上一篇文章介紹了 seqsvr 的原型,這篇會簡單地介紹下 seqsvr 容災架構的演變。我們知道,背景系統絕大部分情況下并沒有一種唯一的、完美的解決方案,同樣的需求在不同的環境背景下甚至有可能演化出兩種截然不同的架構。既然架構是多變的,那純粹講架構的意義并不是特别大,這裡也會講下 seqsvr 容災設計時的一些思考和權衡,希望對大家有所幫助。
接下來我們會介紹 seqsvr 的容災架構。我們知道,背景系統絕大部分情況下并沒有一種唯一的、完美的解決方案,同樣的需求在不同的環境背景下甚至有可能演化出兩種截然不同的架構。既然架構是多變的,那純粹講架構的意義并不是特别大,期間也會講下 seqsvr 容災設計時的一些思考和權衡,希望對大家有所幫助。
seqsvr 的容災模型在五年中進行過一次比較大的重構,提升了可用性、機器使用率等方面。其中不管是重構前還是重構後的架構,seqsvr 一直遵循着兩條架構設計原則:
保持自身架構簡單
避免對外部子產品的強依賴
這兩點都是基于 seqsvr 可靠性考慮的,畢竟 seqsvr 是一個與整個微信服務端正常運作息息相關的子產品。按照我們對這個世界的認識,系統的複雜度往往是跟可靠性成反比的,想得到一個可靠的系統一個關鍵點就是要把它做簡單。相信大家身邊都有一些這樣的例子,設計方案裡有很多高大上、複雜的東西,同時也總能看到他們在默默地填一些高大上的坑。當然簡單的系統不意味着粗制濫造,我們要做的是理出最核心的點,然後在滿足這些核心點的基礎上,針對性地提出一個足夠簡單的解決方案。
那麼,seqsvr 最核心的點是什麼呢?每個 uid 的 sequence 申請要遞增不回退。這裡我們發現,如果 seqsvr 滿足這麼一個限制:任意時刻任意 uid 有且僅有一台 AllocSvr 提供服務,就可以比較容易地實作 sequence 遞增不回退的要求。
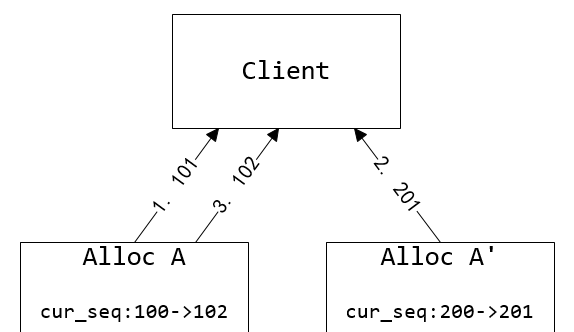
圖5. 兩台 AllocSvr 服務同個 uid 造成 sequence 回退。Client 讀取到的 sequence 序列為101、201、102
但也由于這個限制,多台AllocSvr同時服務同一個号段的多主機模型在這裡就不适用了。我們隻能采用單點服務的模式,當某台 AllocSvr 發生服務不可用時,将該機服務的 uid 段切換到其它機器來實作容災。這裡需要引入一個仲裁服務,探測 AllocSvr 的服務狀态,決定每個 uid 段由哪台 AllocSvr 加載。出于可靠性的考慮,仲裁子產品并不直接操作 AllocSvr ,而是将加載配置寫到 StoreSvr 持久化,然後 AllocSvr 定期通路 StoreSvr 讀取最新的加載配置,決定自己的加載狀态。

圖6. 号段遷移示意。通過更新加載配置把0~2号段從 AllocSvrA 遷移到 AllocSvrB
同時,為了避免失聯AllocSvr提供錯誤的服務,傳回髒資料,AllocSvr需要跟StoreSvr保持租約。這個租約機制由以下兩個條件組成:
租約失效:AllocSvr N秒内無法從StoreSvr讀取加載配置時,AllocSvr停止服務。
租約生效:AllocSvr讀取到新的加載配置後,立即解除安裝需要解除安裝的号段,需要加載的新号段等待N秒後提供服務。
圖7. 租約機制。AllocSvrB嚴格保證在AllocSvrA停止服務後提供服務
這兩個條件保證了切換時,新 AllocSvr 肯定在舊 AllocSvr 下線後才開始提供服務。但這種租約機制也會造成切換的号段存在小段時間的不可服務,不過由于微信背景邏輯層存在重試機制及異步重試隊列,小段時間的不可服務是使用者無感覺的,而且出現租約失效、切換是小機率事件,整體上是可以接受的。
到此講了 AllocSvr 容災切換的基本原理,接下來會介紹整個 seqsvr 架構容災架構的演變。
初版本的 seqsvr 采用了主機+冷備機容災模式:全量的 uid 空間均勻分成N個 Section,連續的若幹個 Section 組成了一個 Set,每個 Set 都有一主一備兩台 AllocSvr 。正常情況下隻有主機提供服務;在主機出故障時,仲裁服務切換主備,原來的主機下線變成備機,原備機變成主機後加載 uid 号段提供服務。
圖8. 容災1.0架構:主備容災
可能看到前文的叙述,有些同學已經想到這種容災架構。一主機一備機的模型設計簡單,并且具有不錯的可用性——畢竟主備兩台機器同時不可用的機率極低,相信很多背景系統也采用了類似的容災政策。
主備容災存在一些明顯的缺陷,比如備機閑置導緻有一半的空閑機器;比如主備切換的時候,備機在瞬間要接受主機所有的請求,容易導緻備機過載。既然一主一備容災存在這樣的問題,為什麼一開始還要采用這種容災模型?事實上,架構的選擇往往跟當時的背景有關,seqsvr 誕生于微信發展初期,也正是微信快速擴張的時候,選擇一主一備容災模型是出于以下的考慮:
架構簡單,可以快速開發
機器數少,機器備援不是主要問題
Client 端更新 AllocSvr 的路由狀态很容易實作
前兩點好懂,人力、機器都不如時間寶貴。而第三點比較有意思,下面展開講下:
微信背景絕大部分子產品使用了一個自研的RPC架構,seqsvr也不例外。在這個RPC架構裡,調用端讀取本地機器的client配置檔案,決定去哪台服務端調用。這種模型對于無狀态的服務端,是很好用的,也很友善實作容災。我們可以在client配置檔案裡面寫“對于号段x,可以去SvrA、SvrB、SvrC三台機器的任意一台通路”,實作三主機容災。
但在seqsvr裡,AllocSvr是預配置設定中間層,并不是無狀态的。而前面我們提到,AllocSvr加載哪些uid号段,是由儲存在StoreSvr的加載配置決定的。那麼這時候就尴尬了,業務想要申請某個uid的sequence,Client端其實并不清楚具體去哪台AllocSvr通路,client配置檔案隻會跟它說“AllocSvrA、AllocSvrB…這堆機器的某一台會有你想要的sequence”。換句話講,原來負責提供服務的AllocSvrA故障,仲裁服務決定由AllocSvrC來替代AllocSvrA提供服務,Client要如何獲知這個路由資訊的變更?
這時候假如我們的AllocSvr采用了主備容災模型的話,事情就變得簡單多了。我們可以在client配置檔案裡寫:對于某個uid号段,要麼是AllocSvrA加載,要麼是AllocSvrB加載。Client端發起請求時,盡管Client端并不清楚AllocSvrA和AllocSvrB哪一台真正加載了目标uid号段,但是Client端可以先嘗試給其中任意一台AllocSvr發請求,就算這次請求了錯誤的AllocSvr,那麼就知道另外一台是正确的AllocSvr,再發起一次請求即可。
也就是說,對于主備容災模型,最多也隻會浪費一次的試探請求來确定AllocSvr的服務狀态,額外消耗少,編碼也簡單。可是,如果Svr端采用了其它複雜的容災政策,那麼基于靜态配置的架構就很難去确定Svr端的服務狀态:Svr發生狀态變更,Client端無法确定應該向哪台Svr發起請求。這也是為什麼一開始選擇了主備容災的原因之一。
在我們的實際營運中,容災1.0架構存在兩個重大的不足:
擴容、縮容非常麻煩
一個 Set 的主備機都過載,無法使用其他 Set 的機器進行容災
在主備容災中,Client 和 AllocSvr 需要使用完全一緻的配置檔案。變更這個配置檔案的時候,由于無法實作在同一時間更新給所有的 Client 和 AllocSvr ,是以需要非常複雜的人工操作來保證變更的正确性(包括需要使用iptables來做請求轉發,具體的詳情這裡不做展開)。
對于第二個問題,常見的方法是用一緻性 Hash 算法替代主備,一個 Set 有多台機器,過載機器的請求被分攤到多台機器,容災效果會更好。在 seqsvr 中使用類似一緻性 Hash 的容災政策也是可行的,隻要 Client 端與仲裁服務都使用完全一樣的一緻性 Hash 算法,這樣 Client 端可以啟發式地去嘗試,直到找到正确的 AllocSvr。
例如對于某個 uid,仲裁服務會優先把它配置設定到 AllocSvrA ,如果 AllocSvrA 挂掉則配置設定到 AllocSvrB ,再不行配置設定到 AllocSvrC。那麼 Client 在通路 AllocSvr 時,按照 AllocSvrA -> AllocSvrB -> AllocSvrC 的順序去通路,也能實作容災的目的。但這種方法仍然沒有克服前面主備容災面臨的配置檔案變更的問題,營運起來也很麻煩。
最後我們另辟蹊徑,采用了一種不同的思路:既然 Client 端與 AllocSvr 存在路由狀态不一緻的問題,那麼讓 AllocSvr 把目前的路由狀态傳遞給 Client 端,打破之前隻能根據本地 Client 配置檔案做路由決策的限制,從根本上解決這個問題。
是以在2.0架構中,我們把 AllocSvr 的路由狀态嵌入到 Client 請求 sequence 的響應包中,在不帶來額外的資源消耗的情況下,實作了 Client 端與 AllocSvr 之間的路由狀态一緻。具體實作方案如下:
seqsvr 所有子產品使用了統一的路由表,描述了 uid 号段到 AllocSvr 的全映射。這份路由表由仲裁服務根據 AllocSvr 的服務狀态生成,寫到 StoreSvr 中,由 AllocSvr 當作租約讀出,最後在業務傳回包裡旁路給 Client 端。
圖9. 容災2.0架構:動态号段遷移容災
把路由表嵌入到請求響應包看似很簡單的架構變動,卻是整個 seqsvr 容災架構的技術奇點。利用它解決了路由狀态不一緻的問題後,可以實作一些以前不容易實作的特性。例如靈活的容災政策,讓所有機器都互為備機,在機器故障時,把故障機上的号段均勻地遷移到其它可用的 AllocSvr 上;還可以根據 AllocSvr 的負載情況,進行負載均衡,有效緩解 AllocSvr 請求不均的問題,大幅提升機器使用率。
另外在營運上也得到了大幅簡化。之前對機器進行運維操作有着繁雜的操作步驟,而新架構隻需要更新路由即可輕松實作上線、下線、替換機器,不需要關心配置檔案不一緻的問題,避免了一些由于人工誤操作引發的故障。
圖10. 機器故障号段遷移
把路由表嵌入到取 sequence 的請求響應包中,那麼會引入一個類似“先有雞還是先有蛋”的哲學命題:沒有路由表,怎麼知道去哪台 AllocSvr 取路由表?另外,取 sequence 是一個超高頻的請求,如何避免嵌入路由表帶來的帶寬消耗?
這裡通過在 Client 端記憶體緩存路由表以及路由版本号來解決,請求步驟如下:
Client 根據本地共享記憶體緩存的路由表,選擇對應的AllocSvr;如果路由表不存在,随機選擇一台AllocSvr;
對選中的 AllocSvr 發起請求,請求帶上本地路由表的版本号;
AllocSvr 收到請求,除了處理 sequence 邏輯外,判斷 Client 帶上版本号是否最新,如果是舊版則在響應包中附上最新的路由表;
Client收到響應包,除了處理 sequence 邏輯外,判斷響應包是否帶有新路由表。如果有,更新本地路由表,并決策是否傳回第1步重試。
基于以上的請求步驟,在本地路由表失效的時候,使用少量的重試便可以拉到正确的路由,正常提供服務。
到此把 seqsvr 的架構設計和演變基本講完了,正是如此簡單優雅的模型,為微信的其它子產品提供了一種簡單可靠的一緻性解決方案,支撐着微信五年來的高速發展,相信在可預見的未來仍然會發揮着重要的作用。