容量管理從本質來講,主要需要解決的問題是系統“亞健康(有病,但還不影響生活和工作)”的情況下,我們能夠及時知道,并做出對應政策,確定系統恢複到正常順暢;本方案主要是講的第一部分,“我們如何及時知道、并告警/預警”,不涉及到“容量處理政策”。
能提供服務,但是速度較慢;
随着業務的逐漸發展,一路上升都提供良好,但是離懸崖慢慢靠近(用一個舉重運動員的話說,在壓一塊金牌在杠鈴上,就倒了);
業務突發增長,導緻短時間内,系統資源耗盡,服務品質嚴重下降;
随着業務的發展,在約定時間内逐漸無法完成任務(例如:1個小時跑一次的資料統計,随着業務增長,無法在1個小時内完成);
依據以上問題場景,資料容量系統定義以下目标,并以此目标為驗收标準;
容量實時監控;
容量按天日報,了解到目前系統在資源和業務方面的容量百分比,處理取于高負載的裝置或者是子產品;
成本控制,通過對低負載子產品的展現,整合機器使用率,有效控制成本;
針對實時系統,主要采用一下三種方式來達到要求:
針對外網服務,自動化測試監控平台提供模拟使用者角度從外網IP通路網頁(目前主要是針對pay、積分、support、service四個外部網站),并且對時耗做了收集和告警;
針對背景服務,自動化測試監控平台提供模拟用戶端從内網IP通路服務端,針對所有實時系統都添加了核心功能的自動化測試,并且對時耗也做了收集和告警;
針對基礎資源的實時監控,主要有以下幾種:
部門預設在tnm2平台上統一配置的告警政策: 單機cpu使用率:使用率大于等于95%,連續20分鐘,短信告警;
單機cpu負載: 負載大于等于4,連續20分鐘,短信告警;
單機應用記憶體使用率:使用率>85%,連續20分鐘,短信告警; 單機外網流量告警:
目前流量>=<code>200%*</code>上周同天同點,連續出現30分鐘,則短信告警
目前流量<<code>20%*</code>上周同天同點,連續出現30分鐘,則短信告警 單機硬碟使用率:
使用率>95%,直接上報noc
使用率>90%, 預警發短信
針對OS層面,自行腳本資源配置
fd使用量:
單個程序,超過"ulimit -n"最大限定值的90%,則短信郵件告警機器負責人;
記憶體使用量:
單個程序,實體記憶體使用量超過 <code>/bin/free | grep Mem | awk '{print $2}'</code> 的90%,則短信郵件告警機器負責人;
swap使用量:
一台裝置,若swap使用率超過1/2,則短信郵件告警機器負責人;
共享記憶體使用量:
一台裝置,若共享記憶體個數使用超過<code>/usr/bin/ipcs -m -l | grep "number of segments"</code>最大限定的90%,則短信郵件告警機器負責人;
信号量使用量:
一台裝置,若信号量使用超過<code>/usr/bin/ipcs -s -l | grep "number of arrays"</code>最大限定的90%,則短信郵件告警機器負責人;
消息隊列使用量:
一台裝置,若消息隊列使用超過<code>/usr/bin/ipcs -q -l | grep "max queues system"</code>最大限定的90%,則短信郵件告警機器負責人;
消息隊列未處理量:
一個消息隊列,若未處理消息數>50個,則短信郵件告警機器負責人;
tcp連接配接數數(<code>close_wait</code>狀态)
一台機器tcp連接配接數(<code>close_wait</code>狀态)數量超過<code>ulimit -n</code>的最大限定值的60%,則短信郵件告警機器負責人;
容量采集資料以及方式: 硬體相關的基礎資源:均可通過網管背景擷取采樣值。
關鍵名額:CPU使用率、CPU負載、外網入流量,外網出流量、應用記憶體使用率、磁盤使用率 OS相關的基礎資源:裝置從本機作為特性上報到公司網管,容量從網管背景取得采樣值;
關鍵名額:FD、TCP連接配接數、mysql連接配接數 業務特性:裝置從本機作為特性上報到公司網管,容量從網管背景取得采樣值;
關鍵名額:請求量數、平均時耗、占用計算資源、失敗率
計算每日負載值:
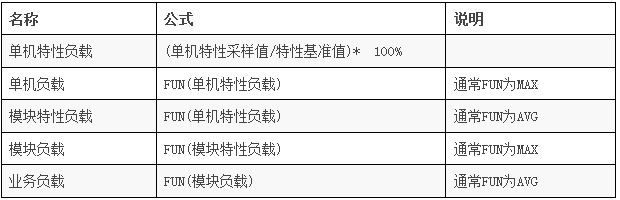
輸出物:
裝置負載日報(高負載管理、低負載管理)
業務子產品負載日報
離線任務執行時耗超過最大值,直接告警(滿足場景五、告警時間2分鐘;預警時間1天);
采用service收集離線任務開始時間、結束時間、執行時間标準;
采用公共工具部署在每台伺服器上,各自任務自行上報開始時間點,結束時間點。
本方案僅僅涉及到“容量問題告警、預警”的内容,部門在這一塊才剛剛起步,特别是問題出現之後的"定位、處理"還沒有定論和統一解決方案,另外,容量管理系統的client端非常多,如何簡單有效的管理這些client端也是個挑戰。還希望大家能夠有好的想法、建議,可以和hairy這邊交流,讓容量管理在“減少故障發生、降低故障影響”等方面發揮大作用。
相關推薦
精細化容量管理的裝置成本優化之路
如何依托騰訊雲完成海量資料的存儲和備份