1、HashMap實作的是Map接口,與ArrayList不一樣,與Hashtable、LinkedHashMap一樣
2、HashMap隻允許一個key為null,如果有兩個和正常的key沖突一樣處理,HashMap非線程安全,可能會出現死鎖等,多線程裡使用的話可以用ConcurrentHashMap代替。
3、HashMap類似,不同的是它承自Dictionary類,線程安全,但是項目裡面不會用,非多線程環境不如HashMap,多線程環境可以使用ConcurrentHashMap,因為ConcurrentHashMap使用分段鎖,是以性能比HashTable好,ConcurrentHashMap後面會詳細說。
4、HashMap的構成是數組+連結清單(鍊位址法),新增一個Entry是通過一個Entry的key的hashcode再通過HashMap的hash算法(高位運算)和取模得到數組的位置,添加到連結清單的尾部。當然Hash算法計算結果越分散均勻,Hash碰撞的機率就越小,map的存取效率就會越高,當然數組的長度越大,Hash碰撞的機率就小,反之即使Hash很均勻,也會出現大量的Hash碰撞,解決方案就是好的Hash算法,以及擴容機制。
HashMap預設初始大小16(一般來說hash表的大小最好為素數,一般來說素數導緻沖突的機率要小于合數,而hashmap中的hash表大小為2的N次方,是一個合數(這個是計算過後的,不是你傳值多少初始大小就是多少)。HashMap采用這種非正常的設計,主要是為了在取模和擴容的時候做優化,同時為了減少沖突,HashMap定位hash桶索引的時候,也加入了高位參與運算的過程),負載因子0.75,0.75為綜合考慮空間和時間的因素,建議不要改,如果想提高查詢速度,可減小該值,如果想節省空間,可增大該值,負載因子可大于1,不過越大後期出現的hash碰撞會更多。在0.75的負載因子下,一般size <= threshold = table.length * loadFactor,也就是說元素數量肯定會小于哈希桶的長度,犧牲了空間提高時間效率。jdk1.8裡新增了紅黑樹部分,當連結清單長度大于8時轉化為紅黑樹,查詢效率更高,時間複雜度有O(n)到O(logn)。簡單資料類型的封裝類hash散列還是均勻分布的,對于自定義Object,如果hashcode的方法不好的話容易造成分布不均勻。
HashMap是通過key的hashcode方法進行hash算法那後取模計算key對應的數組位置,找到對應的連結清單,再通過==或者equal()來判定二個key是否相等 。
參考一下美團團隊的圖:
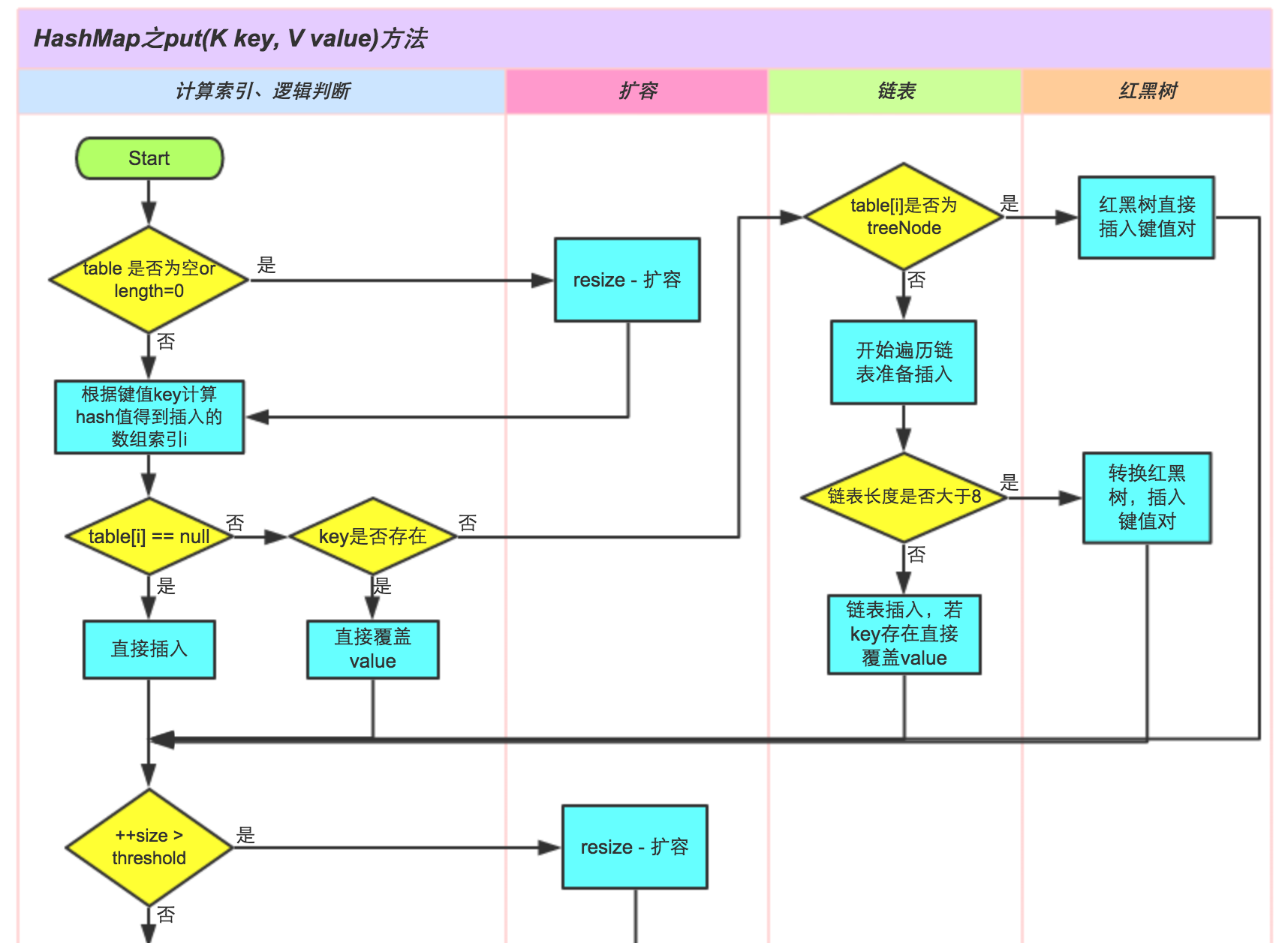
5、HashMap線程不安全,會産生死鎖的原因簡單點就是resize的時候一個線程裡擴容後一個keya的next為另一個keyb,而另一個keyb在擴容的時候由于發現自己的next就是那一個keya,這時候陷入死循環。jdk1.7裡resize的時候會導緻連結清單順序倒過來,而1.8不會。1.8雖然不會因為順序倒置而有死循環的問題,但是在并發的情況還是有可能有資料丢失的問題,這時候還是要用ConcurrentHashMap。
圖文介紹可參考
<a href="http://www.importnew.com/22011.html">HashMap死鎖圖文解釋</a>
6、HashSet是基于HashMap來實作的,HashSet裡元素也是無序的
7、ArrayList集合是初始化容量為10,每次擴容後為1.5倍
8、Hashmap為什麼大小是2的幂次。因為HashMap的采用高位運算
9、有序HashMap:LinkedHashMap,實作原理是HashMap+LinkedList,HashMap的數組連結清單+Entry之間的雙向連結清單。
![查找算法之二分查找查找算法之二分查找[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)