最近在做X項目的時候用到了彈性搜尋引擎ES(Elasticsearch),在檢索遇到了一個詭異的問題,當存儲(長)整型資料超過某個值(具體就是百萬),就會出現資料精度丢失的情況,比如put下面一個資料
然後get出來,發現uid被轉成科學計數,存在精度丢失問題,uid在系統表示使用者的身份,出現了偏差導緻非常嚴重的後果,而浮點型資料卻沒有影響。
項目中首次采用ES,之前對這個搜尋引擎了解不多,是以最開始懷疑資料是在搜尋引擎那裡轉壞了,先查資料,後求達人,都沒有找到答案,由于ES提供Restful接口,走HTTP協定,通過抓包最後發現get時候資料并沒有被修改,那肯定是邏輯代碼問題喽。
服務架構采用SRF,存儲在ES的資料格式為JSON,編解碼使用的是SRF架構的TC庫,這個庫在背景多個項目中使用過,之前一直都沒有遇到過問題,最開始也沒有懷疑到它,走了一段彎路。經過定位發現是将json對象轉發string的時候出現了資料的改變,如下面的紅框代碼,出問題就是這一行代碼。(這裡為了友善其它服務通路ES,封裝了一個通用的增删改查的SRF接口進行RPC調用)
走進SRF架構代碼,發現TC_Json将所有number資料對象按照double去處理,這樣其實也是合理的,但是在轉換成string的時候卻用了 ostringstream,用流算子做轉換的時候會區分資料類型,當資料是整形的時候問題不大,如果是浮點型資料會出現資料被截斷,流算子預設按float型資料去處理,這是資料被篡改的原因。
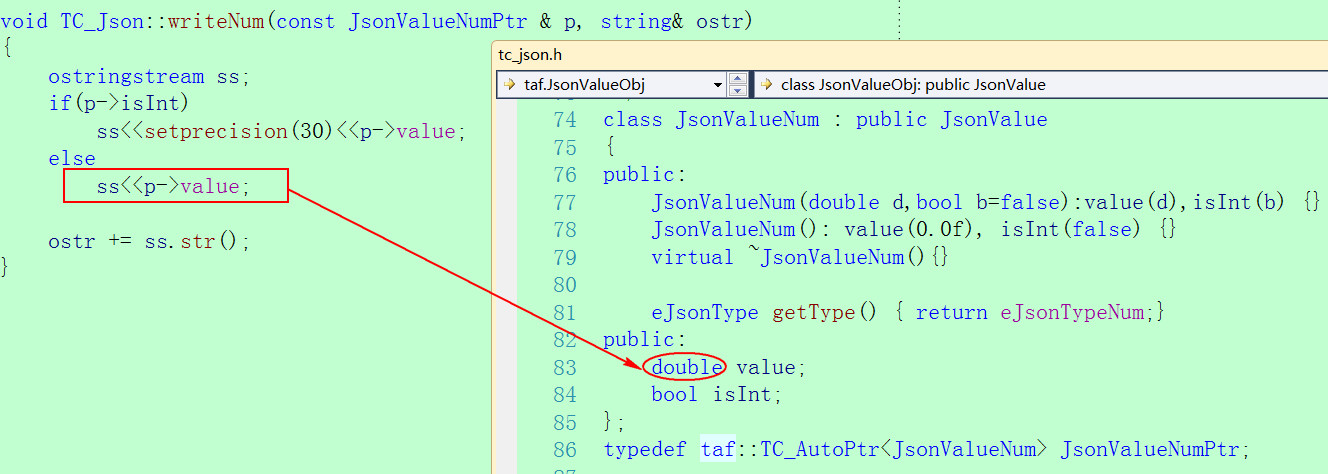
問題是資料并不是浮點型,而是整形,而正常用Jce結構體的時候整形轉換成json字元串并沒有問題,這又是什麼原因呢?分析釋出正常使用Jce對象的時候都會指定資料類型格式,而TC_Json做解析的時候并沒有這樣子去做(如下源碼),也就是說如果使用TC庫去解析json,然後再回寫成string,出現大整數或double資料則會出現精度丢失。
2.1 TC_Json優化
找到了問題原因,解決起來自然就很容易,TC_Json在進行資料解析的時候指定對資料類型進行指定,避免整形資料轉成string當成double型,這樣改完之後整形資料再也不會有問題。
2.2 Double精度問題
改完之後整形資料自然就沒啥問題,但是我們知道在計算機系統中,C/C++的浮點資料F/D分别占用32/64位,是按照指數+尾數方式存儲,精确範圍分别為小數點後6位和15位,采用流算子對double資料進行json轉換還是存在精度丢失的問題,雖說浮點型資料在邏輯服務開發工作中比較少用到,但是從架構的角度希望能有一個比較完美的解決方案。
之前miloyip老師講rapidjson實作的時候,他重點介紹了浮點型資料格式化處理問題,rapidjson處理地非常完美,但代碼實作略顯複雜,在這裡使用标準庫提供gcvt函數處理,基本能滿足我們的精度要求,代碼實作也會顯優雅很多。
SRF/TAF架構提供了一些公共函數實作Number到String的轉換,大量都采用流算子實作,大家在日常的業務代碼開發中,用它處理浮點型的資料要十分注意資料精度丢失問題。