案,是一種特殊類型的檔案。 對于符号連結,如果目标路徑名較短則直接儲存在 inode中以便更快地查找,如果目标路徑名較長則配置設定一個資料塊來儲存。 裝置檔案、FIFO和socket 等特殊檔案沒有資料塊,即檔案大小為0,裝置檔案的主裝置号和次裝置号儲存在 inode中。
Ext2 檔案系統加上日志支援的下一個版本是 ext3 檔案系統,它和 ext2 檔案系統在硬碟布局上是一樣的,其差别僅僅是 ext3 檔案系統在硬碟上多出了一個特殊的 inode(可以了解為一個特殊檔案),用來記錄檔案系統的日志,也即所謂的 journal。
Ext4 支援更大的檔案和無限量的子目錄。
On an ext3 file-system 31,998 subdirectories is the limit. Each subdirectory is considered a “link” by the system and this is where we get the somewhat cryptic “too many links” message.
By the way, there is technically a limit of 32,000 subdirectories but each directory always includes two links – one to reference itself and another to reference the parent directory – that leaves us with 31,998 to work with.
consider bucketing your directories into a multi-level hashed structure, to reduce the number of directories you need to store at a particular "layer".In the case of hashes, a similar technique can be used, take the first 4 character of the file "ABCDEFG.txt" and put it in "AB/CD/ABCDEFG.txt"
(二)、資料塊尋址
如果一個檔案有多個資料塊,這些資料塊很可能不是連續存放的,應該如何尋址到每個塊呢?事實上,每個檔案的inode的索引項一共有 15個,從 Blocks[0]到 Blocks[14],每個索引項占 4位元組。前 12個索引項都表示塊編号,例如若Blocks[0]字段儲存着 24,就表示第 24個塊是該檔案的資料塊,如果塊大小是 1KB,這樣可以表示從 0位元組到 12KB的檔案。如果剩下的三個索引項 Blocks[12]到 Blocks[14]也是這麼用的,就隻能表示最大 15KB的檔案了,這是遠遠不夠的,事實上,剩下的三個索引項都是間接索引。
索引項Blocks[12]所指向的塊并非資料塊,而是稱為間接尋址塊( Indirect Block),其中存放的都是類似 Blocks[0]這種索引項,再由索引項指向資料塊。設塊大小是 b,那麼一個間接尋址塊中可以存放 b/4個索引項,指向 b/4個資料塊。是以如果把 Blocks[0]到 Blocks[12]都用上,最多可以表示 b/4+12個資料塊,對于塊大小是 1K的情況,最大可表示 268K的檔案。如下圖所示,注意檔案的資料塊編号是從 0開始的, Blocks[0]指向第 0個資料塊, Blocks[11]指向第 11個資料塊, Blocks[12]所指向的間接尋址塊的第一個索引項指向第 12個資料塊,依此類推。

從上圖可以看出,索引項 Blocks[13]指向兩級的間接尋址塊,總共最多可表示 (b/4)^2 +b/4+12個資料塊,對于 1K的塊大小最大可表示 64.26MB的檔案。索引項 Blocks[14]指向三級的間接尋址塊,總共最多可表示 (b/4)^3 +(b/4)^2 +b/4+12個資料塊,對于 1K的塊大小最大可表示 16.06GB的檔案。
可見,這種尋址方式對于通路不超過 12個資料塊的小檔案是非常快的,通路檔案中的任意資料隻需要兩次讀盤操作,一次讀 inode(也就是讀索引項)一次讀資料塊。而通路大檔案中的資料則需要最多五次讀盤操作: inode、一級間接尋址塊、二級間接尋址塊、三級間接尋址塊、資料塊。實際上,磁盤中的 inode(索引節點高速緩存)和資料塊(塊高速緩存)往往已經被核心緩存了,讀大檔案的效率也不會太低。
二、VFS 虛拟檔案系統
Linux支援各種各樣的檔案系統格式,如 ext2、 ext3、 reiserfs、 FAT、 NTFS、 iso9660等等,不同的磁盤分區、CD光牒或其它儲存設備都有不同的檔案系統格式,然而這些檔案系統都可以 mount到某個目錄下,使我們看到一個統一的目錄樹,各種檔案系統上的目錄和檔案我們用 ls指令看起來是一樣的,讀寫操作用起來也都是一樣的,這是怎麼做到的呢? Linux核心在各種不同的檔案系統格式之上做了一個抽象層,使得檔案、目錄、讀寫通路等概念成為抽象層的概念,是以各種檔案系統看起來用起來都一樣,這個抽象層稱為虛拟檔案系統(VFS,Virtual File System)。
VFS 是應用程式和具體的檔案系統之間的一個層。不過,在某些情況下,一個檔案操作可能由VFS 本身去執行,無需調用下一層程式。例如,當某個程序關閉一個打開的檔案時,并不需要涉及磁盤上的相應檔案,是以,VFS 隻需釋放對應的檔案對象。類似地,如果系統調用lseek()修改一個檔案指針,而這個檔案指針指向有關打開的檔案與程序互動的一個屬性,那麼VFS 隻需修改對應的檔案對象,而不必通路磁盤上的檔案,是以,無需調用具體的檔案系統子程式。從某種意義上說,可以把VFS 看成“通用”檔案系統,它在必要時依賴某種具體的檔案系統。
每個程序在PCB(Process Control Block)中都儲存着一個指向檔案描述符表的指針(struct files_struct* files),檔案描述符就是這個表的索引,每個表項都有一個指向已打開檔案的指針,現在我們明确一下:已打開的檔案在核心中用 file結構體表示,檔案描述符表中的指針指向 file結構體。
在file結構體中維護 File Status Flag( file結構體的成員 f_flags)和目前讀寫位置( file結構體的成員 f_pos)。在上圖中,程序 1和程序 2都打開同一檔案,但是對應不同的 file結構體,是以可以有不同的 File Status Flag和讀寫位置。 file結構體中比較重要的成員還有 f_count,表示引用計數( Reference Count),dup、 fork等系統調用會導緻多個檔案描述符指向同一個 file結構體,例如有 fd1和 fd2都引用同一個 file結構體,那麼它的引用計數就是 2,當 close(fd1)時并不會釋放 file結構體,而隻是把引用計數減到 1,如果再 close(fd2),引用計數就會減到 0同時釋放 file結構體,這才真的關閉了檔案。
每個file結構體都指向一個 file_operations結構體,這個結構體的成員都是函數指針,指向實作各種檔案操作的核心函數。比如在使用者程式中 read一個檔案描述符, read通過系統調用進入核心,然後找到這個檔案描述符所指向的 file結構體,找到 file結構體所指向的 file_operations結構體,調用它的 read成員所指向的核心函數以完成使用者請求。在使用者程式中調用
lseek、read、write、ioctl、open等函數,最終都由核心調用 file_operations的各成員所指向的核心函數完成使用者請求。 file_operations結構體中的 release成員用于完成使用者程式的 close請求,之是以叫 release而不叫 close是因為它不一定真的關閉檔案,而是減少引用計數,隻有引用計數減到 0才關閉檔案。對于同一個檔案系統上打開的正常檔案來說, read、 write等檔案操作的步驟和方法應該是一樣的,調用的函數應該是相同的,是以圖中的三個打開檔案的 file結構體指向同一個 file_operations結構體。如果打開一個字元裝置檔案,那麼它的 read、 write操作肯定和正常檔案不一樣,不是讀寫磁盤的資料塊而是讀寫硬體裝置,是以 file結構體應該指向不同的 file_operations結構體,其中的各種檔案操作函數由該裝置的驅動程式實作。
每個file結構體都有一個指向 dentry結構體的指針, “dentry”是 directory entry(目錄項)的縮寫。我們傳給 open、 stat等函數的參數的是一個路徑,例如 /home/akaedu/a,需要根據路徑找到檔案的 inode。為了減少讀盤次數,核心緩存了目錄的樹狀結構,稱為 dentry cache(目錄高速緩存),其中每個節點是一個 dentry結構體,隻要沿着路徑各部分的 dentry搜尋即可,從根目錄 /找到 home目錄,然後找到 akaedu目錄,然後找到檔案 a。 dentry cache隻儲存最近通路過的目錄項,如果要找的目錄項在 cache中沒有,就要從磁盤讀到記憶體中。
每個dentry結構體都有一個指針指向 inode結構體。 inode結構體儲存着從磁盤 inode讀上來的資訊。在上圖的例子中,有兩個 dentry,分别表示 /home/akaedu/a和 /home/akaedu/b,它們都指向同一個 inode,說明這兩個檔案互為硬連結。 inode結構體中儲存着從磁盤分區的 inode讀上來資訊,例如所有者、檔案大小、檔案類型和權限位等。每個 inode結構體都有一個指向 inode_operations結構體的指針,後者也是一組函數指針指向一些完成檔案目錄操作的核心函數。和 file_operations不同, inode_operations所指向的不是針對某一個檔案進行操作的函數,而是影響檔案和目錄布局的函數,例如添加删除檔案和目錄、跟蹤符号連結等等,屬于同一檔案系統的各 inode結構體可以指向同一個 inode_operations結構體。
inode結構體有一個指向 super_block結構體的指針。 super_block結構體儲存着從磁盤分區的超級塊讀上來的資訊,例如檔案系統類型、塊大小等。 super_block結構體的 s_root成員是一個指向 dentry的指針,表示這個檔案系統的根目錄被 mount到哪裡,在上圖的例子中這個分區被 mount到 /home目錄下。
file、 dentry、 inode、 super_block這幾個結構體組成了 VFS的核心概念。對于 ext2檔案系統來說,在磁盤存儲布局上也有 inode和超級塊的概念,是以很容易和 VFS中的概念建立對應關系。而另外一些檔案系統格式來自非 UNIX系統(例如 Windows的 FAT32、 NTFS),可能沒有 inode或超級塊這樣的概念,但為了能 mount到 Linux系統,也隻好在驅動程式中硬湊一下,在 Linux下看 FAT32和 NTFS檔案系統會發現權限位是錯的,所有檔案都是 rwxrwxrwx,因為它們本來就沒有 inode和權限位的概念,這是硬湊出來的。