任何的伺服器的性能都是有極限的,面對海量的網際網路通路需求,是不可能單靠一台伺服器或者一個CPU來承擔的。是以我們一般都會在運作時架構設計之初,就考慮如何能利用多個CPU、多台伺服器來分擔負載,這就是所謂分布的政策。分布式的伺服器概念很簡單,但是實作起來卻比較複雜。因為我們寫的程式,往往都是以一個CPU,一塊記憶體為基礎來設計的,是以要讓多個程式同時運作,并且協調運作,這需要更多的底層工作。
首先出現能支援分布式概念的技術是多程序。在DOS時代,計算機在一個時間内隻能運作一個程式,如果你想一邊寫程式,同時一邊聽mp3,都是不可能的。但是,在WIN95作業系統下,你就可以同時開多個視窗,背後就是同時在運作多個程式。在Unix和後來的Linux作業系統裡面,都普遍支援了多程序的技術。
所謂的多程序,就是作業系統可以同時運作我們編寫的多個程式,每個程式運作的時候,都好像自己獨占着CPU和記憶體一樣。在計算機隻有一個CPU的時候,實際上計算機會分時複用的運作多個程序,CPU在多個程序之間切換。但是如果這個計算機有多個CPU或者多個CPU核,則會真正的有幾個程序同時運作。是以程序就好像一個作業系統提供的運作時“程式盒子”,可以用來在運作時,容納任何我們想運作的程式。當我們掌握了作業系統的多程序技術後,我們就可以把伺服器上的運作任務,分為多個部分,然後分别寫到不同的程式裡,利用上多CPU或者多核,甚至是多個伺服器的CPU一起來承擔負載。
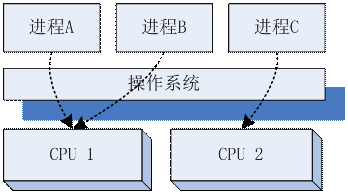
多程序利用多CPU
這種劃分多個程序的架構,一般會有兩種政策:一種是按功能來劃分,比如負責網絡處理的一個程序,負責資料庫處理的一個程序,負責計算某個業務邏輯的一個程序。另外一種政策是每個程序都是同樣的功能,隻是分擔不同的運算任務而已。使用第一種政策的系統,運作的時候,直接根據作業系統提供的診斷工具,就能直覺的監測到每個功能子產品的性能消耗,因為作業系統提供程序盒子的同時,也能提供對程序的全方位的監測,比如CPU占用、記憶體消耗、磁盤和網絡I/O等等。但是這種政策的運維部署會稍微複雜一點,因為任何一個程序沒有啟動,或者和其他程序的通信位址沒配置好,都可能導緻整個系統無法運作;而第二種分布政策,由于每個程序都是一樣的,這樣的安裝部署就非常簡單,性能不夠就多找幾個機器,多啟動幾個程序就完成了,這就是所謂的平行擴充。
現在比較複雜的分布式系統,會結合這兩種政策,也就是說系統既按一些功能劃分出不同的具體功能程序,而這些程序又是可以平行擴充的。當然這樣的系統在開發和運維上的複雜度,都是比單獨使用“按功能劃分”和“平行劃分”要更高的。由于要管理大量的程序,傳統的依靠配置檔案來配置整個叢集的做法,會顯得越來越不實用:這些運作中的程序,可能和其他很多程序産生通信關系,當其中一個程序變更通信位址時,勢必影響所有其他程序的配置。是以我們需要集中的管理所有程序的通信位址,當有變化的時候,隻需要修改一個地方。在大量程序建構的叢集中,我們還會碰到容災和擴容的問題:當叢集中某個伺服器出現故障,可能會有一些程序消失;而當我們需要增加叢集的承載能力時,我們又需要增加新的伺服器以及程序。這些工作在長期運作的伺服器系統中,會是比較常見的任務,如果整個分布系統有一個運作中的中心程序,能自動化的監測所有的程序狀态,一旦有程序加入或者退出叢集,都能即時的修改所有其他程序的配置,這就形成了一套動态的多程序管理系統。開源的ZooKeeper給我們提供了一個可以充當這種動态叢集中心的實作方案。由于ZooKeeper本身是可以平行擴充的,是以它自己也是具備一定容災能力的。現在越來越多的分布式系統都開始使用以ZooKeeper為叢集中心的動态程序管理政策了。

動态程序叢集
在調用多程序服務的政策上,我們也會有一定的政策選擇,其中最著名的政策有三個:一個是動态負載均衡政策;一個是讀寫分離政策;一個是一緻性哈希政策。動态負載均衡政策,一般會搜集多個程序的服務狀态,然後挑選一個負載最輕的程序來分發服務,這種政策對于比較同質化的程序是比較合适的。讀寫分離政策則是關注對持久化資料的性能,比如對資料庫的操作,我們會提供一批程序專門用于提供讀資料的服務,而另外一個(或多個)程序用于寫資料的服務,這些寫資料的程序都會每次寫多份拷貝到“讀服務程序”的資料區(可能就是單獨的資料庫),這樣在對外提供服務的時候,就可以提供更多的硬體資源。一緻性哈希政策是針對任何一個任務,看看這個任務所涉及讀寫的資料,是屬于哪一片的,是否有某種可以緩存的特征,然後按這個資料的ID或者特征值,進行“一緻性哈希”的計算,分擔給對應的處理程序。這種程序調用政策,能非常的利用上程序内的緩存(如果存在),比如我們的一個線上遊戲,由100個程序承擔服務,那麼我們就可以把遊戲玩家的ID,作為一緻性哈希的資料ID,作為程序調用的KEY,如果目标服務程序有緩存遊戲玩家的資料,那麼所有這個玩家的操作請求,都會被轉到這個目标服務程序上,緩存的命中率大大提高。而使用“一緻性哈希”,而不是其他雜湊演算法,或者取模算法,主要是考慮到,如果服務程序有一部分因故障消失,剩下的服務程序的緩存依然可以有效,而不會整個叢集所有程序的緩存都失效。具體有興趣的讀者可以搜尋“一緻性哈希”一探究竟。
以多程序利用大量的伺服器,以及伺服器上的多個CPU核心,是一個非常有效的手段。但是使用多程序帶來的額外的程式設計複雜度的問題。一般來說我們認為最好是每個CPU核心一個程序,這樣能最好的利用硬體。如果同時運作的程序過多,作業系統會消耗很多CPU時間在不同程序的切換過程上。但是,我們早期所獲得的很多API都是阻塞的,比如檔案I/O,網絡讀寫,資料庫操作等。如果我們隻用有限的程序來執行帶這些阻塞操作的程式,那麼CPU會大量被浪費,因為阻塞的API會讓有限的這些程序停着等待結果。那麼,如果我們希望能處理更多的任務,就必須要啟動更多的程序,以便充分利用那些阻塞的時間,但是由于程序是作業系統提供的“盒子”,這個盒子比較大,切換耗費的時間也比較多,是以大量并行的程序反而會無謂的消耗伺服器資源。加上程序之間的記憶體一般是隔離的,程序間如果要交換一些資料,往往需要使用一些作業系統提供的工具,比如網絡socket,這些都會額外消耗伺服器性能。是以,我們需要一種切換代價更少,通信方式更便捷,程式設計方法更簡單的并行技術,這個時候,多線程技術出現了。
在程序盒子裡面的線程盒子
多線程的特點是切換代價少,可以同時通路記憶體。我們可以在程式設計的時候,任意讓某個函數放入新的線程去執行,這個函數的參數可以是任何的變量或指針。如果我們希望和這些運作時的線程通信,隻要讀、寫這些指針指向的變量即可。在需要大量阻塞操作的時候,我們可以啟動大量的線程,這樣就能較好的利用CPU的空閑時間;線程的切換代價比程序低得多,是以我們能利用的CPU也會多很多。線程是一個比程序更小的“程式盒子”,他可以放入某一個函數調用,而不是一個完整的程式。一般來說,如果多個線程隻是在一個程序裡面運作,那其實是沒有利用到多核CPU的并行好處的,僅僅是利用了單個空閑的CPU核心。但是,在JAVA和C#這類帶虛拟機的語言中,多線程的實作底層,會根據具體的作業系統的任務排程機關(比如程序),盡量讓線程也成為作業系統可以排程的機關,進而利用上多個CPU核心。比如Linux2.6之後,提供了NPTL的核心線程模型,JVM就提供了JAVA線程到NPTL核心線程的映射,進而利用上多核CPU。而Windows系統中,據說本身線程就是系統的最小排程機關,是以多線程也是利用上多核CPU的。是以我們在使用JAVA\C#程式設計的時候,多線程往往已經同時具備了多程序利用多核CPU、以及切換開銷低的兩個好處。
早期的一些網絡聊天室服務,結合了多線程和多程序使用的例子。一開始程式會啟動多個廣播聊天的程序,每個程序都代表一個房間;每個使用者連接配接到聊天室,就為他啟動一個線程,這個線程會阻塞的讀取使用者的輸入流。這種模型在使用阻塞API的環境下,非常簡單,但也非常有效。
當我們在廣泛使用多線程的時候,我們發現,盡管多線程有很多優點,但是依然會有明顯的兩個缺點:一個記憶體占用比較大且不太可控;第二個是多個線程對于用一個資料使用時,需要考慮複雜的“鎖”問題。由于多線程是基于對一個函數調用的并行運作,這個函數裡面可能會調用很多個子函數,每調用一層子函數,就會要在棧上占用新的記憶體,大量線程同時在運作的時候,就會同時存在大量的棧,這些棧加在一起,可能會形成很大的記憶體占用。并且,我們編寫伺服器端程式,往往希望資源占用盡量可控,而不是動态變化太大,因為你不知道什麼時候會因為記憶體用完而當機,在多線程的程式中,由于程式運作的内容導緻棧的伸縮幅度可能很大,有可能超出我們預期的記憶體占用,導緻服務的故障。而對于記憶體的“鎖”問題,一直是多線程中複雜的課題,很多多線程工具庫,都推出了大量的“無鎖”容器,或者“線程安全”的容器,并且還大量設計了很多協調線程運作的類庫。但是這些複雜的工具,無疑都是證明了多線程對于記憶體使用上的問題。
同時排多條隊就是并行
由于多線程還是有一定的缺點,是以很多程式員想到了一個釜底抽薪的方法:使用多線程往往是因為阻塞式API的存在,比如一個read()操作會一直停止目前線程,那麼我們能不能讓這些操作變成不阻塞呢?——selector/epoll就是Linux退出的非阻塞式API。如果我們使用了非阻塞的操作函數,那麼我們也無需用多線程來并發的等待阻塞結果。我們隻需要用一個線程,循環的檢查操作的狀态,如果有結果就處理,無結果就繼續循環。這種程式的結果往往會有一個大的死循環,稱為主循環。在主循環體内,程式員可以安排每個操作事件、每個邏輯狀态的處理邏輯。這樣CPU既無需在多線程間切換,也無需處理複雜的并行資料鎖的問題——因為隻有一個線程在運作。這種就是被稱為“并發”的方案。
服務員兼了點菜、上菜就是并發
實際上計算機底層早就有使用并發的政策,我們知道計算機對于外部裝置(比如磁盤、網卡、顯示卡、聲霸卡、鍵盤、滑鼠),都使用了一種叫“中斷”的技術,早期的電腦使用者可能還被要求配置IRQ号。這個中斷技術的特點,就是CPU不會阻塞的一直停在等待外部裝置資料的狀态,而是外部資料準備好後,給CPU發一個“中斷信号”,讓CPU轉去處理這些資料。非阻塞的程式設計實際上也是類似這種行為,CPU不會一直阻塞的等待某些I/O的API調用,而是先處理其他邏輯,然後每次主循環去主動檢查一下這些I/O操作的狀态。
多線程和異步的例子,最著名就是Web伺服器領域的Apache和Nginx的模型。Apache是多程序/多線程模型的,它會在啟動的時候啟動一批程序,作為程序池,當使用者請求到來的時候,從程序池中配置設定處理程序給具體的使用者請求,這樣可以節省多程序/線程的建立和銷毀開銷,但是如果同時有大量的請求過來,還是需要消耗比較高的程序/線程切換。而Nginx則是采用epoll技術,這種非阻塞的做法,可以讓一個程序同時處理大量的并發請求,而無需反複切換。對于大量的使用者通路場景下,apache會存在大量的程序,而nginx則可以僅用有限的程序(比如按CPU核心數來啟動),這樣就會比apache節省了不少“程序切換”的消耗,是以其并發性能會更好。
Nginx的固定多程序,一個程序異步處理多個用戶端
Apache的多态多程序,一個程序處理一個客戶
在現代伺服器端軟體中,nginx這種模型的運維管理會更簡單,性能消耗也會稍微更小一點,是以成為最流行的程序架構。但是這種好處,會付出一些另外的代價:非阻塞代碼在程式設計的複雜度變大。