最近手頭開發維護的一個輔助小工具經常接到投訴可用性問題, 于是抽時間定位了下, 一看吓一跳, 起初不起眼的一個元件的日志量直接翻了兩個數量級。 這怎麼吃得消 ! 幸好當時工具是Go寫的,Go的周邊工具集還是挺豐富和友善的,于是開啟了調優之路。
首先簡介一下騰訊雲CVM-CGW元件的日志查詢工具, 之前為了快速解決問題, 采用了straight forward的方案 : 實時從生産環節的機器進行尾随(tail -f)然後通過pipeline程式進行規則處理結構化 , 然後寫入到後端DB進行持久化 , 然後另外有個前端進行查詢,結構大概長這樣。
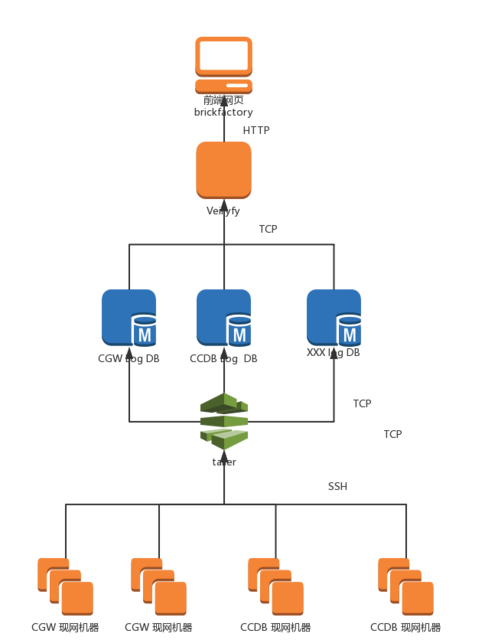
今天的問題主角是上圖的tailer程式, 它是日志收集和處理的核心部件。 日志系統營運到一段時間之後, 發現随着業務的增長, 請求量呈攀升之勢。 特别是現網廣州,上海,北京三個地域(國内使用者太熱情高漲了), 白天高峰期的時候會發現日志的寫入速度跟不上采集的資料.現象是現網剛剛産生的日志資料,到寫入DB存儲之間的時間差越來越長。導緻剛發生的請求需要等十幾分鐘才能查詢到, 以及每小時後面幾分鐘的日志查詢不到的, 現象如下圖:

tailer程式主要分日志采集, 日志解析處理,日志存儲三個步驟。
簡單列印調試分析了下, 排除了采集的性能問題.理論上這塊的IO資源是綽綽有餘的, 實踐方法是把收集到的日志馬上輸出到标準輸出, 然後和現網機器日志執行tail -f進行對比觀察, 可以觀察到兩者幾乎是同步輸出的, 不存在拖後腿現象。
然後是解析處理這個環節的排查, 排查效仿上一步驟, 把存儲的步驟換成輸出到标準輸出觀察, 觀察了十來分鐘發現基本和現網一緻。
于是重點改進存儲這塊的性能, 采取的辦法是把資料寫入DB行為從逐行寫入改為為批量寫入。 具體做法是把每行日志資料緩存下來, 使用LRU政策, 屬于同一個請求的日志的行,都會緩存到同一個key, 檢測到該請求的日志已經完了的時候,一次性把同一個請求的多行日志寫入DB.大緻邏輯是這樣。
原有的處理邏輯:
緩存政策後的處理邏輯:
具體代碼戳這裡
優化了批量寫入後很happy得部署運作, 跑了一段時間後,發現廣州的效率的确得到提升, 然而上海地域由于還沒擴容, 還是沒達到預期效果, 每小時還是有接近十來分鐘的間隔差距。 這時候肉眼和經驗派用不上用場了, 于是借助開源性能壓測工具來查找瓶頸。
火焰圖簡介
之前在 dondonchen 同學了解到了火焰圖這個工具, 它對程式的性能分析做了非常直覺的可視化工作.感受下它的樣子。戳這裡可以感受它的互動。
簡單介紹下怎麼看這個圖. 這裡用的是CPU火焰圖, 縱軸代表的是函數調用棧深度.越高代表調用棧越深,最頂層格子就是最後被調用的函數.。橫軸是由一系列格子按字母排序的.每個格子代表一個行數調用。最底層的格子是入口函數,一般是main或者啟動程序加載函數等。格子的寬度代表該函數執行的CPU時間占用比例.最後圖的顔色預設是沒什麼含義的,可以當作色盲測試。更多原理和細節可以看Brendan Greg這篇pptt以及源碼..ps,作者的blog是個學習linux系統實戰知識的寶礦。
原生火焰圖生成工具使用起需要各種工具一起上, 研究了一圈最後選了uber開源的壓測工具go-torch, 支援各種可視化圖表. 使用起來非常友善.
隻需要在import的地方加上<code>_ "net/http/pprof"</code>和程式入口加上兩三行代碼即可.
然後啟動tailer程式, 然後運作go-torch對程式進行無情的鞭策。
最後在目前目錄生成了一個torch.svg檔案, 在浏覽器打開,即可調用棧火焰圖。
從圖中可以看到主要作業函數doTailFOverSSH所占用的比例大約是三分之一.這裡右邊的三分之二主要是sleep的系統調用,和tailer程式的主要幹活負載程序無關. 這種svg格式的火焰圖還帶有互動功能, 滑鼠點選doTailFOverSSH的格子,即可展開函數放大觀察.
可以觀察到doTailFOverSSH裡面有一半時間阻塞在網絡資料接收排程上runtime.selectgo, 是以這又進一步驗證了采集端不夠成瓶頸并且綽綽有餘的肉眼觀測現象. 另外占一半時間的Process函數做的就是讀tail -f傳過來的每一行日志,然後進行處理(解析和存儲)ReadLine. 展開ReadLine進一步觀測.
可以看到ReadLine裡面的兩大步驟解析和存儲分别對應的是ParseLine和Save函數.可以看到改成批量後Save的比例已經隻占用不到1/5的時間, 主要瓶頸在于ParseLine. 而ParseLine的調用棧發現MustCompile兩座正則初始化大山. 于是猛然想到代碼裡面有類似于
這種日志格式固定,八百年不會改變的變量,不需要在每一行日志處理都進行Compile, 可以用全局變量進行提前初始化。另外一些變化較多但是量也有限的正則pattern也可以用緩存存起來避免重複初始化(MustCompile). 于是動手調整一把。
調整後ParseLine終于降下來了, 現在解析和存儲占用時間比例相對。
而Process在doTailFOverSSH的整體占用時間也降下來了.還多出不少空閑。
最後總覽全圖可以看到主負載函數doTailFOverSSH也從原來的三分之一降到15.68%, 不到1/6.
調整後程式再次上線運作,so far so good, 時間差距縮短到200ms以内(符合期望)。
目前可以輕松應付廣州,上海,北京等大地域的高峰期請求.目測應該可以撐到業務翻翻.期待下次瓶頸的到來。