爬蟲中常用JSoup處理Html,對于類似百度這樣的搜尋引擎,則需要配合fiddler使用,步驟如下
在IE浏覽器中打開http://www.cncorpus.org/CnCindex.aspx,使用fiddler抓取,如下圖
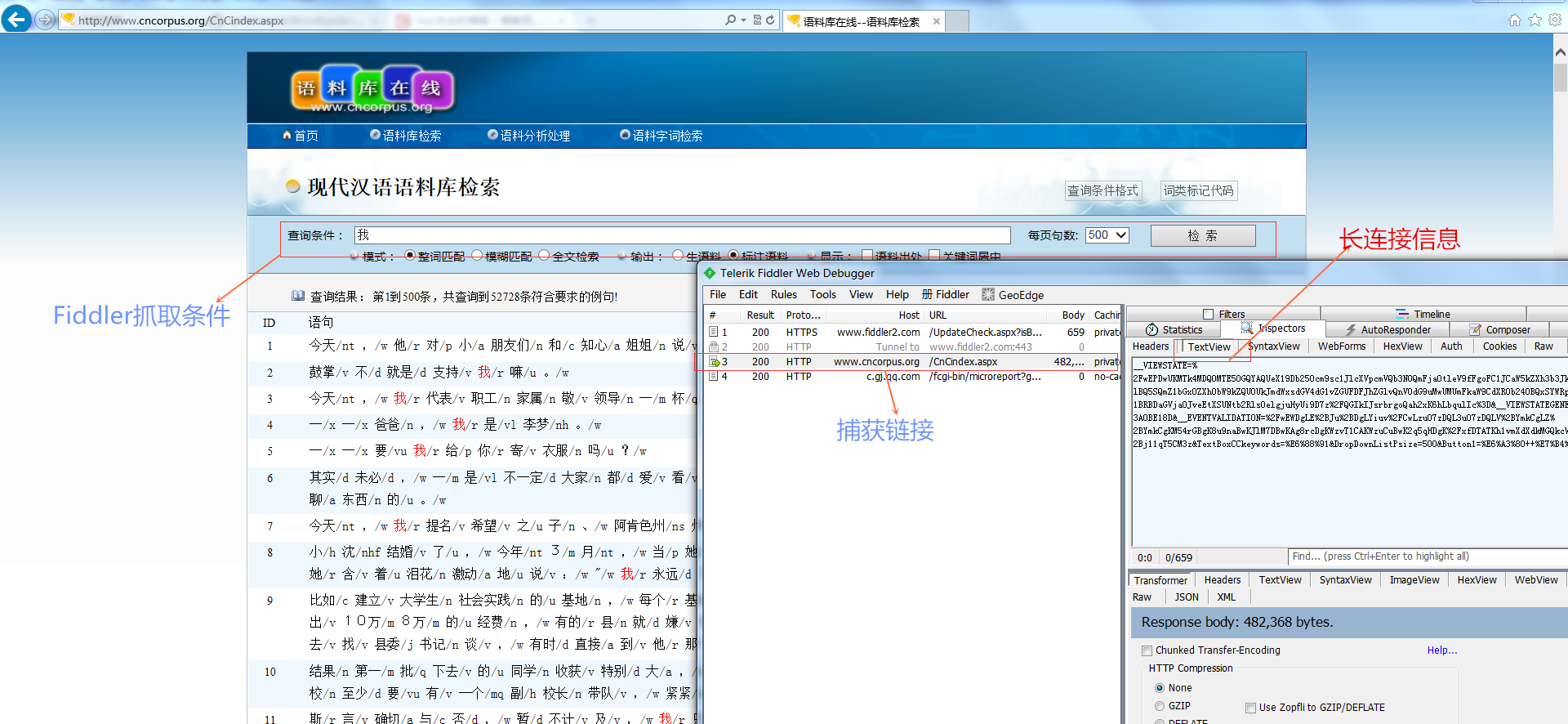
輕按兩下fidder中的捕獲連結,擷取整個連接配接資訊
然後在http://www.cncorpus.org/CnCindex.aspx
後加入捕獲的連結資訊
即
同理也可以擷取下一頁連結
這裡需要注意的是,下一頁連結需要填入查詢頁cookie
代碼如下
使用的時候,調用getCookie(findUrl)即可,其中findUrl是查找頁url
思路是把連結儲存到Html中,然後通過JSoup解析
這裡需要的包是jsoup-1.8.1.jar
儲存需要下邊兩個工具類
主程式如下,由于網址限制短時間通路次數,寫一個定時器,每隔20s爬取一次,代碼如下
抓取的html在htmlfind和htmlnext檔案夾下,結果儲存在result.txt中
