上文我們介紹了引擎如何獲得後向計算圖的依賴,本文我們就接着看看引擎如何依據這些依賴進行後向傳播。
目錄
[源碼解析] PyTtorch 分布式 Autograd (6) ---- 引擎(下)
0x00 摘要
0x01 回顧
0x02 執行GraphTask
2.1 runEngineAndAccumulateGradients
2.2 execute_graph_task_until_ready_queue_empty
2.3 evaluate_function
2.4 globalCpuThread
2.5 小結
0x03 RPC調用
3.1 RecvRpcBackward
3.1.1 定義
3.1.2 建構
3.1.3 apply
3.2 PropagateGradientsReq3.2.1 定義
3.3 接受方
3.3.1 接受消息
3.3.2 processBackwardAutogradReq
3.3.3 executeSendFunctionAsync
0x04 DistAccumulateGradCaptureHook
4.1 定義
4.2 生成
4.3 使用
4.4 累積梯度
4.4.1 上下文累積
4.4.2 算子累積
0x05 等待完成
0xFF 參考
上文我們介紹了引擎如何獲得後向計算圖的依賴,本文我們就接着看看引擎如何依據這些依賴進行後向傳播。通過本文的學習,大家可以:
了解 RecvRpcBackward 如何給對應的下遊節點發送 RPC 消息,可以再次梳理一下worker之間後向傳播的互動流程。
了解 AccumulateGrad 如何在上下文累積梯度。
PyTorch分布式其他文章如下:
深度學習利器之自動微分(1)
深度學習利器之自動微分(2)
[源碼解析]深度學習利器之自動微分(3) --- 示例解讀
[源碼解析]PyTorch如何實作前向傳播(1) --- 基礎類(上)
[源碼解析]PyTorch如何實作前向傳播(2) --- 基礎類(下)
[源碼解析] PyTorch如何實作前向傳播(3) --- 具體實作
[源碼解析] Pytorch 如何實作後向傳播 (1)---- 調用引擎
[源碼解析] Pytorch 如何實作後向傳播 (2)---- 引擎靜态結構
[源碼解析] Pytorch 如何實作後向傳播 (3)---- 引擎動态邏輯
[源碼解析] PyTorch 如何實作後向傳播 (4)---- 具體算法
[源碼解析] PyTorch 分布式(1)------曆史和概述
[源碼解析] PyTorch 分布式(2) ----- DataParallel(上)
[源碼解析] PyTorch 分布式(3) ----- DataParallel(下)
[源碼解析] PyTorch 分布式(4)------分布式應用基礎概念
[源碼解析] PyTorch分布式(5) ------ DistributedDataParallel 總述&如何使用
[源碼解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源碼解析] PyTorch 分布式(7) ----- DistributedDataParallel 之程序組
[源碼解析] PyTorch 分布式(8) -------- DistributedDataParallel之論文篇
[源碼解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源碼解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer靜态架構
[源碼解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 建構Reducer和Join操作
[源碼解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向傳播
[源碼解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向傳播
[源碼解析] PyTorch 分布式 Autograd (1) ---- 設計
[源碼解析] PyTorch 分布式 Autograd (2) ---- RPC基礎
[源碼解析] PyTorch 分布式 Autograd (3) ---- 上下文相關
[源碼解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
[源碼解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
為了更好的說明,本文代碼會依據具體情況來進行相應精簡。
我們首先回顧FAST模式算法算法如下,本文需要讨論後面若幹部分。
我們從具有反向傳播根的worker開始(所有根都必須是本地的)。
查找目前Distributed Autograd Context 的所有<code>send</code>函數 。
從提供的根和我們檢索到的所有<code>send</code>函數開始,我們在本地計算依賴項 。
計算依賴項後,使用提供的根來啟動本地 autograd 引擎。
當 autograd 引擎執行該<code>recv</code>函數時,該<code>recv</code> 函數通過 RPC 将輸入梯度發送到适當的worker。每個<code>recv</code>函數都知道目标 worker id,因為它被記錄為前向傳播的一部分。通過<code>autograd_context_id</code>和 <code>autograd_message_id</code> 該<code>recv</code>函數被發送到遠端主機。
當遠端主機收到這個請求時,我們使用 <code>autograd_context_id</code>和<code>autograd_message_id</code>來查找适當的<code>send</code>函數。
如果這是worker第一次收到對給定 <code>autograd_context_id</code>的請求,它将按照上面的第 1-3 點所述在本地計算依賴項。
然後将在第6點接受到的<code>send</code>方法插入隊列,以便在該worker的本地 autograd 引擎上執行。
最後,我們不是在 Tensor的<code>.grad</code>之上累積梯度,而是在每個Distributed Autograd Context之上分别累積梯度 。梯度存儲在<code>Dict[Tensor, Tensor]</code>之中 ,<code>Dict[Tensor, Tensor]</code>基本上是從 Tensor 到其關聯梯度的映射,并且可以使用 get_gradients() API檢索該映射 。
其次,我們看看總體執行代碼,總體執行是在 DistEngine::execute 之中完成,具體分為如下步驟:
使用 contextId 得到前向的上下文。
使用 validateRootsAndRetrieveEdges 進行驗證。
構造一個GraphRoot,用它來驅動後向傳播,可以認為是一個虛拟根。
使用 computeDependencies 計算依賴。
使用 runEngineAndAccumulateGradients 進行反向傳播計算。
使用 clearAndWaitForOutstandingRpcsAsync 等待 RPC 完成。
再次,從前文我們知道,依賴項已經在 computeDependencies 之中處理完畢,所有需要計算的函數資訊都位于 GraphTask.exec_info_ 之上。我們接下來就看看如何計算,就是 runEngineAndAccumulateGradients 和 clearAndWaitForOutstandingRpcsAsync 這兩個方法。
我們首先看看如何使用 runEngineAndAccumulateGradients 進行反向傳播計算,累積梯度。
引擎之中,首先調用了 runEngineAndAccumulateGradients。主要是封裝了一個 NodeTask,然後以此調用 execute_graph_task_until_ready_queue_empty。其中使用 at::launch 來啟動線程。
at::launch 位于 aten/src/ATen/ParallelThreadPoolNative.cpp,這裡會線上程之中調用傳入的 func。
我們接下來一一看看内部這幾個方法如何執行。
此函數類似 Engine::thread_main,通過一個 NodeTask 來完成本 GraphTask的執行,其中 evaluate_function 會不停的向 cpu_ready_queue 插入新的 NodeTask。engine_.evaluate_function 方法會:
首先,初始化原生引擎線程。
其次,每個調用建立一個 cpu_ready_queue,用來從root_to_execute開始周遊graph_task,這允許用不同的線程來對GraphTask并行執行,這是一個CPU相關的queue。
把傳入的 node_task 插入到 cpu_ready_queue。
沿着反向計算圖從根部開始,一直計算到葉子節點。
這裡葉子節點都是 AccumulateGrad 或者 RecvRpcBackward。
如果是中間節點,則正常計算。
如果是 RecvRpcBackward 則會給對應的下遊節點發送 RPC 消息。
如果是 AccumulateGrad,則在上下文累積梯度。
具體代碼如下:
另外,一共有三個地方調用 execute_graph_task_until_ready_queue_empty。
runEngineAndAccumulateGradients 會調用,這裡就是使用者主動調用 backward 的情形,就是本節介紹的。
executeSendFunctionAsync 會調用,這裡對應了某節點從反向傳播上一節點接受到梯度之後的操作,我們會在下一節介紹。
globalCpuThread 會調用,這是CPU工作專用線程,我們馬上會介紹。
在 Engine.evaluate_function 之中,會針對 AccumulateGrad 來累積梯度。
在 Engine.evaluate_function 之中,會調用 RecvRpcBackward 來向反向傳播下遊發送消息。
我們總結一下幾個計算梯度的流程,分别對應下面三個數字。
上面代碼之中,實際上會調用原生引擎的 evaluate_function 來完成操作。
我們看看如何使用 <code>exec_info_</code>,如果沒有設定為需要執行,則就不處理。在此處,我們可以看到 上文提到的<code>recvBackwardEdges</code> 如何與 <code>exec_info_</code> 互動。
周遊 recvBackwardEdges,對于每個 recvBackward,在 GraphTask.exec_info_ 之中對應項之上設止為需要執行。
具體代碼如下,這裡會:
針對 AccumulateGrad 來累積梯度。
調用 RecvRpcBackward 來向反向傳播下遊發送消息。
globalCpuThread 可以參見上文的 [GPU to CPU continuations] 一節,globalCpuThread是工作線程,其就是從 ready queue 裡面彈出 NodeTask,然後執行。
對于globalCpuThread,其參數 ready_queue 是 global_cpu_ready_queue_
對于普通引擎也會設定一個 cpu 專用 queue。
對于分布式引擎,與普通引擎在計算部分主要不同之處為:
是以我們接下來看看具體這兩部分如何處理。
在之前文章中,我們看到了接受方如何處理反向傳播 RPC 調用,我們接下來看看引擎如何發起反向傳播 RPC 調用,就是如何調用 recv 方法。
這裡就适用于下面worker 0 調用 recv ,執行來到 worker 1 這種情況,對應設計文檔中如下。
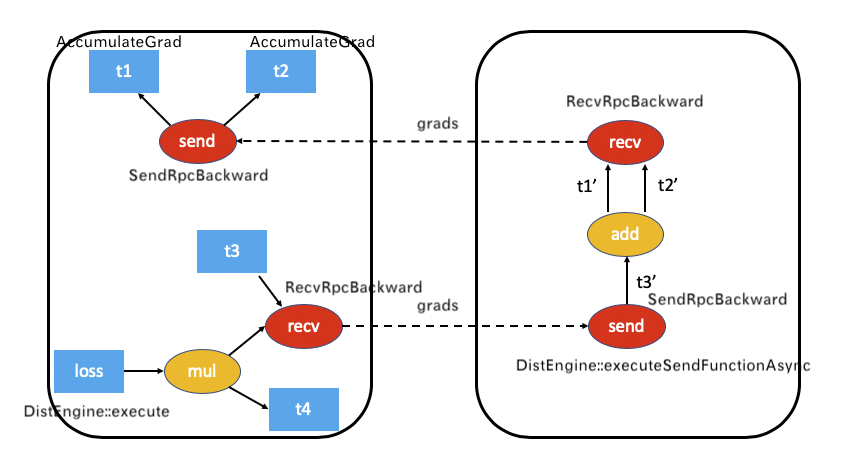
我們就看看如何執行 recv 函數。
具體結合到分布式引擎,就是當引擎發現某一個 Node 是 RecvRpcBackward,就調用其 apply 函數。
RecvRpcBackward 定義如下,
構造函數如下。
torch/csrc/distributed/autograd/functions/recvrpc_backward.cpp 定義了其 apply 函數,其作用就是:
把傳入的梯度 grads 放入outputGrads,因為要輸出給下一環節。
建構 PropagateGradientsReq,這就是 BACKWARD_AUTOGRAD_REQ。
發送 RPC 給下一環節。
因為這裡發送了 PropagateGradientsReq,是以我們接着看。
PropagateGradientsReq 擴充了 RpcCommandBase。
其 toMessageImpl 指明了本消息是 BACKWARD_AUTOGRAD_REQ。
為了論述完整,我們接下來看看接收方如何處理反向傳播。
在生成 TensorPipeAgent 時候,把 RequestCallbackImpl 配置為回調函數。這是 agent 的統一響應函數。前面關于代理接收邏輯時候,我們也提到了,會進入 RequestCallbackNoPython::processRpc 函數。其中可以看到有對 BACKWARD_AUTOGRAD_REQ 的處理邏輯。
這種是 RPC 的正常流程。
在 processBackwardAutogradReq 之中會:
擷取 DistAutogradContainer。
擷取 上下文。
調用 executeSendFunctionAsync 進行引擎處理。
由此,我們可以看到有兩個途徑進入引擎:
一個是示例代碼顯式主動調用 backward,進而調用到 DistEngine::getInstance().execute,就是 worker 0。
一個是被動調用 DistEngine::getInstance().executeSendFunctionAsync,就是 worker 1。
executeSendFunctionAsync 這裡開始進入了引擎,注意,這裡是接收方也進入了引擎,在接收方上進行計算。executeSendFunctionAsync 會直接調用 execute_graph_task_until_ready_queue_empty,也可能先計算依賴然後繼續執行。此處可以參考設計之中的:
6)當遠端主機收到這個請求時,我們使用 <code>autograd_context_id</code>和<code>autograd_message_id</code>來查找适當的<code>send</code>函數。
7)如果這是worker第一次收到對給定 <code>autograd_context_id</code>的請求,它将按照上面的第 1-3 點所述在本地計算依賴項。
8)然後将在第6點接受到的<code>send</code>方法插入隊列,以便在該worker的本地 autograd 引擎上執行。
具體如下圖:
手機如下:

目前看起來總體邏輯已經完成了,但是實際上缺了一塊,對應了設計文檔中的:
就是把異地/本地的梯度累積到本地上下文之中,是以我們再分析一下 DistAccumulateGradCaptureHook。
DistAccumulateGradCaptureHook 有三個作用:
調用原始AccumulateGrad的 pre hooks 來修改輸入梯度。
将 grad 累積到RPC上下文。
調用原始AccumulateGrad的 post hooks。
其定義如下:
如何生成 DistAccumulateGradCaptureHook?計算依賴時候生成 DistAccumulateGradCaptureHook,但是記錄在 capture.hooks_.push_back 之中。
這裡是為了處理 AccumulateGrad。
AccumulateGrad 一定是葉子節點,不需執行,而需要在其上積累梯度,但是RecvRpcBackward需要執行。
AccumulateGrad 就儲存在 DistAccumulateGradCaptureHook 之中。
代碼是縮減版。
首先,execute_graph_task_until_ready_queue_empty 會調用到原始引擎 engine_.evaluate_function。
其次,原始引擎代碼之中,會調用hooks。
DistAccumulateGradCaptureHook 的 operator() 方法之中,會調用下面來累積梯度。
代碼位于 torch/csrc/autograd/functions/accumulate_grad.h。AccumulateGrad 的定義如下:
具體可以如下圖所示,左邊是資料結構,右面是算法流程,右面的序号表示執行從上至下,執行過程之中會用到左邊的資料結構,算法與資料結構的調用關系由橫向箭頭表示。
分布式引擎調用execute_graph_task_until_ready_queue_empty來執行具體的 GraphTask。
Engine::evaluate_function 會調用 GraphTask 之中的 ExecInfo。
然後會通路 GradCaptureHook,調用hook,hook 的 operator函數會調用到 autogradContext_->accumulateGrad。
autogradContext_ 會執行 accumulateGrad,對 hook(DistAccumulateGradCaptureHook)之中儲存的 accumulateGrad_ 做操作。
AccumulateGrad::accumulateGrad 會完成最終的梯度更新操作。
最後,分布式引擎會調用 clearAndWaitForOutstandingRpcsAsync 來等待處理完成。
支援,分布式 autograd 全部分析完畢,前面說過,分布式處理有四大金剛,我們簡介了 RPC,RRef,分析了分布式引擎,從下一篇開始,我們開始分析剩下的分布式優化器,此系列可能包括4~6篇。
Distributed Autograd Design
Remote Reference Protocol
PyTorch 源碼解讀之分布式訓練了解一下?
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
https://pytorch.org/docs/stable/distributed.html#module-torch.distributed
https://pytorch.org/docs/master/notes/autograd.html
https://pytorch.org/docs/master/rpc/distributed_autograd.html
https://pytorch.org/docs/master/rpc/rpc.html
https://www.w3cschool.cn/pytorch/pytorch-cdva3buf.html
PyTorch 分布式 Autograd 設計
Getting started with Distributed RPC Framework
Implementing a Parameter Server using Distributed RPC Framework
Combining Distributed DataParallel with Distributed RPC Framework
Profiling RPC-based Workloads
Implementing batch RPC processing
Distributed Pipeline Parallel