Ckafka是基礎架構部開發的高性能、高可用消息中間件,其主要用于消息傳輸、網站活動追蹤、營運監控、日志聚合、流式處理、事件追蹤、送出日志等等需要高性能的場景,目前已經上線騰訊雲。
歡迎大家前往騰訊雲技術社群,擷取更多騰訊海量技術實踐幹貨哦~
作者:闫燕飛
1.背景
Ckafka是基礎架構部開發的高性能、高可用消息中間件,其主要用于消息傳輸、網站活動追蹤、營運監控、日志聚合、流式處理、事件追蹤、送出日志等等需要高性能的場景,目前已經上線騰訊雲。Ckafka完全相容現有的Kafka協定,使現有Kafka使用者可以零成本遷入Ckafka。Ckafka基于現有的Kafka進行了擴充開發和優化,為了友善使用者了解Ckafka本文也将對Kafka的實作原理進行較為詳細的介紹。
2.Kafka原理
2.1 Kafka誕生背景
Kafka是一種高吞吐量的采用釋出訂閱模式的分布式消息系統,最初由LinkedIn采用Scala語言開發,用作LinkedIn的活動流追蹤和營運系統資料處理管道的基礎。現已成為Apache開源項目,其主要的設計目标如下:
- 以時間複雜度為O(1)的方式提供消息持久化能力,即使對TB級以上的資料也能保證常數時間複雜度的通路性能。注:其實對于寫Kafka的確定證了O(1)的常數時間性能。但對于讀,是segment分片級别對數O(logn)時間複雜度。
- 高吞吐率。Kafka力争即使在非常廉價的商用機上也能做到單機支援100Kqps的消息傳輸能力。
- 支援Kafka Server間的消息分區(partition),及分布式消費,同時保證每個partition内的消息順序傳輸。注:其實Kafka本身實作邏輯并不做該保證,主要的算法是集中在消費者端,由消費者的配置設定算法保證,詳情下面會介紹。
- 同時支援離線資料處理和實時資料處理。
- 支援線上水準擴充,Kafka的水準擴充主要來源于其分區(partition)的設計理念。
2.2 主流消息隊列對比
| RabbitMQ | RocketMQ | CMQ | Kafka | |
|---|---|---|---|---|
| 模式 | 釋出訂閱 | 傳統queue/釋出訂閱 | ||
| 同步算法 | GM | 同步雙寫 | Raft | ISR(Replica) |
| 分布式擴充 | 否 | 支援 | ||
| 堆積能力 | 磁盤容量 | 磁盤(水準擴充) | ||
| 性能 | 中 | 高 | 很高 | |
| 可靠性 | 一般 | 極高 | ||
| 持久化 | 記憶體/硬碟 | 磁盤 |
2.3 架構
2.3.1 整體架構圖
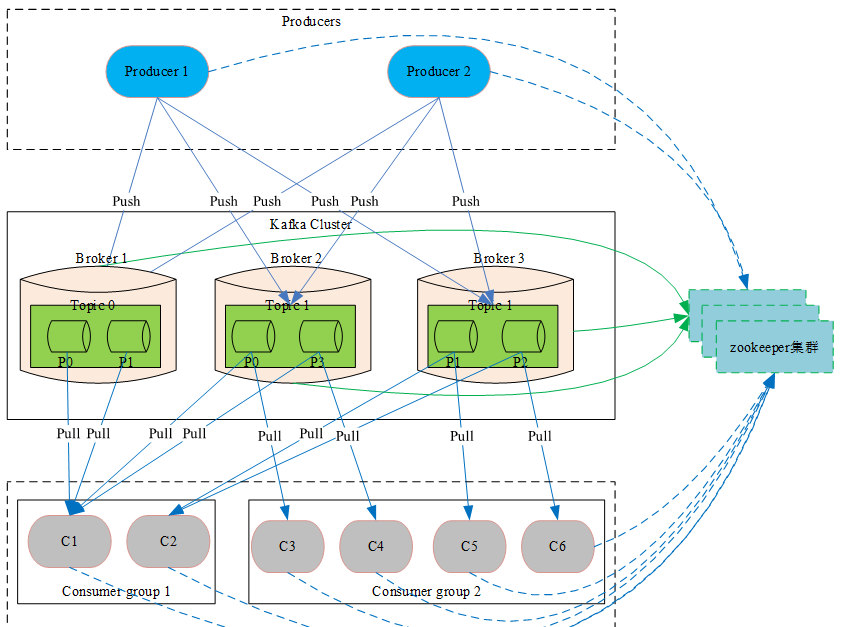
2.3.2 相關概念介紹
2.3.2.1 zookeeper叢集
Kafka系統強依賴的元件。其存儲了Kafka核心原資料 (如topic資訊配置、broker資訊、 消費分組等等,相當于DB充當了Kafka的配置管理中心) 。 Kafka的leader選舉(如coordinator選舉、controller選舉、partition leader選舉等等),同樣也會借助于zookeeper。
2.3.2.2 coordinator
coordinator協調器子產品,主要用來管理消費分組和消費offset,充當中介管理消費者并從消費分組中選舉出一個消費者作為leader,然後将消費分組中所有消費者資訊發往該leader由該leader負責配置設定partition。該子產品為Kafka 0.9版本新加入的新的子產品,Kafka叢集中可以存在多個協調器分别管不同的消費分組,提高整個系統的擴充能力,主要用于解決之前消費者(high level消費者api)都需要通過與zookeeper連接配接進行相關的選舉,導緻zookeeper壓力大、驚群及腦裂問題。
2.3.2.3 controller
controller子產品,主要負責partition leader選舉、監聽建立及删除Topic事件然後下發到指定broker進行處理等功能,整個Kafka叢集中隻能有一個controller,Kafka利用zookeeper的臨時節點特性來進行controller選舉。
2.3.2.4 Broker
消息緩存代理,Kafka叢集包含一個或多個伺服器,這些伺服器被稱為Broker,負責消息的存儲于轉發,作為代理對外提供生産和消費服務。
2.3.2.5 Topic
消息主題(類别),邏輯上的概念,特指Kafka處理的消息源的不同分類,使用者可以根據自己的業務形态将不同業務類别的消息分别存儲到不同Topic。使用者生産和消費時隻需指定所關注的topic即可,不用關注該topic的資料存放的具體位置。
2.3.2.6 Partition
Topic實體上的分組,在建立Topic時可以指定分區的數量,每個partition是一個有序的隊列,按生産順序存儲着每條消息,而且每條消息都會配置設定一個64bit的自增長的有序offset(相當于消息id)。Partition是整個Kafka可以平行擴充的關鍵因素。
2.3.2.7 Replication
副本,topic級别的配置,可以了解為topic消息的副本數。Kafka 0.8版本加入的概念,主要目的就是提高系統的可用性。防止broker意外崩潰導緻部分partition不可以服務。
2.3.2.8 ISR
In-Sync Replicas ,Kafka用來維護跟上leader資料的broker清單,當leader崩潰後,優先從該列中選舉leader
2.3.2.9 Producer
Producer 生産者,采用Push方式進行消息釋出生産。Producer可以通過與zookeeper連接配接擷取broker資訊, topic資訊等等中繼資料,然後再與broker互動進行消息釋出。在此過程中zookeeper相當于一個配置管理中心(類似于Name Server提供相關的路由資訊)。采用直接向Producer暴露zookeeper資訊存在以下兩個非常大的弊端:
- zookeeper屬于整個Kafka系統的核心結構,其性能直接影響了整個叢集的規模,故當暴露給生産者過多的生産者會導緻zookeeper性能下降最終影響整個Kafka叢集的規模和穩定性。
- zookeeper存儲着Kafka的核心資料,若公開暴露出去則容易受到惡意使用者的攻擊,最終導緻Kafka叢集不可服務,故非常不建議Kafka服務提供方向使用者暴露zookeeper資訊。
正因為存在上面的問題,Kafka也提供了Metadata RPC,通過該RPC生産者可以擷取到broker資訊、topic資訊以及topic下partition的leader資訊,然後生産者在通路指定的broker進行消息生産,進而對生産者隐藏了zookeeper資訊使的整個系統更加安全、穩定、高效。
2.3.2.10 Consumer
消費者,采用Pull方式,從Broker端拉取消息并進行處理。當采用訂閱方式(一般通過使用consumer high level api或new consumer來進行訂閱)訂閱感興趣的Topic時,Consumer必須屬于一個消費分組,而且Kafka保證同一個Topic的一條消息隻能被同一個消費分組中的一個Consumer消費,但多個消費分組可以同時消費這一條消息。
其實Kafka本身不對這個(同一個topic的一條消息隻能被同一個消費分組中一個消費者消費)做任何保證,尤其是在0.9版本之前Kafka Broker根本都沒有消費分組的概念也沒有消費offset概念,Kafka隻是提供FetchMessage RPC供使用者去拉取消息,至于是誰來取,取多少次其根本不關心,該保證是由消費者api内部的算法自己完成。
在0.9版本之前消費分組隻是消費者端的概念,同一個消費分組的所有消費者都通過與zookeeper連接配接注冊,然後自主選擇一個leader(一個消費分組一個leader),再通過該leader進行partition配置設定(配置設定算法預設是range,也可以配置成round robin甚至自己實作一個算法非常的靈活)。所有消費者都按照約定通路配置設定給自己的partition,并且可以選擇将消費offset保持在zookeeper或自己存。該方式會暴露zookeeper進而導緻存在和暴露zookeeper給Producer一樣的問題,并且因為任何一個消費者退出都會觸發zookeeper事件,然後重新進行rebalance,進而導緻zookeeper壓力非常大、而且還存在驚群及無法解決的腦裂問題,針對這個問題0.9版本(含)之後,Kafka Broker添加了coordinator協調器子產品。
但coordinator子產品也未進行任何配置設定算法相關的處理,隻是替換了zookeeper的一些功能,充當了中介将之前消費者都要通過zookeeper自己選擇leader, 變成統一和coordinator通信,然後由coordinator選擇leader,然後将同一個消費分組中的消費者都發送給leader(消費者api),由leader負責配置設定。另一個方面就是coordinator目前多了管理offset的功能,消費者可以選擇将offset送出給coordinator,然後由coordinator進行儲存,目前預設情況下coordinator會将offset資訊儲存在一個特殊的topic(預設名稱
_
consumer_offsets)中,進而減少zookeeper的壓力。消費分組中partition的配置設定具體可以看下一個小結中消費分組的相關說明。
2.3.2.11 Consumer Group
消費分組,消費者标簽,用于将消費者分類。可以簡單的了解為隊列,當一個消費分組訂閱了一個topic則相當于為這個topic建立了一個隊列,當多個消費分組訂閱同一個topic則相當于建立多個隊列,也變相的達到了廣播的目的,而且該廣播隻用存儲一份資料。 為了友善了解,通過下面的圖檔對消費分組相關概念進行講解。

- 一個消費分組可以訂閱多個topic,同理一個topic可以被多個消費分組訂閱
- topic中的partition隻會配置設定給同一個消費分組中的一個消費者,基于這種配置設定政策,若在生産消息時采用按照消息key進行hash将同一個使用者的消息配置設定到同一partition則可以保證消息的先進先出。Kafka正是基于這種配置設定政策實作了消息的先進先出。
- 同一個消費分組中,不同的消費者訂閱的topic可能不一樣,但Kafka的partition配置設定政策保證在同一個消費分組的topic隻會配置設定給訂閱了該topic的消費者,即消費分組中會按照topic再劃分一個次元。以上圖為例Consumer group1中C1和C2同時訂閱了Topic 1是以将Topic1下面的P0 ~ P3四個partition均分給C1和C2。同樣Consumer group1中隻有C1訂閱了Topic0故Topic0中的兩個partition隻配置設定給了C1未配置設定給C2。
2.3.2.12 Message
消息,是通信和存儲的最小機關。其包含一個變長頭部,一個變長key,和一個變長value。其中key和value是使用者自己指定,對使用者來說是不透明的。Message的詳細格式下面會有介紹,這裡先不展開說明。
下一篇:《高性能消息隊列 CKafka 核心原理介紹(下)》
相關閱讀
如何更優雅地使用 Redux
圖表元件常見設定
騰訊雲分布式高可靠消息隊列 CMQ 架構
此文已由作者授權騰訊雲技術社群釋出,轉載請注明文章出處
原文連結:
原文連結:https://www.qcloud.com/community/article/549934
海量技術實踐經驗,盡在雲加社群!
https://cloud.tencent.com/developer