接《 NEXT 技術快報》:圖形篇 (上)
模拟各向異性的布料或者長的毛發,在動畫中始終是個熱點難題,15、16連續年沒有相關的SIGGRAPH論文或者大的進展。之前的方法多是基于粒子的拉格朗日方法,但是計算量巨大。本文試圖用最新的Material Point Method來解算,基本思想是将模拟的元素視為流體或連續體,避免了顯示的解算碰撞和摩擦,進而揭示出一種統一的實體模拟架構。
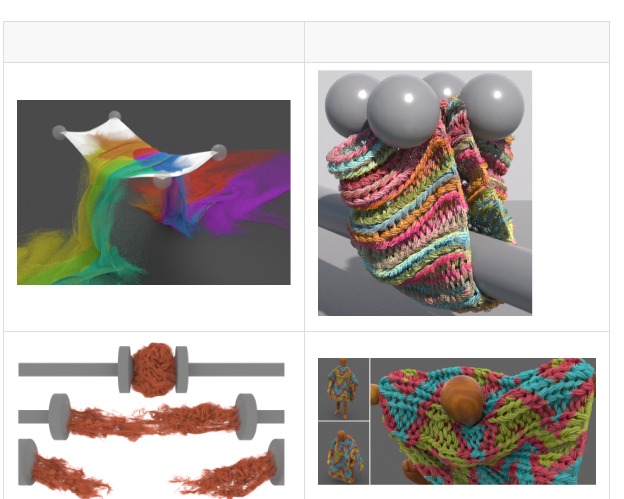
如何快速模拟真實的各向異性布料始終是個熱點,因為存在元素間的碰撞和摩擦計算量很大;
長發的模拟同樣是個難題。
本文是綜合之前的三篇SIGGRAPH論文做出的改進,分别是迪斯尼在做冰雪奇緣時為雪的模拟開發的MPM算法、APIC算法,以及為模拟沙子開發的算法,第一篇解決将拉格朗日方法和歐幾裡得方法做了整合,提出了一個變形梯度投射的思想,将動力學解算放在網格空間處理,進而可以處理顆粒之間的壓縮、彈性和斷裂等效果;APIC算法則解決了MPM中從網格向粒子傳遞時的耗散問題(相當于低通濾波);沙子模拟算法則是利用Drucker-Prager Yield Criterion來簡化模組化連續體内的摩擦力,将應力張量分解為粘稠流體内的耗散和摩擦兩種因素,并且考慮了網格内部元素的填充率。本文的貢獻是提出了在垂直于表面或線的切線方向上的形變梯度,進而間接阻止元素之間的穿插,也解決了之前MPM方法存在的精度問題。以下是三篇相關文獻。
1、A Semi-Implicit Material Point Method for the Continuum Simulation of Granular Materials
2、A material point method for snow simulation
3、The Affine Particle-In-Cell Method
優勢:可用于模拟毛衣、長的頭發等的動畫效果,部分解決了元素之間的自碰撞和摩擦和撕裂等問題。對于180萬個面的布料模拟,每幀耗時2分鐘(運作在CPU上,正常網格)。
不足:1)實作在CPU上,未來可能會遷移到GPU上實作更快的模拟速度;2)目前使用的不是自适應網格,随着模拟的物體尺寸增大,網格數會三次方增加;3)不能完全保證元素之間不會穿插,這是算法本身決定的,不過作者測試,在時間步長比較小的時候,能基本避免;4)網格的尺寸需要設定為與材質元素的尺寸一緻,否則模拟中會出現瑕疵。
毛衣、長頭發等的動畫效果,以及和其他元素之間的互動(這些元素也可以用MPM算法模拟)
渲染(Rendering)
渲染是從幾何體和材質資訊生成最終呈現在螢幕上的2D畫面的過程,分為offline和online兩種類型,後者包括遊戲中常見的OpenGL和DirectX管線,因為場景複雜、光效複雜和對計算時間的要求,主要的研究方向可分為:
● 光線追蹤中采樣算法的研究,比如蒙特卡洛的優化、bi-direction等;
● 針對各種複雜光效的優化,比如景深、運動模糊、高光反射、sss效果等;
● 實時渲染算法的研究,比如實時的多邊形光源的照明、實時的GI算法等;
● 渲染中去除噪點、減少采樣的方法;
● 物體材質的參數模型和參數擷取等。
Lighting Grid Hierarchy for Self-illuminating Explosions
原文連結:http://www.cemyuksel.com/research/lgh/lgh.pdf
示範視訊:https://www.youtube.com/watch?v=nWEPCU2d0WI
模拟爆炸、煙霧或者位置動畫很多盞點光源的光照和陰影效果是個難題,因為渲染時間往往随光源的數量成倍增加。本文的基本思想是,将煙霧或多盞點光源的位置作為輸入,得到各級粗分網格中的點光源的亮度和位置,用這些點光源的融合來計算光照資訊,減少了計算量。

遊戲中爆炸後煙霧的動畫中往往很難模拟煙霧對環境的光照效果,因為光源的增加會造成計算量激增;
在多盞點光源情況下,動态陰影和半透明效果也是問題;
lightcut方法将衆多點光源轉換為層級樹的方法,存在bias問題。
本文将煙霧或多盞點光源的位置作為輸入,然後逐漸變成網格中格點的點光源,使用了傳統的線性融合的方法來做不同層級的格點光源的光照融合,在每幀點光源變化時,更新所有層級格點的光照,使用cube-map來模拟陰影,對于層級較高的格點(就是粗略模拟的光照)使用體積光源模拟,對于煙霧中存在的multi-scattering間接光照效果,本文使用了增加虛拟光源的方法來模拟。
優勢:1)在渲染下圖中的爆炸效果時,使用了1.4百萬的點光源,計算網格耗時273秒,光照計算耗時320秒;在渲染下圖中的多個點光源和半透明的SIGGRAPH字型時,使用了2.2萬盞點光源,計算網格耗時20秒,光照計算耗時30秒。測試平台為dual Intel Xeon E5-2690 v2 CPUs (20 cores total) and 96GB記憶體。效果很好,速度也比較快。2)沒有lightcut方法中存在的幀與幀之間的閃爍問題;并且速度快了幾個量級,在爆炸煙霧渲染中,lightcut方法需要2個小時來渲染。3)使用的都是傳統的算法和方法,比較可靠。
不足:1)仍然無法避免VPL算法本身存在的漏光問題;2)如何在gpu上或者實時渲染中利用該技術,本文沒有提及,但是方法上并沒有限制,估計陰影貼圖(.5GB-1GB的貼圖量)的生成會比較耗時和消耗帶寬,不過在實時渲染中可能也不需要用這麼多盞點光源來模拟,值得嘗試。
用于遊戲動畫中篝火、爆炸等動态體積光源的模拟,或者飛舞着很多螢火蟲的洞裡的光照效果。
Interactive Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder
原文連結:http://research.nvidia.com/sites/default/files/publications/dnn_denoise_author.pdf
示範視訊:https://drive.google.com/file/d/0B6eg_ib7k4PoaVhWN3VYRHo0NDQ/view
渲染中如何在不增加采樣的情況下降低噪點一直是研究的熱點,本文采用機器學習的方法,使用CNN網絡來編碼資訊,然後用RNN網絡來降低連續幀之間的噪點,在間接光上取得了不錯的效果
最簡單的降噪方法是增加采樣數,缺點是造成渲染時間成倍增加;
傳統機器學習(比如線性回歸)方法來降噪,但是因為噪音來源比較多,比如有材質高頻信号、複雜幾何體(比如頭發)、間接光照(全局光,multi-scattering),以及景深和運動模糊等,是以很難有一個統一的方法或者統一大小的filter寬度來對資料進行處理。
NVIDIA在optix架構基礎上嘗試使用深度學習的方法實時的對圖像去噪點,對于僅考慮單次間接反射/折射的渲染畫面,保持了edge等高頻信号,同時在連續的渲染畫面中取得了較好的降噪效果。技術上使用CNN+Skip connection來做encoder,然後再decoder,中間使用rcnn結構抑制連續畫面中的閃爍。
優勢:達到20fps左右的實時渲染速度,僅使用1spp的間接光照采樣,在保持邊和陰影等高頻信号的同時,去除了噪點且沒有引入疊影等,做到了較為不錯的全局光照和陰影效果。
不足:1)為考慮複雜幾何體,景深和運動模糊的情況,2)輸入畫面本身是每像素一個采樣點的噪音較大的渲染畫面,沒有示範對于噪點較小的渲染畫面的處理結果,3)訓練中使用的是128128的畫面,網絡較小,decoder時是采用上采樣來做到的,是以最後輸出畫面尺寸也是128128,後續也許擴充到了更大的網絡;4)不能處理光線的多次反射/折射,場景中有鏡子,杯子等時,會有問題。5)optix是nvidia開發的一套運作在gpu上的光線追蹤渲染架構,是以本文使用的環境,并不是遊戲中所用的opengl或dx管線。
在将來也許可以用于提升遊戲的畫質,但是對于電影等要求較高的渲染可能還不行。
Modeling Surface Appearance from a Single Photograph using Self-augmented Convolutional Neural Networks
原文連結:http://msraig.info/~sanet/sanet.pdf
示範視訊:暫時沒有
Xin Tong在MSRA一直在做材質方面的工作,國内該領域做的最好的組,去年他做的SIGGRAPH工作仍然是使用傳統的基于多張照片或視訊的受限制的二次規劃/優化方法,這是他們組第一次嘗試使用CNN深度學習的方法來做。
為了擷取真實物體的材質資訊,往往需要使用的巨大的球形照相機群,不能廣泛采用;
用資料拟合的方法,需要從多個角度拍攝多張照片,或者拍攝一段物體旋轉下視訊資訊,光照需要保持恒定,比較費時。
本文試圖從單張照片估計出物體的SVBRDF資訊,作者使用了兩個深度神經學習網絡,分别用來估計統一的高光模型參數(Ward模型,也可以改做其他的,比如遊戲中常用的ggx,左圖)和随空間位置變化的漫反射模型參數和表面法線(右圖)。
為了增加樣本數量,作者使用了一種稱為Self-augmentation的訓練方法。對于輸入的無标記照片,首先使用監督方法訓練好的模型估計出SVBRDF參數,然後使用該參數,在CG軟體中變換光照和視角,渲染出一張新的圖檔,然後再次利用深度網絡估計出新的SVBRDF參數,以兩個SVBRDF之間的偏差作為loss。
優勢:僅需要一張照片就可以獲得物體的SVBRDF資訊,算是目前最為簡化的BRDF擷取方式了。
不足:1)對于每一種材質,需要一個對應的神經網絡,不同材質間無法通用,神經網絡的泛化性比較低;2)對于照片有不少限制,比如物體需要是平面的,且光源需要離物體較遠,認為類似于平行光源;3)如果高光變化較大,那麼估計出的參數會不準确;4)在實際生産中,一般很少考慮BRDF随空間位置變化的情況,是以模型上應該可以進一步簡化。
他們組的一些論文,不限于這篇,可以用于使用手機等裝置快速擷取物體的BRDF資訊,進而在遊戲中建立出更加真實的基于實體的渲染效果。
虛拟現實/增強現實(VR/AR)
虛拟現實或增強現實領域是目前的産業和研究熱點,包括以下細分領域:
● 周圍環境的三維重建以及使用者在環境中姿态的實時定位(SLAM)
● 減少VR眼鏡造成的眩暈感
● 三維物體或角色本身的識别、掃描、重建和傳輸
● 針對全景圖的渲染優化和傳輸優化
● 從環境照片中擷取環境中的光照分布等
BundleFusion: Real-time Globally Consistent 3D Reconstruction using Online Surface Re-integration
原文連結:https://arxiv.org/pdf/1604.01093v1.pdf
示範視訊:https://www.youtube.com/watch?v=keIirXrRb1k
作者使用常見的深度攝像頭,采用層級結構進行SLAM建構,做到了環境模型的實時重建和修正,以及錄影機姿态的準确恢複和實時的閉環修正,基本思想是在連續的11幀内做跟蹤,并篩選出穩定的特征,然後在以11幀為機關的整個序列幀上做閉環修正,降低了閉環修正發生的頻率,并去除不穩定的特征資訊。
之前的方法多采用bundle adjudgement來修正軌迹,確定錄影機能夠回到原點,修正錄影機位置估計中的漂移誤差,但是這種方法往往需要消耗較多的計算時間,無法用于實時的任務;
因為錄影機動的太快,或者被遮擋,會造成跟丢的情況,錄影機恢複後的位置不易确定。
作者使用常見的深度攝像頭,采用層級結構進行SLAM建構:1)連續的11幀組成一個塊,在這個塊上,作者使用SIFT特征點來做錄影機姿态跟蹤,并輔助以特征點的分布、縮略圖中的點位置資訊,完成該11幀時間範圍内的姿态修正,并将新的深度資訊及時更新到三維重建的模型中,将連續穩定的特征點整合在一起;2)在chunk之間(不是每幀都執行),再對一些關鍵幀進行全局優化,同時考慮穩定特征點、voxel的位置資訊和法線資訊在不同錄影機姿态下的對比,使用PCG方法做大規模稀疏矩陣(105k行,5k列)的方程求解,并根據全局優化前後的錄影機姿态差異,來決定是否将該幀資料從三維重模組化型中去除,最後進行ICP修正更新三維模型。
優勢:使用單個普通的錄影機做到了實時(30FPS)、穩定、閉環的大場景三維重建和錄影機姿态位置定位,并且模型的準确率和之前offline的方法差别不大,而且不像之前的閉環處理方法,需要中斷或者在做bundle adjustment時有延遲。
不足:1)使用了i7 cpu,一個nvidia gtx titan x來做場景重建,一個gtx titan black來特征點的比對和全局優化等,計算資源要求比較高;2)在重建過程中,穩定特征點的差異會在全局優化過程中傳播到多個幀,是以場景模型會存在細微的不斷變化,同時作者在文中提到使用權重來更新三維場景模型,但是并沒有詳細叙述權重的算法,考慮到本文屬于SLAM中dense的方法,而不是sparse的方法,是以沒法獲得每個voxel的位置資訊的準确率或機率,是以更新的權重可能是人為設定的,這也導緻新的資料(不太可能和之前資料完全一緻,因為深度錄影機本身也存在噪點)會不斷更新之前的場景模型,盡管比較細微;3)作者在閉環處理上,仍然沿用了傳統的PCG優化方法,雖然算法上進行了改進,但是存在優化中矩陣規模随SLAM時間增加二次方增長的問題,雖然作者在limitation中沒有提及,但是在文中提到在做了10分鐘的SLAM後,優化矩陣有105k行,是以懷疑該方法在連續運作時間上存在限制。最新的基于sparse的方法isam2,使用樹結構和機率做閉環處理,避免了這個問題,可以考慮和該方法的結合。4)因為使用結構光,是以不大可能在戶外使用;5)已經有用于影視previs制作的攝像頭位置姿态跟蹤解決方案,比如ncam(http://www.ncam-tech.com/),使用sparse的方法,非常準确穩定,但是缺少本文對環境的三維重建。
可以用于ar/vr領域,可以快速完成室内場景環境的掃描模組化,且同時不受空間限制的擷取目前位置和姿态資訊(htc vive限制在4*4的範圍内)
Real-time Geometry, Albedo and Motion Reconstruction Using a Single RGBD Camera
原文連結:http://www.guokaiwen.com/main.pdf
示範視訊:https://vimeo.com/210761032
本文的基本思想是,運動物體的三維模型資訊和材質資訊可以互相輔助,輪流優化,進而在使用單一深度攝像頭的情況下完成動态物體的三維重建和材質掃描。
有些方法依賴于一些預備工作或假設,比如人體的骨骼或身體的掃描;
有些方法依賴于多個攝像頭的融合處理,無法做到實時;
多數方法沒有做到同時恢複被跟蹤物體的三維模型和顔色資訊。
作者使用voxel來表示非剛體,利用cvpr15論文dynamic fusion中的節點來控制物體的形變,先根據物體表面的顔色和光照資訊(用SH來表示低頻變化的光源)來估計voxel的運動,然後再根據前後幾幀的運動資訊來更新物體表面的顔色資訊,在優化求解中使用了改進的PCG方法,并且對于發生碰撞的voxel(比如在衣服或袋子口合上的時候)不做更新,進而獲得不錯的跟蹤效果,并能得到物體靜态時的形狀和顔色,FPS能到30幀左右。
優勢:不需要任何事先的準備工作,使用一個普通的深度攝像頭,就可以做到非剛體的動态的捕捉和模組化,并且包含了物體的顔色資訊,比如穿裙子的人物,或者書包等任意形狀的物體。速度在4-core Xeon E3-1230和GTX TITAN X上做到了30fps,精度在厘米級别(動态)。
不足:1)該方法假設物體表面是一緻的漫反射,對于有高光反射的物體會存在問題;2)物體的重建精度受限于深度攝像頭的精度;3)因為深度攝像頭的幀率限制,是以對于快速運動的物體,因為幀與幀之間voxel變化大,以及存在動态模糊,會造成瑕疵;4)對于拓撲結構發生變化的物體,會存在模組化上的問題;5)因為本文使用了voxel來表示物體,是以在網絡傳輸時帶寬要求比較高。
可以用于vr/ar領域的互動,比如類似微軟Holoportation(傳送門)的效果,讓遠在千裡之外的親人和家人互動。
Accommodation and Comfort in Head-Mounted Displays
原文連結:http://www-sop.inria.fr/reves/Basilic/2017/KBBD17/SIG17_accommodation.pdf
示範視訊:https://www.youtube.com/watch?v=0vMbiu2llQY
VR體驗中會出現眩暈感,部分是由視覺輻辏調節沖突(vergence-accommodation)造成的。作者結合自動曲光計和可調節焦距的鏡片,來測量人眼對不同遠近的VR物體的刺激反應,得出目前解決VA沖突的三種方案哪種更為舒适。
目前提出的解決方案有,景深渲染,可調焦鏡片,monovision。但是缺乏資料去驗證哪種方案更舒适。(monovision的原理介紹https://www.vrlife.news/monovision-improving-vr-experience/)
下圖分别為硬體原理圖,使用自動曲光計測量人眼的對焦點,用可調節焦距的眼鏡去比對人眼對不同遠近物體的刺激響應。
優勢:作者經過實際測量發現可調節鏡片能比另外兩種方法得到更為準确、也更舒适的VR呈現效果,為将來發展更好的VR顯示裝置提供了方向。值得進一步關注。
不足:目前假設眼球是不動的,如何配合眼球追蹤技術,可以得到更好的效果。
更為舒适,眩暈感更少的VR顯示裝置。
O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis
原文連結:http://wang-ps.github.io/O-CNN_files/CNN3D.pdf
本文使用了類似openvdb的思路,對三維資訊進行壓縮,并且使用平均的法線來表示voxel中三維特征,在三維物體識别、segmentation、形狀提取等方面有應用價值。
現在獲得物體的三維立體掃描資料越來越友善,比如RGB-D攝像頭、結構光掃描裝置,三維模型資料越來越多,但是如何從資料中提取物體特征資訊尚無定論;
三維資訊的記憶體占用和計算量随三維物體尺寸的三次方增加。
使用了類似openvdb的思路,對三維資訊進行壓縮,僅存儲非空的voxel資訊。使用shuffle key來編碼voxel的序号,使用Lable數組來存儲目前層中哪些voxel是被物體表面占據的,然後采樣物體表面的點的法線平均值作為目前voxel的特征,最後進行3d-cnn的計算。
優勢:1)在計算時間和記憶體占用上,相對不壓縮的方法有近10倍的提升,且在物體識别和segmentation上和之前的方法準确度基本一緻。2)對于将來如何利用cnn處理巨大的高精度的三維資訊提供了更好的基礎,比如去噪點、相似性比較或場景分析。
不足:1)如果針對物體的不同部分的幾何特征,采用不同的voxel尺寸,可能會進一步提高效率;2)本文僅考察了3d-cnn網絡,對于深度學習中的其他重要網絡,比如rnn,resnet的結合應用還沒有研究,可能會有新的突破。
【應用落地】
大場景或高精度模型的去噪點、識别或者segmentation。
NEXT技術快報:快速掃描學術/技術前沿進展,做出必要的分析歸納,尋找它們在産品中落地的可能性。希望能幫助大家了解前沿,拓寬視野,提高決策效率。