作者:鄒建平
随着網際網路業務的快速發展,基于傳統關系資料庫的資料存儲方案暴露了系統架構可伸縮性差、海量資料下性能存在短闆、資料模型過于複雜并難以調整等問題,而關系資料庫所提供的強一緻性、事務性、關聯操作在許多網際網路應用模型中并不是必須的,是以在新的場景下,去關系化的NoSQL資料庫應運而生。NoSQL資料庫具有高擴充性、高性能、靈活的資料模型、高可用等特點,其中的一大分支是key-value資料庫,key-value資料庫采用鍵值對的形式來組織、索引和存儲資料,具有簡單、易用、可擴充性好等特點。
而Redis作為key-value資料庫裡的最熱門的一員,在保持key-value資料庫的簡單快速的優點基礎上,具有一些部分關系資料庫的優點,例如資料結構豐富、操作原子性等特點。
Redis推出後具備諸多優點得以廣泛流行,目前高居kv資料庫熱度榜第一。
首先,Redis的資料全量儲存在記憶體中,采用單線程無鎖事件驅動的方式進行服務處理,協定上支援流水線批量和增量操作,無需像memcached那樣取出全量資料進行操作,是以具有相當高的性能;
再次,Redis提供多種鍵值資料類型來适應不同場景下的存儲需求,并借助高層接口使其可以勝任諸如緩存、消息隊列系統、排行榜、計數器等不同的業務場景,借助單線程工作方式,甚至支援部分的事務特性;
最後,Redis采用可讀易懂的協定接口,并支援了幾十餘種語言的用戶端庫,對開發者來說簡單易用,開源生态也比較活躍,目前大量公司采用它來作為緩存或者存儲系統,2015年以來大部分雲服務提供商都提供了相關存儲服務。
雖然Redis在資料結構和接口上簡單易用,但在業務實踐和運維過程中,還是存在不少的問題:
伸縮性不佳,業界普遍使用的原生Redis在架構上是一個單機存儲系統,當單機容量出現瓶頸時,分庫分表需要業務強參與,而且資料無法自動平滑遷移,許多時候都需要停服進行資料遷移;同時,單線程既是Redis系統的一個獨特的優勢,但也成為性能瓶頸,一個執行個體容量再大,單線程也限制了它所能提供的性能;
全記憶體的部署方式,性能雖然不錯,但一方面,資料都在記憶體裡,無法區分冷熱資料,而在網際網路應用中,大部分業務資料模型都有冷熱之分,另一方面,記憶體相比磁盤容量更小,無法實作大資料量的存儲,這點也成為Redis機關資料存儲成本居高不下的罪魁禍首;
Redis本身雖然通過RDB和AOF來實作資料持久化和主備同步,但實作的方法比較粗犷,RDB是通過fork一個子程序,通過周遊目前記憶體裡的資料生成dump檔案,這中間依賴系統調用fork的記憶體Copy-on-write機制,如果業務的寫量較大,則可能導緻OOM,另外在大記憶體程序進行fork存在卡機的現象,對使用者通路服務品質會造成影響;AOF,是增量流水落地磁盤檔案,因為該操作是在主線程中執行,是以如果IO出現問題,會對服務品質造成比較大的影響,此外,寫量大的時候,也會觸發流水的rewrite機制,這時也會造成IO堵塞,進而引起比較嚴重的性能問題。
業界也有一些解決方案來解決redis單機版的擴充性問題,例如twemproxy和codis,他們采用了代理節點進行資料分片的方式來連接配接後端多個redis伺服器,而redis cluster采用了去中心化的方式組成redis伺服器叢集。
但這些方案基本上都是在單機版的基礎上實作了分片機制,而并沒有解決redis單機版本身存在的問題,主備同步機制仍然借助RDB、AOF等機制,容易造成性能颠簸;另外,這些叢集版在運維能力的建設方面也比較缺乏,例如監控、上報、單系統的多執行個體化、運維自動化等。redis cluster的去中心化方式,雖然少了代理節點一跳,但需要更改用戶端代碼,而且該實作方式還不夠成熟,業界還缺乏最佳實踐。
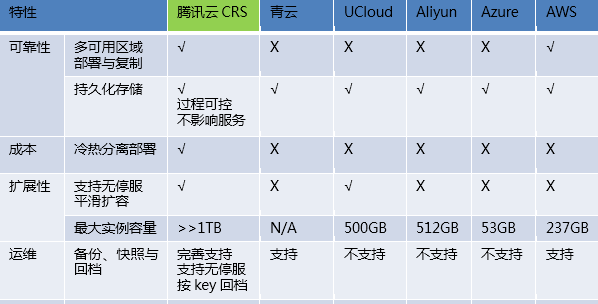
CRS (cloud redis store)是騰訊雲推出的相容開源Redis協定的分布式雲存儲産品。該産品基于承載QQ日均萬億請求的Grocery存儲平台,在Grocery原有的高可用、高可靠、高擴充性的分布式資料引擎架構基礎上,引入了Redis的資料結構和協定支援,實作的一個分布式Redis存儲平台。
CRS突破了單機版容量限制,能為客戶提供海量的存儲,支援單執行個體多達上百TB的存儲量;接口上相容開源Redis協定,業務代碼無需更改就可以輕松接入;在Redis分布式解決方案中獨創地支援分布式事務處理能力和批量處理指令;并提供了友善易用的平滑遷移工具,能夠将使用者原有的Redis資料無縫遷移到CRS;便捷易用的控制台,能夠友善實作多元度監控、資料導入導出、無停服擴容等管理運維操作。
CRS依托于支撐QQ海量使用者的Grocery存儲平台,支援5個9高可用的跨IDC、跨地區的多拷貝部署機制,以及可持久化存儲,資料存儲穩定可靠;所有節點都無單點故障,能夠在數秒内進行故障屏蔽與恢複服務;具有高可靠的備份和流水機制,能夠按需将全執行個體或部分資料恢複到任意時刻的狀态;提供記憶體與SSD兩種存儲媒體,并支援兩者的自動冷熱分離功能,為客戶提供更低成本的存儲方案。
CRS系統将資料的存儲和使用者的接入分開,同一個使用者的資料分布在多台機器上,進而突破單機記憶體容量的限制;同時,多個使用者的資料,儲存在同一台機器, 通過一定的政策,隔離多個使用者,避免使用者之間互相影響。 如下圖所示,整個系統包括如下幾部分:
•線上存儲系統: 接入叢集、存儲叢集和導入導出服務;
•資料高可靠系統: 主備同步子產品、流水系統和冷備中心;
•運維監控系統: 日志中心和多元監控系統;
•支援系統: 任務中心、配置中心和路由系統。

其中核心線上存儲系統是基于Grocery存儲平台進化而來。
下面先從Grocery的業務現狀、曆史版本變化、技術特點再到redis引入的改造優化技術點來介紹CRS的架構特點。
Grocery是專門針對即通業務資料輕、通路量大、容災要求高等特點,在QQ資料系統、QQ關系鍊系統基礎上開發的更抽象、更通用的NoSql存儲系統,具備資料類型和操作接口豐富、可多地部署、可線上周遊等多種優勢。
目前Grocery已經在深圳、天津、上海、加拿大部署了4000+機器,承載了300+業務,總資料存儲量達到250T,每秒峰值通路量達到4500萬次,每天通路量達到2.6萬億次。從服務啟用至今,平均服務可用率達到了99.999%。
從2011年11年釋出了Grocery第一個正式版本到現在,Grocery經曆了幾次大的優化裡程碑:
2012年4月,支援了批量操作、對使用者側API進行了優化,并通過合并寫binlog提升了寫性能;
2012年8月,支援了跨地區的異地部署能力;
2013年6月,支援平滑擴容與多系統間平滑遷移運維能力;
2013年底,支援SSD存儲媒體的Grocery版本釋出;
2014年6月,支援全球部署,并有登入相關業務實作了深圳、天津、上海、加拿大四地多拷貝部署;
2014年底,實作了多叢集自動化管理平台,能夠一鍵實作部署、擴容、遷移等常見運維操作,同時也優化了自動故障處理流程,很好提升了運維效率;
2015年6月,實作了公共倉庫部署模式,冷熱分離,并優化了存儲組織結構、尋址方式與同步機制,将單機讀寫性能提升了150%。
如下圖所示,Grocery系統由接入層、資料存儲層和配置運維中心三大子產品組成:
接入層(interface):負責和使用者的用戶端直接通訊,無狀态,可無限擴充;
資料存儲層(data-svr):負責存儲使用者的資料,支援多拷貝之間的同步,以及平滑擴容;
配置和運維中心(config-svr):負責管理、下發配置資訊,管理、排程運維指令,以及告警監控等功能。
Grocery中存儲的資料按主key在叢集中以一緻性hash算法進行分布,一緻性hash算法擁有無限平行擴充、消除熱點、最小化遷移量等優點,算法根據主key的hash值,将其落在某台機器所屬的虛節點上,以此來決定其所在機器,示意圖:
Grocery使用自研的改進割環算法來決定各機器節點在環上的位置,根據此算法的計算結果,可以在保持每台機器隻有20個虛節點的前提下,支援至5000台伺服器,同時保證各機器key數量和負載的最大偏差<5%。
3.3.2.2. 同步機制和異地部署能力
Grocery的資料可同時存在于多個拷貝中,采用一主多備的結構,最多支援12個拷貝(1主11備)。資料的所有改變由主機實時同步給備機,支援增量同步、全量同步以及全量資料恢複等同步機制,備機可分攤讀請求,支援異地部署以提高客戶讀請求的響應,非常适合讀多寫少的場景。主備叢集的狀态由運維中心統一監控管理,在出現同步差異過大、當機等情況下可實作秒級的狀态切換和服務恢複。
3.3.2.3. 資料解析插件機制
Grocery在傳統的Key-Value存儲基礎上,對Value做了各種資料結構的擴充,其中資料結構和其存儲引擎是分離的,即Grocery系統架構部分隻負責資料的存儲、落地、同步、擴容等基本操作,具體到涉及Value的結構的操作,則是通過編寫插件完成,隻需要實作幾個簡單的接口并向系統注冊動态庫,即可給Grocery增加新的資料結構處理功能,例如,我們可以讓Grocery對外提供Redis、MongoDB甚至SQL接口進行通路,而不需要改動它本身的主體引擎代碼,隻需新增幾個動态庫即可,插件機制給了Grocery極強的功能擴充能力,将Grocery和其他資料庫的特性有機地結合在一起,也給使用其他資料庫産品的使用者接入Grocery提供了很大的便利。
3.3.2.4. 資料存儲媒體
在Grocery中,不但存儲引擎和Value資料結構是分離的,資料處理邏輯和具體的落地方式也是不耦合的,Grocery邏輯處理隻關心抽象資料本身,具體資料的存放則交給下層的庫來做,是以理論上資料可以存放在記憶體、磁盤甚至遠端的其他資料庫引擎,目前實作了存放于記憶體和SSD磁盤的落地方式,配合資料的冷熱分離算法,可在保證足夠的通路性能前提下極大壓縮成本。
3.3.2.5. 冷熱分離
因為業務場景的關系,使用者的資料,總會有通路密度的差别,某些資料比較“熱”,可能會連續多次的讀寫通路,某些資料比較“冷”,可能會幾天都得不到通路。鑒于上述情況,如果将使用者資料完全部署在記憶體版本CRS,系統成本代價大,降低了資源有效使用率, 反之,如果将資料都部署在SSD, 可能導緻通路時延加大,服務體驗變差。為了取得“成本效益”與“服務品質”的平衡, CRS啟用了“冷熱分離”的混合部署方式。
一旦啟用冷熱分離模式, 系統會按照預置的“冷熱規則”,開始自動的識别“篩選”資料,将熱資料遷移到高效的記憶體系統,将冷資料沉降到SSD系統。而“冷熱規則”,可以根據需要,實時動态調整門限,以達到系統容量與性能的平衡。
3.3.3.1. Redis資料插件
利用Grocery的資料解析插件機制,可以很容易給Grocery增加Redis資料接口和存儲:
如上圖所示,我們在資料機嵌入了Grocery-Redis資料插件,可直接解析Redis協定,而下方Grocery通用存儲層則完全不感覺Redis資料格式,隻是按照Cache的指令以一定格式将序列化的資料落地,并支援同步等操作。
資料機在處理Redis協定時,先将資料從存儲中通過Redis格式處理子產品恢複為Redis的各種資料結構,根據從協定中收到的Redis指令對資料進行讀取或修改,修改後的資料被寫回到Grocery存儲中,進而完成了資料存取流程。在這個流程中,Redis插件引擎通過内建Redis-cache機制,保證了資料存取效率。
3.3.3.2. 分布式事務
Redis單機版本提供多條指令事務支援,擴充到分布式系統,這裡需要引入分布式事務的能力。CRS對分布式事務的支援,原理與“二階段送出”類似,首先為確定事務的一緻性,事務執行的協調者,會生成全局的事務ID, 用事務ID來鎖定分布式的資源,資源一旦被鎖定,僅持有該事務ID的執行過程,可以通路或修改該資源,其它通路被阻塞或丢棄。當資源鎖定都OK後,可以認為資源準備成功,開始申請資源修改過程,所有操作結束後, 協調者主動發起釋放鎖,通知各資源送出,事務成功結束。如果修改操作失敗,協調可以發起復原操作,終止事務送出。
整個過程中,可能會遇到兩種異常:鍊路不可達,節點異常當機。 CRS采用了兩種手段來應對, 其一是定時解鎖與主動復原機制,主要應對鍊路不可達引起的逾時異常;另一是事務流水日志恢複機制,主要應對節點當機引起的送出異常。
3.3.3.3. 雲上多租戶上報與監控
由于CRS系統中,每一台機器都會服務多個業務,需要對各個業務的各種指令進行監控,是以加入了多元上報系統。
多元上報系統提供簡單高效的上報接口并支援從任意次元進行資料的上報和聚合。後端存儲服務會根據業務的上報資訊自動建表和分表,是以業務無需事先申請需要上報的次元,可以自由擴充。由于上報的資料量巨大,多元上報系統在用戶端會對一分鐘内的資料進行一次彙聚再傳遞到服務端做存儲,以減小對服務端的壓力。
目前CRS系統通過多元上報系統來生成日報,能知道各個業務每天的詳細營運情況,如下圖所示:
3.3.3.4. 叢集化配額管理
在雲環境中,機器以分布式的方式進行工作。在單機的流量、CPU、記憶體等資源有限、資料熱度分布不均的情況下,如何對資源進行統一有效的管理與隔離,防止單一業務大量耗費資源,進而導緻整個雲的服務品質下降,成為需要解決的一個問題。
為此我們開發了叢集化配額管理系統。系統記錄了每個業務在每台機器所使用的資源的情況,并将該資料送出到排程中心。由排程中心根據該業務在每台機器的使用情況及其所能使用的資源額度,調整該業務在每台機器的配額,同時確定所有業務在單台機器上使用的資源不會超過該機器的最大能力,防止機器過載的情況發生。
3.3.3.5. 無縫遷移
在目前常見的遷移方案(如codis 的redis-port)中,業務做遷移時都需要停服,無法灰階而且在不滿意新的redis方案時也不能復原。是以CRS提供了無縫遷移子產品,支援對單機redis,codis及twemproxy資料的遷入。
CRS的無縫遷移子產品支援不停服遷移,業務在遷移過程中可以灰階修改配置或代碼。使用者還可以通過web端檢視目前的遷移進度,并可以配置在何時将服務真正遷移到CRS中(資料從CRS中讀取),何時下架舊的redis服務。
在遷移過程中Migrate proxy會對業務使用的指令進行校驗,如果有CRS不支援的指令則停止資料遷移并通知業務做相應的修改。此外,無縫遷移子產品在使用者真正确認下架舊的redis服務之前會盡量保證舊的redis服務和CRS中資料的一緻性,是以使用者如果發現CRS有不能滿足業務需求的地方,可以及時復原。
3.3.3.6. 資料使用者管理機制
CRS提供了資料導入、導出、快照和記錄流水功能,在資料管理方面,形成完整的閉環解決方案,為使用者資料提供健康保障。
目前提供了以下功能,滿足使用者資料管理的需求:
•RDB導入——将使用者的RDB檔案導入到Grocery
•RDB導出——将Grocery資料導出為RDB檔案
•生成快照——在運作時生成使用者資料快照
•快照恢複——使用者選擇快照恢複資料
•時間點恢複——将使用者資料恢複到指定時間點
•Key級快照恢複——從指定快照恢複Key
•Key級時間點恢複——将指定Key復原到指定時間點
基于以上功能,使用者可以友善地在自建redis和grocery間遷移資料,可以根據需要生成快照,并在執行個體和Key級對資料進行回檔操作,滿足日常運維和營運需求。
CRS在基于支撐日均萬億請求、5個9可靠性的Grocery存儲平台之上,支援了Redis協定和存儲結構,并有效解決了目前主流Redis服務存在的可伸縮性不佳、運維能力欠缺、成本高等問題,為使用者提供了高可靠、高擴充、功能豐富、價格有競争力的Redis雲服務。