騰訊雲 Redis(CRS)叢集版已經有數千使用者,售出數十T容量,那麼 CRS 是如何做配置管理的呢?通用的叢集系統都需要做配置管理分發,成員健康度檢查,希望能帶給您啟發。
CRS 叢集版改造自 QQ 背景存儲資料庫 Grocery,擁有十多年的技術積累與傳承,由 SNG 即通平台部公共元件組多年研發,資料營運部 DBC 組持續運維營運。目前部署有上萬台的叢集,每秒承受上億的通路。CRS 叢集主要是由管理機、接入機、存儲機三種角色組成。配置中心會部署在管理機上,配置用戶端則會部署在叢集的每台機器上。
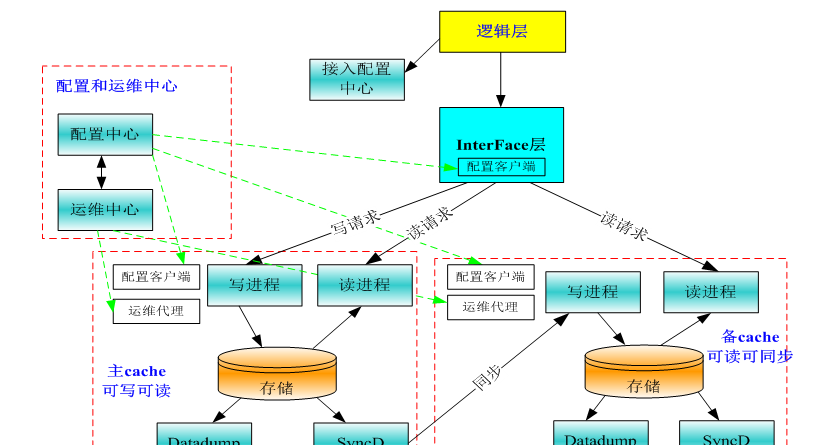
配置管理子產品,由上圖的“配置中心” 與 “配置用戶端”組成,是一套C++實作的CS架構。配置中心是一個單程序多線程架構,每個線程負責單獨的功能。配置中心程序啟動後,首先進行初始化,然後啟動各個工作線程。初始化的分析因為不是重點,是以放在文末。現在介紹各個主要的工作子產品:
配置加載:将配置資訊從DB加載到記憶體中 (DB-> 服務端配置)
存活更新:将VSERVER的存活狀态做改變 (用戶端狀态 -> 服務端配置)
篩選機器:篩選出需要接收配置的機器 (用戶端狀态 compare 服務端配置)
推送配置:将配置推送到指定機器 (服務端配置 -> 用戶端)
接收心跳:接收心跳并更新用戶端狀态 (用戶端 -> 服務端配置)

主要的角色:配置用戶端 <-> 配置中心 (用戶端狀态,服務端配置) <- DB
該子產品由一個獨立的線程LoadConfigThread實施,會把資料庫中最新的配置資訊加載到共享記憶體,加載前會有一些合法性校驗。
我們一般是如何來更新叢集的配置資訊呢?
a. 營運系統送出的 DML語句 更改DB中的配置資訊;
b. 執行 "<code>update config_state_t set cfg_seq=cfg_seq+1;</code>" 更新序列号;
該子產品的邏輯包裹在while循環中,循環間隔 sleep(1),這也就是說,當我們在db中更新配置後,大概1秒會加載到共享記憶體中;
線程會在DB中執行 "<code>Select need_load,cfg_seq From T_SYSCONF</code>",主要是為了取得<code>cfg_seq</code>這個序列号。(曆史上會用<code>need_load</code>字段的資訊,但現在已棄用,不作為需要加載的标志);
線程每讀一次MySQL,都會執行這麼一條語句,以更新最後一次讀MySQL的時間。<code>update T_SYSCONF set master_cc_read_db_last_time = unix_timestamp() ;</code>這是用于主備配置中心的當機切換判斷的。更新失敗上報 "646280 主CC設定最後讀db時間:失敗",更新成功上報 " 和 "646281 主CC設定最後讀db時間:成功"。我們通過<code>select from_unixtime(master_cc_read_db_last_time) from T_SYSCONF;</code>就能看到,每秒<code>master_cc_read_db_last_time</code>值都會被更新一次。
如果 <code>cfg_seq</code>已經與程序的全局變量 <code>g_ddwDbSeq</code>不同,則意味着需要把DB的最新配置資訊加載到共享記憶體中了,因為運維人員對Mysql中的配置資訊可能有誤操作,是以在加載到共享記憶體前,程式有嚴格的合法性校驗,以免取得錯誤的配置資訊,破壞叢集的安全。
那麼合法性校驗具體是怎麼做的呢?
a. 把所有配置加載到待更新的臨時配置中
b. 把數組兩個元素指向的配置,進行一個比對,這裡檢驗條件就非常多了,如新加的<code>server_id</code>與舊的<code>server_id</code>要行程等差數列,<code>server_name</code>相同的條目<code>copy_id</code>必須不同等等,這裡就不一一列舉。
配置合法性檢查不通過,上報"299726 配置中心裝載新配置時,因檢查不合格而拒絕裝載"。這是一個比較重要的上報,因為同時變量<code>g_bDbConfigIsValid = false</code>,後面介紹的[推送配置]子產品,如果發現該變量為false,則會終止推送,那麼諸如主備切換等新叢集資訊,也無法下發了,是以需要盡快處理。而我們的營運系統是通過看日志來檢測配置是否加載成功的。成功的話,sleep(10)後會把 成功日志寫到檔案中。
如果失敗,不用sleep任何秒數,直接就會寫失敗日志:<code>LOG_WATER_MUTEX(&g_stServerLog,_LOG_ERROR_, "LoadConfigFromDB Fail: iRet=%d", iRet);</code>
是以我們校驗加載配置是否失敗,隻需要在資料庫update seq後,過1秒後,檢驗日志檔案,是否同時出現了ERR以及LoadConfigFromDB 字眼,如果是,那麼就是加載配置失敗了。
假如配置的md5的确是發生了改變,那麼線程會生成一個配置包待下發,這是因為有時seq發生了改變不一定意味着配置有改變,是以還需看MD5。生成配置包失敗會上報"164304 load資料生成配置包失敗",成功會上報"182928 server啟動,生成配置"。
然後進行臨時記憶體結構體與運作記憶體結構體的切換,以達到啟用新配置的目的,
最後我們還會更新由新配置生成的md5資訊。
上述我們看到了ServerConfigsShm結構體,這裡我也把相關的需要參考的結構體一并列出。
// 管理所有配置資訊的資料結構
備注:叢集的一台實體存儲機,邏輯上會劃分為1個或多個VSERVER,每個VSERVER對于叢集就是一個獨立的存儲機,獨立提供服務,這有點虛拟化的意思。
該子產品由線程UpdateVServerStatusThread單獨實施,會跟進用戶端狀态清單中機器的心跳情況,來更新用戶端狀态,可能是從<code>WORKDING->OFF_WORKING</code>,或者從<code>OFF_WORKING->WORKDING</code>。改變狀态後,還會産生推送配置包并放置到推送隊列中。
邏輯包裹在while循環中,循環間睡眠間隔0.01秒,usleep(10000)
周遊每一個VSERVER,擷取其最後一次上報與目前的時間差距(秒),
如果 tInterval 已經大于某個伐值(如3分鐘):
如果目前該VSERVER我們記載是WORKING狀态,那麼我們就就要将其轉為OFF_WORKING了。
如果是OFF_WORKING,則什麼都不用做。
如果 tInterval 小于等于某個伐值(如3分鐘),這說明了已經有心跳上報了:
如果目前是OFF_WORKING,則轉為WORKING。
如果目前是WORKING,則什麼都不用做。
按照如上邏輯:死了的機器是過一段時間(可配)才會被置為DEAD,後面的請求才不會轉發到這,但機器如果複活了,可能不到1秒就能判斷其活了。這就是狀态轉換的時間差别。
從上述代碼我們能看出來,需要進行狀态轉換的VSERVER,都會把serverid被加到aiChangeServer數組中,所有serverid都加到aiChangeServer數組以後,我們就對該數組進行周遊,并且把對應VSERVER的狀态進行變換。
如果配置加載子產品,該線程最後會更新伺服器配置的MD5值,以及為新的配置生成配置包,并推送到隊列中。
線程 PushScheduleThread 負責篩選出需要發送配置的機器,從這裡我們知道,配置并不是需要推送到是以機器上的,而之後用戶端狀态的MD5與伺服器狀态MD5有差異時,我們才會推送配置給該用戶端。這個子產品主要就是用來篩選出需要接受配置包的機器。
業務邏輯都在while循環中,循環至少間隔2秒 : sleep(2)
擷取目前消息隊列 g_MsgHandle 中,未發送的消息數量(機器數量)有多少。這裡失敗上報"164324 推送排程,擷取消息隊列資料失敗",成功上報"164325 推送排程,消息隊列資料還沒有處理完"。
如果消息數量不為0,也就是上一輪發送還未完,那麼放棄本輪循環的操作,continue進入下一次循環。
如果消息數量為0,也就是之前的消息(機器)都處理完了,那麼我們這次就來看看,是否有需要接收配置資訊的用戶端。
把這個結構體推送至消息隊列 g_MsgHandle,START表明這裡開始新的一輪,宏定義如下。失敗會上報"推送排程cache,将cache放入消息隊列失敗"。
接下來還會執行
具體的邏輯是,周遊 interface 機器的用戶端狀态清單 pstInterfaceServerClientUpdateInfoList ,
如果發現其最後上報心跳時間逾時了,說明可能當機了,那麼将其上報md5置0,這樣MD5不一緻會導緻配置一直往其發送,這樣後續機器複活後也能獲得新配置。
如果發現最後上報心跳時間沒有逾時,比較interface上報的MD5與伺服器儲存的MD5;
如果一緻的話,說明無需推送interface配置已經是最新;
如果不一緻,那麼上報"184114 推送interface配置,client優先級較低",并将如下結構體壓入消息隊列,并且将該interface配置的最後推送時間置為目前時間;過程出現問題上報"164329 推送排程interface,将interface放入消息隊列失敗"
具體的邏輯是,周遊所有 cache 機器,擷取每個cache機器上的第一個serverid(一個機器可能有若幹個serverid),根據這個serverid,擷取該VSERVER的伺服器配置與用戶端狀态資訊。如果該機器目前是OFF_WORKING狀态,那麼很可能該機器就當機了,就将其MD5值置空,以防止機器重新開機後一直擷取不到配置的問題。這裡與上述周遊interface機器的機器的邏輯有點相似,但上述是要計算是否已經逾時,而cache機器本身就有WORKING與OFF_WORKING狀态,就不用再計算。
然後就對比伺服器與用戶端的MD5值,
如果一緻的話,說明無需向該CACHE推送配置,并且continue到下一個循環。
如果不一緻,則說明該CACHE需要擷取最新的配置了,我們把這個結構體壓進消息隊列:
壓入消息隊列成功後,還需要更新該ip下所有 VSERVER 的 最後推送配置時間 dwLastPushConfigTime 更改成目前時間。
如果上面的确有需要推送的機器被壓入隊列,那麼就把END與md5值壓到隊列中,否則把END與空的md5值壓入到隊列中。是以你猜到了,後面的[推送子產品],看到END這個cRole後,還得判斷MD5值是否全0,來判斷是否有要推送的機器。
這個子產品是将最新的配置資訊,推送到 [篩選機器]子產品中指定的機器上。這個子產品有個特點,為了加速配置的推送,會建立很多線程,數量根據配置檔案中的配置項 PushConfigThreadNum 來定(一般是200)
<code>PushConfigThread()</code>中具體的邏輯是什麼呢?
線程會不斷地循環,每次循環會固定睡眠0.01秒:usleep(10000); 然後會擷取消息隊列中的一個資料結構(消息結構如上),不能讀出(消息隊列為空),則sleep(1),讀出的話,解釋出其IP位址,再解釋其cRole字段。
如果cRole = START,這說明還沒有需要推送的機器,continue到下一個循環。
如果cRole = END,那麼說明本輪配置已經全部下發。這裡會比較這個消息結構的MD5與伺服器配置的MD5是否一緻,
如果不一緻(也就是全0的情況):那麼說明本輪其實并沒有需要下發配置的機器,continue到下個循環。
如果一緻,說明本輪确認是進行過機器的配置下發。那麼檢查一下配置推送的結果,主要看:
a. 成功推送配置的數量 ;
b.應該推送的數量,
c.沒有推送錯誤的數量,如果a小于b(很可能别的線程在發送并且未發送完),并且沒有c(錯誤量)的發生,那麼我們稍微等一段時間(可配)。最後将這三者的結果列印日志,以及入庫與上報Monitor等等。我們查問題是:<code>select cfg_seq,finish_time,success from T_DISTRIBUTE_STATUS</code>來看某次具體的下發是否成功,success是0代表成功,1代表失敗。
如果非START也非END,那麼向剛才解釋出來的IP,用戶端端口,推送配置。這才是最重要的。推送失敗上報"626449 推送配置到指定IP失敗",并且把對應error結果加1.如果成功,把對應success結果加1.推送成功,會記錄推送的耗時時間并上報。
"182940 server下發配置時間在0-1" //機關毫秒,書醒從182940至182956都是記錄推送時間的。
接《 騰訊雲 Redis 叢集版配置管理揭秘 ( 下 )》