接《 NEXT 技術快報》:計算機視覺篇(上)
Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image
原文連結:http://openaccess.thecvf.com/content_cvpr_2017/papers/Tome_Lifting_From_the_CVPR_2017_paper.pdf
項目首頁:http://www0.cs.ucl.ac.uk/staff/D.Tome/papers/LiftingFromTheDeep.html
結果視訊:https://www.youtube.com/watch?v=tKfkGttx0qs
本文來自倫敦大學學院和愛丁堡大學的研究人員。作者提出了一個高效、統一的基于多階段深度學習的架構來解決單幅圖像中2維關節估計和3維姿态估計問題。
以往的方法在解決2維關節估計和3維姿态估計問題時,往往是分步驟進行的,第一個過程的結果是第二個過程的輸入,這樣分步驟會造成資訊損失,同時最終的估計結果也并不是最優的。
提出一個統一的基于多階段深度學習的架構來解決2維關節估計和3維姿态估計問題。
該架構提出了一個新的CNN架構,可以将基于圖像外觀特征提取的2D标志點位置資訊與用預訓練好的3D姿态模型提取的3D幾何骨骼資訊結合起來統一學習,最終提高2D姿态和3D姿态的估計精度。
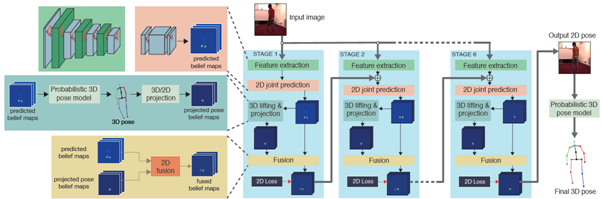
基于多階段深度卷積神經網絡的人體姿态估計流程圖
● 優勢:在Human3.6M資料集上分别進行2D和3D姿态估計,與目前最好的方法相比,估計準确性分别要高于對比方法。
● 不足:計算效率上還打不到實時。
● 手勢(hand)
3D Convolutional Neural Networks for Efficient and Robust Hand Pose Estimation from Single Depth Images
原文連結:https://eeeweba.ntu.edu.sg/computervision/Research%20Papers/2017/3D%20Convolutional%20Neural%20Networks%20for%20Efficient%20and%20Robust%20Hand%20Pose%20Estimation%20from%20Single%20Depth%20Images.pdf
項目首頁:https://sites.google.com/site/geliuhaontu/home/cvpr2017
本文來自新加坡南洋理工大學和新加坡A*Star 高性能計算研究所。作者提出了一種簡單有效、實時的手部姿态估計的方法。對于深度圖像利用一種三維資料體的表示方法,并有效利用資料的空間結構資訊,提升算法性能。
● 由2維CNN提取的基于圖像的特征由于缺少3D空間資訊,并不完全适用于3D手部姿态估計。
● 多視圖CNN仍然無法完全充分利用深度圖像中的3D空間資訊
從深度圖像分割出手的部分,提取手的3D點雲并編碼為3維資料體,這一個資料作為3維CNN的輸入,輸出為一組手在3維資料體中的關節相對位置。最後利用簡單的坐标變換來獲得手在相機系統下的關節位置。

方法整體流程圖
● 優勢:
❖ 在MSRA和NYU資料集上進行實驗,并與目前最好的方法——層次回歸方法——進行比較。當誤差門檻值維10mm時,提出的方法要由于目前最好方法。實驗環境為2塊CPU:Intel Core i7 5930K 3.50GHz, 64GB RAM,GPU:NvidiaQuadro K5200
❖ 實時運作,超過215fps
❖ 對于手部尺寸變化和整體方向變化比較魯棒
Crossing Nets: Combining GANs and VAEs With a Shared Latent Space for Hand Pose Estimation
原文連結:https://arxiv.org/pdf/1702.03431.pdf
結果連結:https://www.youtube.com/watch?v=oumCArDjC7w
文章由瑞士蘇黎世聯邦理工學院、波昂大學和荷蘭語天主教魯汶大學的研究人員共同發表在CVPR2017上。作者創新性地結合了生成式對抗網絡和半監督學習,充分利用了沒有标簽的深度圖,進而改進了泛化性能。同時方法具有非常高的計算效率。
● 從單一的深度圖像估計3D手部姿态需要大量的标注訓練資料,成本很高
● 以往基于圖像合成的方法得到的結果真實感比較差
結合生成式對抗網絡(GAN)和半監督學習進行結構預測:基于變分自編碼器(VAE)估計姿态估計,利用GAN生成高品質深度圖用來訓練模型,在一個多任務學習的架構下統一處理姿态估計問題。
整體處理流程圖
❖ 在NYU、MSRA和ICVL三個公開資料集上與分别與該資料集的目前2種state-of-the-art 方法進行對比。結果顯示提出的方法在估計誤差上要優于對比方法。
❖ 更好的泛化性
❖ 對于大視角的姿态變化的估計更加魯棒
❖ 可以更好地利用無标記的資料
❖ 在CPU上可以達到實時估計
視覺跟蹤一般也被稱為目标跟蹤,就是在連續的視訊序列中,建立所要跟蹤物體的位置關系,得到物體完整的運動軌迹。具體的,在第一幀圖像給定目标的狀态,一般是目标的bounding box資訊,然後預測之後每幀圖像中目标的狀态,對應的也是目标的bounding box資訊。
Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
原文連結:http://openaccess.thecvf.com/content_cvpr_2017/papers/Yun_Action-Decision_Networks_for_CVPR_2017_paper.pdf
項目首頁:https://sites.google.com/view/cvpr2017-adnet
本文來自南韓首爾國立大學的研究人員。作者創新性地将強化學習與目标跟蹤結合起來,講目标跟蹤問題轉化為一系列決策行為。提高了跟蹤系統的準确率和計算效率。下圖是文章核心思想的一個示意圖。
預測跟蹤目标未來的位置對應為一系列動作決策
目前基于卷機神經網絡的方法雖然獲得了比傳統方法更好的性能,但是也面臨着以下問題:1)探索感興趣區域的和選擇最佳候選目标的搜尋算法比較低效;2)需要大量帶标記的視訊序列用來訓練模型
提出了一個行為-決策網絡(ADNet)結構,在新的一幀圖像中,産生一系列動作來找到目标的位置和尺度。
ADNet目的在于學習一個政策來根據目前位置這一狀态去選擇最優的行為決策去跟蹤目标。這個政策網絡是一個深度卷積神經網絡,輸入是從前一幀圖像中摳出來的圖像塊,輸出包括在下一幀中的決策機率分布。
學習算法包括兩部分:監督學習和強化學習。監督學習部分:使用從訓練視訊集提取的樣本來訓練網絡。這一過程沒有序列資訊。強化學習部分:将監督學習得到的網絡作為初始值,使用跟蹤序列(采樣狀态、決策行為和獎勵信号)來訓練政策網絡。
技術路線示意圖
❖ 不需要bounding box regression等後處理操作
❖ 計算高效:和state-of-the-art方法MDNet和C-COT方法相比,在準确率和成功率接近的情況下,标準算法版本要快要比兩種方法快3倍;快速算法版本在降低3%性能的情況下,可以達到15 fps。
● 不足:提出的決策行為對于目标突然大幅度移動和目标比例大幅度改變這兩種情況無法很好地适應,跟蹤失敗。
Tracking by Natural Language Specification
原文連結:http://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Tracking_by_Natural_CVPR_2017_paper.pdf
本文來自荷蘭阿姆斯特丹大學的研究者。本文創新性地沒有采用目标跟蹤傳統的給定bounding box的設定方法,而是采用了自然語言描述來指定感興趣的目标。提出的方法被證明非常有效,并且以往的目标跟蹤方法都可以嵌入到這個流程當中。下圖是文章方法的結果示意圖。
基于自然語言描述目标的視覺跟蹤
對于跟蹤在真實場景的應用中,比如機器人和無人駕駛,使用自然語言來定義“目标”更加自然合理
和以往做視覺跟蹤的基本假設和處理流程不同,沒有采用基于bounding box初始的ground truth,而是根據自然語言描述來跟蹤目标。
給定視訊中的一幀圖像和一句自然語言描述來作為查詢,目的是跟蹤視訊中由語言所指定的目标。
在最常用的目标跟蹤資料集OTB100和ImageNet Videos的基礎上,為每個視訊中的每個目标擴充了一句語言描述。加上ReferIt,在以上三個資料集上進行對比實驗。
在目标跟蹤中引入了一種創新的人機互動方式,并證明了其有效性。
● 不足:
缺乏和基于bounding box的方法的對比實驗
NEXT技術快報:快速掃描學術/技術前沿進展,做出必要的分析歸納,尋找它們在産品中落地的可能性。希望能幫助大家了解前沿,拓寬視野,提高決策效率。