作者:孫勇福,騰訊雲進階工程師,負責騰訊雲 TDSQL 産品研發,畢業至今一直從事資料存儲系統運維和研發工作,在資料庫領域以及 NoSQL 領域具有豐富的運維和開發經驗。
開源資料庫往往不具備商業資料庫一樣的高端能力,但是卻因簡單易用,無需 license 費用等深得大家喜歡,但在雲服務時代,打造一款同時具備了開源資料庫的成本效益和商業資料庫的安全性的資料庫,幾乎是所有使用者心中的夢想。騰訊雲資料庫 TDSQL 基于這樣的考慮,實作了雲化的審計能力,下面就讓我們一起來看看具體的技術細節。
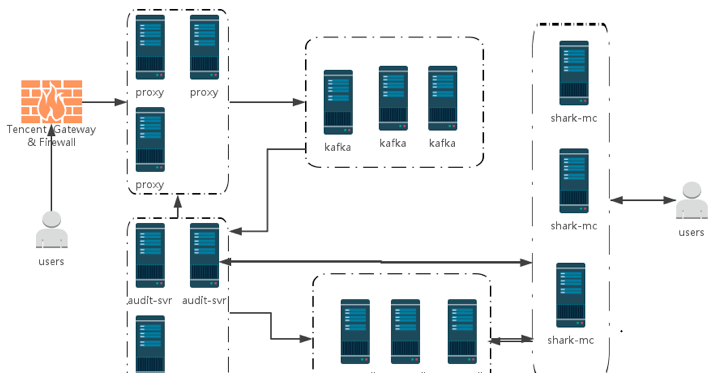
各子產品特點
1) proxy
三個無差别 proxy Ip,保證一個或者兩個 proxy 故障時,剩餘 proxy Ip 正常工作使用者無感覺。
旁路資訊進入 kafka 時,對資料進行壓縮上傳同時 kafka 必須半數節點響應成功後才算正确上傳。
每個使用者執行個體都有自己單獨的 proxy,在資料上傳是不同執行個體消息并發上傳到 kafak 的 topic ,保證每個使用者資訊及時進入審計消息隊列。
2) Kafka
Kafka 是一種分布式的,基于釋出/訂閱的消息系統。主要設計目标如下:
以時間複雜度為O(1)的方式提供消息持久化能力,即使對TB級以上資料也能保證常數時間的通路性能
高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒100K條消息的傳輸
支援 Kafka Server 間的消息分區,及分布式消費,同時保證每個partition内的消息順序傳輸
同時支援離線資料處理和實時資料處理
Kafka解析
Terminology
Broker:Kafka 叢集包含一個或多個伺服器,這種伺服器被稱為 broker。
Topic:每條釋出到Kafka叢集的消息都有一個類别,這個類别被稱為topic。(實體上不同topic的消息分開存儲,邏輯上一個topic的消息雖然儲存于一個或多個broker上但使用者隻需指定消息的topic即可生産或消費資料而不必關心資料存于何處)。
Partition:parition是實體上的概念,每個topic包含一個或多個partition,建立topic時可指定parition數量。每個partition對應于一個檔案夾,該檔案夾下存儲該partition的資料和索引檔案。
Producer:負責釋出消息到Kafka broker
Consumer:消費消息。每個consumer屬于一個特定的consumer group(可為每個consumer指定group name,若不指定group name則屬于預設的group)。使用consumer high level API時,同一topic的一條消息隻能被同一個consumer group内的一個consumer消費,但多個consumer group可同時消費這一消息。
Kafka架構

如上圖所示,一個典型的kafka叢集中包含若幹producer(可以是web前端産生的page view,或者是伺服器日志,系統CPU、memory等),若幹broker(Kafka支援水準擴充,一般broker數量越多,叢集吞吐率越高),若幹consumer group,以及一個Zookeeper叢集。Kafka通過Zookeeper管理叢集配置,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式将消息釋出到broker,consumer使用pull模式從broker訂閱并消費消息。
3) audit-server
audit-server 是分布式服務,采用一緻性hash算法進行路由。
多協程并發處理模式保證kafka資料秒級别消費。
一緻性hash
在分布式叢集中,對于機器的添加和删除已經故障機器自動脫離叢集不影響服務是分布式叢集的最基本的功能。本次審計服務采用一緻性hash完成這種基本功能。
具體描述如下:按照常用的hash算法來将對應的key哈希到一個具有2^32次方個桶的空間中,即0~(2^32)-1的數字空間中,也就是将object1,object2, object3, object4 四個(假設有四個執行個體對象)執行個體對象通過hash 散列到hash環上。如圖(來自于網絡)
同時将三個服務節點(假設三個服務節點),通過hash也散列到hash環上。如圖(來自于網絡),通過找出距離自己最近的node節點,即可找到服務節點。
在服務節點添加删除或故障時執行個體對象都會自動的調整找到距離自己最近的服務節點進行審計服務。
同時,在引入audit-server路由時,我們發現node服務節點分布越均勻,每個服務節點的負載也就越均勻。這裡引用了虛拟節點來解決這一問題。
審計政策
獨立規則加載協程:在規則加載時,不影響審計規則功能區性能
優先級:政策支援使用者自定義優先級,在政策比對時,優先比對到優先級較高的政策。
規則設定豐富: 支援規則=, !=,>, >=, <, <= 以及正則比對。
權限:支援二次認證,保證資料安全性。
多并發協程
協程,不需要搶占式排程,可以有效提高線程的任務并發性,而避免多線程的缺點(go原生支援)
故障優化
耦合關系:保證一個子系統發生故障時,不會影響其他系統的正常運作。
審計服務故障時保障資料不丢:消息消費時會動态的記錄比對到規則的或者超過一定門檻值消息的offset,保證服務被配置設定到其他節點或者故障服務修複啟動時都會從正确的位置消費消息。
資料旁路kafka資料不丢:在資料傳入到kafka是必須保證半數以上的節點響應此消息時,才進行下面的資料傳輸。
告警及時感覺:kafka 或者MongoDB不可用時會秒級别感覺,發送告警資訊給系統負責人,及時恢複服務。
自動擴容:比對規則消息存儲采用騰訊雲MongoDB,通過背景打通,在存儲空間不夠時支援自動擴容。
資料順序性:每個消息在旁路時都會被打上一個時間戳同時消息也是按順序進入消息隊列,在資料讀取時按照時間戳順序讀取。
3) 騰訊雲MongoDB
騰訊雲MongoDB特點:
設計服務資料存儲采用,騰訊雲自有的MongoDB服務,該産品具備以下特點:
雲存儲服務,是騰訊雲平台提供的面向網際網路應用的資料存儲服務。
提供了高性能、高可靠、易用、便捷的MongoDB叢集服務,每一個執行個體都是至少一主一從的副本集或者包含多個副本集的分片叢集。
整合了備份、擴容等功能,盡可能的保證使用者資料安全以及動态伸縮能力
當然,為了使用者的安全考慮,我們所有的資料,都是需要使用者主動開啟審計的前提下,才會記錄流水資料,并對資料進行過濾和存儲。
使用雲資料庫MongoDB服務的好處:
安全:提供線上的至少兩份資料存儲,確定線上資料安全。同時通過備份機制儲存多天的備份資料以便于在災難情況進行資料恢複。
高性能:集中安裝專用高性能存儲伺服器(高記憶體全SSD機型)來支援海量通路。
省心:提供7×24小時的專業服務,擴容和遷移對使用者透明且不影響服務。提供全面監控,可随時掌控MongoDB服務品質。