編譯 : Troy·Chang、愛心心、reason_W 校對 : reason_W 下個月機器學習領域的頂會Nips就要在大洋彼岸開幕啦,那麼這次的Nips又有什麼值得關注的亮點呢?Bengio在新作中提出了RNN優化的新概念fraternal dropout,通過最小化使用不同的dropout mask的同一個RNN的預測差異,提升RNN對于不同dropout mask的不變性,來對RNN進行優化。模型在對比實驗中取得了非常驚豔的效果,同時在圖像标注和半監督任務上也表現不俗,下面就跟随小編對這篇文章進行一發膜拜吧。
RNN作為神經網絡中的一類十分重要的架構,主要用于語言模組化和序列預測。然而,RNN的優化卻相當棘手,比前饋神經網絡要難的多,學界也提出了很多技術來解決這個問題。我們在我們中提出了一項叫做fraternal dropout的技術,主要通過利用dropout來實作這個目标。具體來說,我們首先用不同的dropout mask對兩個一模一樣的RNN進行訓練,同時最小化它們(pre-softmax)預測的差異。通過這種方式,我們的正則項會促進RNN的表示對dropout mask的不變性。我們證明了我們的正則項的上限是線性期望dropout目标,而且線性期望dropout目标已經被證明了可以解決dropout在訓練和推理階段的差異導緻的較大差異(gap)。我們在兩個基準資料集(Penn Treebank 和Wikitext-2.)上進行了序列模組化任務以評價我們的模型,并且獲得了十分驚豔的結果。我們也證明了這種方法可以為圖像标注(Microsoft COCO)和半監督(CIFAR-10)任務帶來顯著的性能提升。
像LSTM網絡(LSTM; Hochreiter & Schmidhuber(1997))和門控循環單元(GRU; Chung et al. (2014))這樣的循環神經網絡都是處理諸如語言生成、翻譯、語音合成以及機器了解等序列模組化任務的流行架構。然而由于輸入序列的長度可變性,每個時刻相同轉換算子的重複應用以及由詞彙量決定的大規模密集嵌入矩陣等問題的存在,與前饋網絡相比,這些RNNs網絡架構更加難以優化。也正是由于同前饋神經網絡相比,RNNs在優化問題上遇到的這些挑戰,使得批歸一化以及它的變體(層歸一化,循環批歸一化,循環歸一化傳播),盡管确實帶來了很大的性能提升,但其應用依然沒有像它們在前饋神經網絡中對應的部件一樣成功(Laurent等, 2016),。同樣的,dropout的樸素應用(Srivastava等,2014)也已經證明在RNNs中是無效的(Zaremba等,2014)。是以,RNNs的正則化技術到目前為止依然是一個活躍的研究領域。
為了解決這些挑戰,Zaremba等人(2014)提出将dropout僅用于多層RNN中的非環式連接配接。Variational dropout(Gal&Ghahramani,2016))會在訓練期間在整個序列中使用相同的dropoutmask。DropConnect(Wan等,2013)在權重矩陣上應用了dropout操作。Zoneout(Krueger et al等(2016))以類似的dropout方式随機選擇使用前一個時刻隐藏狀态,而不是使用目前時刻隐藏狀态。類似地,作為批歸一化的替代,層歸一化将每個樣本内的隐藏單元歸一化為具有零均值和機關标準偏差的分布。循環批标準化适用于批标準化,但對于每個時刻使用非共享的mini-batch統計(Cooijmans等,2016)。
Merity等人(2017a)和Merity等(2017b)從另一方面證明激活正則化(AR)和時域激活正則化(TAR)也是正則化LSTMs的有效方法。
在我們中,我們提出了一個基于dropout的簡單正則化,我們稱之為fraternal dropout。這個方法将最小化兩個網絡預測損失的等權重權重和(這兩個網絡由兩個不同dropoutmask在同一個LSTM上得到),并将兩個網絡的(pre-softmax)預測結果的L2差作為正則項相加。我們分析證明了,該方法的正則化目标等于最小化來自不同的i.i.d. dropoutmask的預測結果的方差。該方法将會提升預測結果對于不同dropoutmask的不變性。同時,文章也讨論了我們的正則項和線性期望dropout(Ma等,2016)、II-model(Laine&Aila,2016)以及激活正則化(Merity等,2017a)的相關性,并且通過實驗證明了我們的方法與這些相關方法相比帶來的性能提升,第五部分的ablation study将進一步解釋這些方法。
Dropout在神經網絡中是一種強大的正則化方式。它通常在密集連接配接的層上更有效,因為與參數共享的卷積層相比,它們更容易受到過拟合的影響。出于這個原因,dropout是RNN系列一個重要的正則化方式。然而,dropout的使用在訓練和推理階段之間是存在gap的,因為推理階段假設是用線性激活的方式來校正因子,是以每個激活的期望值都會不同。(小編注:為了更好的了解這部分内容,大家可以參考Dropout with Expectation-linear Regularization - https://arxiv.org/abs/1609.08017 ,這篇文章從理論上分析了dropout的ensemble模式和一般的求期望模式的gap。然後提出了将這個gap作為一種正則化方式,也就是說gap的優化目标就是要盡可能小)。另外,帶有dropout的預測模型通常會随着不同dropout mask而變化。然而,在這種情況下理想的結果就是最後的預測結果不随着dropout mask的變化而變化。
是以,提出fraternal dropout的想法就是在訓練一個神經網絡模型時,保證在不同dropout masks下預測結果的變化盡可能的小。比如,假定我們有一個RNN模型M(θ),輸入是X,θ 是該模型的參數,然後讓
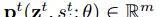
表示預測模型,即給定一個在t時間點的輸入樣例X,dropout mask是

目前輸入是zt ,其中zt 是關于輸入X的一個函數,隐藏層的狀态是跟之前時刻有關。同樣的,
是跟整個輸入目标樣本對(X,Y)在第t時刻的損失值相關的。
在fraternal dropout中,我們采用兩個相同的RNN來同時前饋輸入樣本X。這兩個RNN共享相同的模型參數θ,但是在每個時刻t有不同的dropout masks
和
。這樣在每個時間點t,會産生兩個損失值
是以,fraternal dropout整體的損失函數就可以由下面公式表示,
其中κ是正則化系數,m是
的維數,
是fraternal dropout正則化項,具體表示如下,
我們采用蒙特卡洛采樣來估計
,其中
,
和計算
值使用的是同一表達式。是以,額外的計算可以忽略不計。
我們注意到,如下面所示,我們正則化項的目标等價于最小化在不同dropout masks下,預測函數的方差(附錄中有證明)
備注1 假定
均是獨立同分布的,dropout masks和
是上述的預測函數。
是以,
Ma et al.(2016)分析研究顯示下述兩者之間的預期誤差(在樣本上)是有上限的,即在所有的dropout mask下的模型的期望值與使用平均mask的期望值之間的誤差。基于這一結論,他們提出了明确地最小化差異(我們在我們的該符号表達中采用了他們的正則式),
其中,s是dropout mask。但是,基于可行性考慮,他們提出在實踐中使用下列正則式進行替代,
特别地,這個式子是通過在網絡中的兩次前饋輸入(分别使用和不使用dropout mask),以及最小化主要網絡損失(該損失是在有dropout的情況下的)和前面指定的正則項(但是在無dropout的網絡中沒有反向傳播梯度)來實作的。Ma et al.(2016)的目标是最小化網絡損失以及期望差異,這個期望差異是指來自獨立的dropout mask的預測值和來自期望的dropout mask的預測值之間的差異。同時,我們的正則項目标的上限是線性期望dropout,如下式所示(附錄中證明):
結果表明,最小化ELD目标可以間接地最小化我們的正則項。最終如前文所述,他們僅在無dropout的網絡中應用了目标損失(target loss)。實際上,在我們的ablation研究中(參見第5節),我們發現通過網絡(無dropout)反向傳播目标損失(target loss)會讓優化模型更難。但是,在該設定中,同時反向傳播目标損失(target loss)能夠獲得包括性能增益和收斂增益的網絡收益。我們認為由于在所用執行個體(case)中,網絡權重更有可能通過反向傳播更新來達到目标,是以我們的正則項收斂速度會更快。尤其對于權重dropout(Wan et al., 2013)更是如此,因為在這種情況下,dropout權重将不會在訓練的疊代中獲得更新。
為了實作在半監督分類任務中提高性能的目标,Laine & Aila(2016)提出了II –model。他們提出的模型和我們提出的模型相似,除了他們僅在其中一個網絡中應用了目标損失(target loss),并且使用的是依賴時間的權重函數(而我們使用常量k/m),可以等價于是我們模型的深度前饋版本。他們執行個體的直覺(intuition)是利用未标記的資料來最小化兩種預測上的差異,即兩種使用不同dropout mask的同一網絡的預測值。而且,他們也在監督任務中測試了他們的模型,但是無法解釋使用這一正則項帶來的提升。
通過對我們的執行個體(case)進行分析,我們證明了,最小化該正則項(在II –model中也使用了)同最小化模型預測結果(備注1)中的方差是等價的。此外,我們也證明了正則項同線性期望dropout(命題1)之間的關系。在第5節,我們研究了基于沒有在II –model中使用的兩種網絡損失的目标的影響。我們發現在兩個網絡中應用目标損失(target loss)将使得網絡獲得關鍵性的更快的收斂。最後,我們注意到時域嵌入(temporal embedding ,Laine&Aila(2016)提出的另一模型,聲稱對于半監督學習來說,是比II –model更好的版本)在自然語言處理應用中相當的棘手,因為儲存所有時刻的平均預測值會十分消耗記憶體(因為預測值的數目往往非常大-數以萬計)。還有一點,我們證明了在監督學習的執行個體(case)中,使用時間依賴的權重函數來代替一個常量值k/m是沒有必要的。因為标記的資料是已知的,我們沒有觀察到Laine&Aila(2016)提到的問題,即當在早期訓練的epoch中太大時,網絡會陷入退化。我們注意到尋找一個優化的常量值比調整時間依賴的函數更加容易,這也在我們的執行個體中進行了實作。
和II –model的方法相似,我們的方法也和其他半監督任務相關,主要有Rasmus et al.(2015)和Sajjadi et al.(2016)。由于半監督學習并不是本文要關注的部分,是以我們參考了Laine&Aila(2016)的更多細節。
在語言模組化的情形下,我們在兩個基準資料集Penn Tree-bank(PTB)資料集(Marcus等,1993)和WikiText-2(WT2)資料集(Merity等,2016)上測試了我們的模型。預處理操作參考了Mikolov等(2010)(用于PTB語料庫),并且用到了Moses tokenizer(Koehn等,2007)(用于WT2資料集)。
對于這兩個資料集,我們都采用了Merity等人描述的AWD-LSTM 3層架構。 (2017a)。 用于PTB的模型中的參數數量是2400萬,而WT2的參數數量則是3400萬,這是因為WT2詞彙量更大,我們要使用更大的嵌入矩陣。 除了這些差異之外,架構是相同的。
Penn Tree-bank(PTB)詞級任務
我們使用混淆度名額來評估我們的模型,并将我們獲得的結果與現有的最好結果進行比較。表1顯示了我們的結果,在現有benchmark上,我們的方法達到了最先進的性能。
WikiText-2詞級任務
在WikiText-2語言模組化任務的情況下,我們的表現優于目前的最新技術水準。 表2列出了最終結果。關于實驗的更多細節可以在5.4節中找到。
我們也把fraternal dropout應用到了圖像标注任務上。我們使用著名的show and tell模型作為baseline(Vinyals等,2014)。這裡要強調的是,在圖像标注任務中,圖像編碼器和句子解碼器架構通常是一起學習的。但既然我們想把重點放在在RNN中使用fraternal dropout的好處上,我們就使用了當機的預訓練ResNet-101(He 等,2015)模型作為我們的圖像編碼器。這也就意味着我們的結果不能與其他最先進的方法直接比較,但是我們提供了原始方法的結果,以便讀者可以看到我們的baseline良好的表現。表3提供了最終的結果。
我們認為,在這個任務中,κ值較小時,效果最好,因為圖像标注編碼器在開始時就被給予了所有資訊,是以連續預測的方差會小于在無條件的自然語言處理任務中的方差。Fraternal dropout可能在這裡是有利的,主要是因為它對不同mask的平均梯度進行了平均,進而更新權重頻率更快。
在本節中,我們的目标是研究與我們方法密切相關的現有方法。expectation linear dropout (Ma et al. ,2016),Π-model(Laine & Aila 2016)和activity regularization(Merity et al. 2017b),我們所有的ablation studies(小編注:ablation study是為了研究模型中所提出的一些結構是否有效而設計的實驗)都是采用一個單層LSTM,使用相同的超參數和模型結構。
第二部分已經讨論了我們法方法和ELD方法的聯系。這裡我們進行實驗來研究使用ELD正則化和我們的正則化(FD)性能上的差異。除了ELD,我們還研究了一個ELD的改進版ELDM。ELDM就是跟FD的用法相似,将ELD應用在兩個相同的LSTM上(在原作者的實驗中隻是在一個LSTM上用了dropout)。是以我們得到了一個沒有任何正則化方式的基準模型。圖1畫出了這幾種方法訓練過程的曲線。與其他方法相比,我們的正則化方法在收斂性上表現的更好。而在泛化性能上,我們發現FD和ELD相似,而基準模型和ELDM表現得更差。有趣的是,如果一起看訓練和驗證曲線,ELDM似乎還有待進一步的優化。
因為Π-MODEL和我們的算法相似(即使它是為前饋網絡中的半監督學習而設計的),是以我們為了明确我們算法的優勢,分别從定性和定量的角度研究了它們在性能上的差異。首先,基于PTB(Penn Treebank Dataset)任務,我們運作了單層LSTM和3層AWD-LSTM來在語言模組化上對兩種算法進測試比較。圖1和2顯示了測試結果。我們發現我們的模型比Π-MODEL收斂速度明顯加快,我們相信這是因為我們采用兩個網絡(Π-MODEL相反)反向傳播目标損失,導緻了更多的采用基于目标梯度的參數更新。
盡管我們設計的算法是專門來解決RNN中的問題,但為了有一個公平的對比,我們在半監督任務上也與Π-MODEL做了對比。是以,我們使用了包含10類由32x32大小圖像組成的CIFAR-10資料集。參照半監督學習文獻中通常的資料拆分方法,我們使用了4000張标記的圖檔和41000張無标記圖檔作為訓練集,5000張标記的圖檔做驗證集合10000張标記的圖檔做測試集。我們使用了原版的56層殘差網絡結構,網格搜尋參數
dropout率在{0.05,0.1,0.15,0.2},然後保持剩下的超參數不變。我們另外測驗了使用無标記資料的重要性。表4給出了結果。我們發現我們算法的表現和Π-MODEL幾乎一樣。當無标記資料沒有使用時,fraternal dropout僅僅比普通的dropout表現得要稍微好些。
Merity et al.(2017b)的作者們研究了激活正則化(AR)的重要性,和在LSTM中的時域激活正則化(TAR),如下所示,
表4:基于ResNet-56模型在改變的(半監督任務)CIFAR-10資料集的準确率。我們發現我們提出的算法和II模型有同等的表現。當未标記資料沒有被使用,傳統dropout會破壞性能,但是fraternal dropout提供了略好的結果。這意味着當缺乏資料和不得不使用額外的正則方法時,我們的方法是有利的。
圖4:Ablation研究:使用PTB詞級模型的單層LSTM(10M參數)的訓練(左)和驗證(右)混淆度。顯示了基準模型、時域激活正則化(TAR)、預測模型(PR)、激活正則化(AR)和fraternal dropout(FD,我們的算法)的學習動态曲線。我們發現與對照的正則項相比,FD收斂速度更快,泛華性能更好。
其中,是LSTM在時刻t時的輸出激活(是以同時取決于目前輸入和模型參數)。注意AR和TAR正則化應用在LSTM的輸出上,而我們的正則化應用在LSTM的pre-softmax輸出上。但是,因為我們的正則項能夠分解如下:
并且,封裝了一個項和點積項,我們通過實驗确定了在我們的方法中的提升并不是單獨由正則項決定的。TAR目标也有一個相似的争論。我們在上運作網格搜尋,包括在Merity et al.(2017b)中提到的超參數。我們在提出的正則項中使用。而且,我們也在一個正則式為正則項(PR)上進行了比較,以進一步排除僅來自于正則項的任何提升。基于這一網格搜尋,我們選擇了在驗證集上對所有正則化來說最好的模型,另外還報告了一個未使用已提及的4種正則化的基準模型。學習動态如圖4所示。與其他方法相比,我們的正則項在收斂和概括期間都表現更好。當描述的任意正則項被應用時,平均隐藏态激活減少(如圖3所示)。
正如4.1小節所述,由于Melis等人(2017)的影響,我們要確定fraternal dropout能夠超越現有的方法不僅僅是因為廣泛的超參數網格搜尋。是以,在我們的實驗中,我們保留了原始檔案中提到的絕大多數超參數,即嵌入和隐藏狀态大小,梯度裁剪值,權重衰減以及用于所有dropout層的值(詞向量上的dropout,LSTM層間的輸出,最終LSTM的輸出和嵌入dropout)。
當然,也進行了一些必要的變化:
AR和TAR的系數必須改變,因為fraternal dropout也影響RNN的激活(如5.3小節所述) - 我們沒有進行網格搜尋來獲得最好的值,而是簡單地去除了AR和TAR正則項。
由于我們需要兩倍的記憶體,是以batch的size被減小了一半,進而讓模型産生大緻相同的記憶體量需求,并且可以安裝在同一個GPU上
最後一項變動的地方是改變ASGD的非單調間隔超參數n。我們在n∈{5,25,40,50,60}上進行了一個網格搜尋,并且在n取最大值(40,50和60)的時候獲得了非常相似的結果。是以,我們的模型使用普通SGD優化器的訓練時間要長于原始模型。
為了確定我們的模型效果,我們在PTB資料集上通過使用不同種子的原始超參數(不進行微調)運作了10個學習程式來計算置信區間。平均最佳驗證混淆度為60.64±0.15,最小值為60.33。測試混淆度分别為58.32±0.14和58.05。我們的得分(59.8分驗證混淆度和58.0分測試混淆度)比最初的dropout得分好。
由于計算資源有限,我們在WT2資料集對fraternal dropout運作了一次單獨的訓練程式。在這個實驗中,我們使用PTB資料集的最佳超參數(κ= 0.1,非單調間隔n = 60,batch size減半)。
我們證明使用fine-tuning會對ASGD有好處(Merity等,2017a)。然而,這是一個非常耗時的做法,因為在這個附加的學習過程中可能會使用不同的超參數,是以通過廣泛的網格搜尋而獲得更好的結果的可能性更高。是以,在我們的實驗中,我們使用與官方存儲庫中實施的相同的fine-tunin程式(甚至沒有使用fraternal dropout)。表5中列出了fine-tuning的重要性。
我們認為,運作網格聯合搜尋所有超參數可能會獲得更好的結果(改變dropout率可能是尤其有利,因為我們的方法就明确地使用了dropout)。然而,我們這裡的目的是排除僅僅因為使用更好的超參數而表現更好的可能性。
在論文中,我們提出了一個叫做fraternal dropout的簡單RNNs正則化方法,通過作為正則項來減少模型在不同的dropout mask上預測結果的方差。通過實驗證明了我們的模型具有更快的收斂速度,同時在基準語言模組化任務上取得了最先進的成果。 我們也分析研究了我們的正則項和線性期望dropout (Ma 等,2016)之間的關系。我們進行了一系列的ablation 研究,從不同的角度評估了模型,并從定性和定量的角度将其與相關方法進行了仔細比較。
論文連結 Fraternal Dropout 本文來源于 AI 科技大學營微信公衆号