深度學習作為近幾年推動人工智能在機器視覺、語音、自然語言處理等領域取得顯著進展的主要方法,已經發展成一門相對成熟的學科。同時,随着越來越多科技企業和科研機構的投入,深度學習的基礎支撐技術和工程系統也越來越完善,并且呈現百花齊放的局面。以深度學習計算架構為例, Google的Tensorflow擁有最為龐大的粉絲群,Keras在産業界和學界的接受度都有大幅提升,而Caffe在圖像類的模型訓練上依然是很多算法工程師的最愛。同時,還有大量其他開源架構,比如MXNet, Torch, PyTorch, CNTK, deeplearning4j等也都保持快速演進,并且在不同體系結構和計算環境下也都有相應的架構項目。
目前,阿裡雲容器服務提供的深度學習解決方案内置了對Tensorflow, Keras, MXnet架構的環境,并支援基于它們的深度學習模型開發、模型訓練和模型預測。同時,對于模型訓練和預測,使用者還可以通過指定自定義容器鏡像的方式,使用其他深度學習架構。
本文将描述如何通過自定義鏡像的方式,實作使用Caffe架構在GPU裝置上進行多卡模型訓練。
使用阿裡雲容器服務的深度學習解決方案,主要的工作包括:
1.
準備計算資源叢集
a)
購買ECS計算資源,可以包括CPU和GPU;
b)
建立容器叢集管理上述ECS節點;
2.
準備資料存儲,用于儲存和共享訓練資料集、訓練日志和結果模型
建立阿裡雲共享存儲服務執行個體。目前可以支援阿裡雲OSS和NAS存儲服務;
為上述資料存儲建立資料卷,用于将共享存儲執行個體挂載入容器内部。友善訓練、預測代碼從本地目錄讀寫訓練資料等;
3.
在阿裡雲容器服務控制台的解決方案頁面填寫參數,配置、啟動模型訓練任務
以下将就這幾項工作,詳細介紹。
建立容器服務叢集
通過阿裡雲容器服務控制台
<a href="https://cs.console.aliyun.com">https://cs.console.aliyun.com</a>
(首次使用需要免費開通服務),建立容器叢集,詳見文檔
<a href="https://help.aliyun.com/document_detail/52677.html?spm=5176.doc53547.6.900.VyPXtY">https://help.aliyun.com/document_detail/52677.html?spm=5176.doc53547.6.900.VyPXtY</a>
注:
1. 容器叢集所管理的ECS節點資源,可以提前購買好,然後添加到容器叢集内。也可以在建立容器叢集的時候自動購買。但目前自動購買僅支援包年包月的ECS執行個體,在加入容器叢集後可以再修改為按量付費的類型。
2. 不同ECS服務區域,提供的GPU執行個體類型可能不同。需要在提前确認。
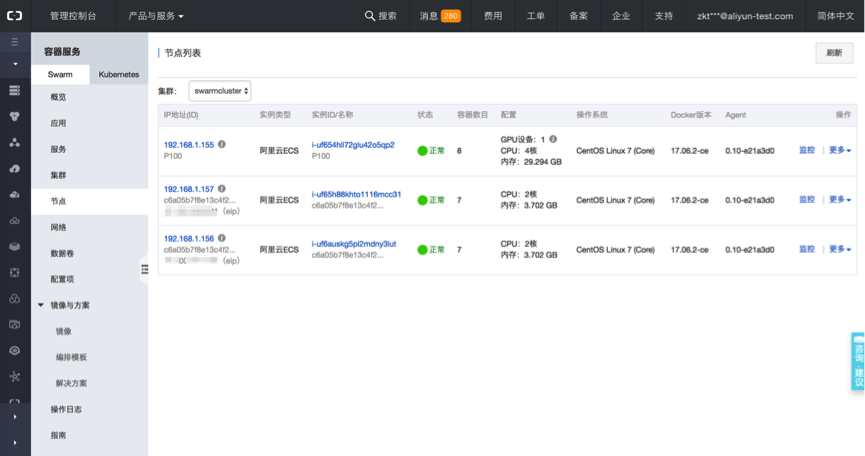
可以在容器服務控制台檢視容器叢集的詳情,如這裡建立的華東2可用區B的容器叢集“swarmcluster”
建立共享資料存儲
容器服務可以通過資料卷挂載的方式支援阿裡雲OSS對象存儲和NAS檔案存儲。首先,需要建立存儲服務執行個體。
注1: 請在與上述ECS節點的相同阿裡雲服務區域,建立OSS或NAS存儲執行個體。否則,運作在ECS上的容器将無法通路它們。
OSS對象存儲執行個體建立方法,詳見
<a href="https://help.aliyun.com/document_detail/31896.html?spm=5176.doc31842.2.5.ug192v">https://help.aliyun.com/document_detail/31896.html?spm=5176.doc31842.2.5.ug192v</a>
我們在華東2區建立OSS bucket“deeplearning-test”,可以檢視其内、外網的通路位址

NAS檔案存儲執行個體建立需要兩步,詳見
1. 建立檔案系統
<a href="https://help.aliyun.com/document_detail/27526.html?spm=5176.doc27527.6.551.t4fGpd">https://help.aliyun.com/document_detail/27526.html?spm=5176.doc27527.6.551.t4fGpd</a>
2. 添加挂載點
<a href="https://help.aliyun.com/document_detail/60431.html?spm=5176.doc27526.6.552.mTQl8H">https://help.aliyun.com/document_detail/60431.html?spm=5176.doc27526.6.552.mTQl8H</a>
建立資料卷
建立好資料存儲執行個體後,需要在容器叢集中建立對應的資料卷。比如,使用OSS作為訓練資料和日志存儲,可以建立OSS資料卷,步驟詳見
<a href="https://help.aliyun.com/document_detail/52681.html?spm=5176.doc52677.6.902.DMpKvy">https://help.aliyun.com/document_detail/52681.html?spm=5176.doc52677.6.902.DMpKvy</a>
這裡我們建立OSS資料卷“ossdata”,用于連接配接上述建立的OSS
bucket “deep learning-test”。
建立NAS資料卷的過程與OSS基本類似。
4.
啟動訓練任務
目前,解決方案還未内置對Caffe架構的支援。可以通過指定自定義鏡像的方式,使用使用者自己的Caffe架構來訓練模型。過程如下,
建構和推送自定義的容器鏡像
使用者在開通容器服務的同時,也會開通容器鏡像倉庫服務。可以使用鏡像倉庫服務,在與叢集相同的阿裡雲區域建立公開的,或者私有的容器鏡像倉庫。并把希望使用的Caffe架構制作成docker鏡像,推送到鏡像倉庫中。以後在該叢集部署的訓練任務就可以使用這個Caffe鏡像了。
容器鏡像倉庫建構的文檔可以參考
<a href="https://help.aliyun.com/document_detail/60997.html?spm=5176.doc60765.6.547.eGFyUs">https://help.aliyun.com/document_detail/60997.html?spm=5176.doc60765.6.547.eGFyUs</a>
<a href="https://help.aliyun.com/document_detail/44535.html?spm=5176.doc25985.6.676.HGxEOq">https://help.aliyun.com/document_detail/44535.html?spm=5176.doc25985.6.676.HGxEOq</a>
在本示例裡,我們可以在華東2區建立鏡像倉庫
registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe,
使用dockerfile和docker build指令在本地建構好acs-caffe的gpu版鏡像,并推送到上述鏡像倉庫中。
具體地,可以在叢集中的一個ECS節點上建立custom_train_caffe.dockerfile檔案,示例内容如下:
該鏡像基于caffe官方基礎鏡像bvlc/caffe:gpu,并使用一個自定義的腳本custom_train_helper.sh作為用鏡像啟動容器時的入口程序。在相同目錄下建立custom_train_helper.sh檔案供dockerfile檔案裡建構鏡像時使用,内容如下:
腳本邏輯很簡單,主要是在執行具體訓練指令的前後期,設定工作目錄,和訓練日志、結果的備份工作。
接下來,在同級目錄下建構自定義鏡像。
然後可以将建構好的鏡像registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu推送到之前在華東2區建立的鏡像倉庫中去。可以參考
<a href="https://help.aliyun.com/document_detail/60743.html?spm=5176.doc60765.6.543.JJch13">https://help.aliyun.com/document_detail/60743.html?spm=5176.doc60765.6.543.JJch13</a>
示例如下:
可以在容器鏡像服務的控制台https://cr.console.aliyun.com,“管理”這個鏡像倉庫。可以檢視到剛剛推送的caffe鏡像的公網、内網位址。
b)
在配置訓練任務的頁面表單裡填入必要的參數:
具體的參數意義和值如下:
<b>叢集</b>:swarmcluster,指定訓練任務運作的叢集
<b>應用名</b>:test-caffe,訓練任務将作為一個容器應用被部署在容器叢集中運作;
<b>訓練架構</b>:選擇自定義鏡像
鏡像位址:填入上述推送的caffe鏡像位址,如
registry.cn-shanghai.aliyuncs.com/dl-frameworks/acs-caffe:gpu
。
<b>分布式訓練</b>:勾選後可指定Parameter
Server架構的分布式訓練任務配置
<b>單worker</b><b>使用GPU</b><b>數量</b>:單機訓練時,任務所使用的GPU卡數量
<b>資料來源</b>:存儲訓練資料集的資料卷,可支援OSS、NAS和本地資料卷
<b>執行指令</b>:執行模型訓練任務的指令。
這裡填寫的指令,和通常啟動訓練時執行的指令是一樣的。可以執行python程式,如
也可以執行shell腳本,比如 "/input/train-mnist.sh"。隻要確定shell檔案存在于容器内正确的路徑下。在任務容器啟動時都會以
“sh –c 指令”的形式自動執行。
本示例中用到的訓練指令是執行腳本“train-mnist.sh”。該腳本隻要提前存放在OSS存儲bucket“deeplearning-test”的根目錄下。
在使用上述建構的鏡像啟動容器時,會通過“ossdata”資料卷自動挂載到容器内的“/input”目錄下。這樣就可以在容器内像執行本地腳本一樣運作“train-mnist.sh”了。
示例腳本内容也很簡單,會運作Caffe自帶的mnist訓練例子。
其中 create_mnist.sh用于準備mnist訓練資料集,代碼如下:
train_lenet.sh腳本用于真正執行Caffe訓練任務,其中指定了模型定義為lenet_solver。代碼如下:
<b>訓練監控</b>:目前隻支援基于Tensorboard的訓練監控可視化服務,本例中先不使用。如果勾選,會自動部署Tensorboard服務,并與下面指定的日志存儲路徑自動關聯。這樣,訓練代碼中輸出的日志可以被Tensorboard讀取。
<b>訓練日志路徑</b>:用于存儲訓練過程中輸出的日志和結果。請在訓練代碼中使用同樣的路徑。
“确定”後,訓練任務将被作為容器應用建立,自動排程到合适的GPU節點,并開始執行訓練指令
c)
檢視訓練容器運作詳情
訓練任務建立後,會以應用容器的方式運作。在容器服務控制台,進入“應用”頁面,可以找到前面建立的任務“test-caffe”。
可以點選應用名,檢視更多任務執行的狀況。
可以看到上述任務有一個容器“test-caffe_worker1”在運作,檢視該容器的運作的節點位置,以及檢視資源監控和日志資訊。也可以通過簡單的web遠端終端,直接進入該容器内部。效果和通過SSH進入容器一樣。
訓練過程輸出的日志會實時地顯示在對應的容器名下。
通過簡單的web遠端終端進入容器内部操作。
根據訓練任務的複雜程度,在等待一段時間後,訓練結束。任務容器會自動退出,釋放所占用的GPU等資源。
至此,通過自定義鏡像的方式,使用者可以使用容器服務簡單、快速地運作基于Caffe等任何深度學習架構的模型訓練。訓練任務排程、計算資源配置設定、GPU使用率優化、資料存儲的內建、叢集管理,監控等工作都不需要額外的投入。