簡單了解:資料倉庫就是整合多個資料源的曆史資料進行細粒度的、多元的分析,幫助高層管理者或者業務分析人員做出商業戰略決策或商業報表。
官方定義:資料倉庫是一個面向主題的(主題明确)、內建的(從不同的資料源采集到同一個資料源)、随時間變化的(關鍵資料是可變的可更新的)、但資訊本身相對穩定(一般隻進行查詢的操作)的資料集合,用于對管理決策過程的支援。
差異項
資料庫
資料倉庫
特征
操作處理
資訊處理
面向
事務
分析
使用者
DBA、開發
經理、主管、分析人員
功能
日常操作
長期資訊需求、決策支援
DB設計
基于ER模型,面向應用
星形/雪花模型,面向主題
資料
目前的、最新的
曆史的、跨時間維護
彙總
原始的、高度詳細
彙總的、統一的
視圖
詳細、一般關系
彙總的、多元的
工作單元
短的、簡單事務
複雜查詢
通路
讀/寫
大多為讀
關注
資料進入
資訊輸出
操作
主鍵索引操作
大量的磁盤掃描
使用者數
數百到數億
數百
DB規模
GB到TB
<code>>=</code>TB
優先
高性能、高可用性
高靈活性
度量
事務吞吐量
查詢吞吐量、響應時間
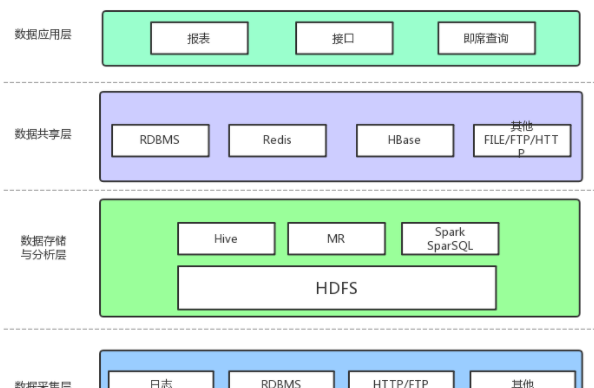
資料采集
資料采集層的任務就是把資料從各種資料源中采集和存儲到資料存儲上,期間有可能會做一些ETL操作。
資料源種類可以有多種:
日志:所占份額最大,存儲在備份伺服器上
業務資料庫:如Mysql、Oracle
來自HTTP/FTP的資料:合作夥伴提供的接口
其他資料源:如Excel等需要手工錄入的資料
資料存儲與分析
HDFS是大資料環境下資料倉庫/資料平台最完美的資料存儲解決方案。
離線資料分析與計算,也就是對實時性要求不高的部分,Hive是不錯的選擇。
使用Hadoop架構自然而然也提供了MapReduce接口,如果真的很樂意開發Java,或者對SQL不熟,那麼也可以使用MapReduce來做分析與計算。
Spark性能比MapReduce好很多,同時使用SparkSQL操作Hive。
資料共享
前面使用Hive、MR、Spark、SparkSQL分析和計算的結果,還是在HDFS上,但大多業務和應用不可能直接從HDFS上擷取資料,那麼就需要一個資料共享的地方,使得各業務和産品能友善的擷取資料。
這裡的資料共享,其實指的是前面資料分析與計算後的結果存放的地方,其實就是關系型資料庫和NOSQL資料庫。
資料應用
報表:報表所使用的資料,一般也是已經統計彙總好的,存放于資料共享層。
接口:接口的資料都是直接查詢資料共享層即可得到。
即席查詢:即席查詢通常是現有的報表和資料共享層的資料并不能滿足需求,需要從資料存儲層直接查詢。一般都是通過直接操作SQL得到。
即席查詢:(Ad Hoc)是使用者根據自己的需求,靈活的選擇查詢條件,系統能夠根據使用者的選擇生成相應的統計報表。即席查詢與普通應用查詢最大的不同是普通的應用查詢是定制開發的,而即席查詢是由使用者自定義查詢條件的。
通常的方式是,将資料倉庫中的次元表和事實表映射到語義層,使用者可以通過語義層選擇表,建立表間的關聯,最終生成SQL語句。

資料采集:采用Flume收集日志,采用Sqoop将RDBMS以及NoSQL中的資料同步到HDFS上
消息系統:可以加入Kafka防止資料丢失
實時計算:實時計算使用Spark Streaming消費Kafka中收集的日志資料,實時計算結果大多儲存在Redis中
機器學習:使用了Spark MLlib提供的機器學習算法
多元分析OLAP:使用Kylin作為OLAP引擎
資料可視化:提供可視化前端頁面,友善營運等非開發人員直接查詢
ETL是資料抽取(Extract)、轉換(Transform)、加載(Load )的簡寫:
它是将OLTP系統中的資料經過抽取,并将不同資料源的資料進行轉換、整合,得出一緻性的資料,然後加載到資料倉庫中。簡而言之ETL是完成從OLTP系統到OLAP系統的過程。
資料倉庫(Data Warehouse\DW)是基于OLTP(聯機事務處理過程)系統的資料源,為了便于多元分析和多角度展現将其資料按特定的模式進行存儲而建立的關系型資料庫。
它不同于多元資料庫,資料庫中的資料是細節的,內建的,資料倉庫是面向主題的,是以OLAP(聯機分析處理)系統為分析目的。
它包括星型架構與雪花型架構,其中星型架構中間為事實表,四周為次元表,類似星星;雪花型架構中間為事實表,兩邊的次元表可以再有其關聯子表,
而在星型中隻允許一張表作為次元表與事實表關聯,雪花型一次元可以有多張表,而星型不可以。考慮到效率時,星型聚合快,效率高,不過雪花型結構明确,便于與OLTP系統互動。
主題(Subject)
主題就是指我們所要分析的具體方面。例如:某年某月某地區某機型某款App的安裝情況。主題有兩個元素:一是各個分析角度(次元),如時間位置;
二是要分析的具體量度,該量度一般通過數值展現,如App安裝量。
維(Dimension)
維是用于從不同角度描述事物特征的,一般維都會有多層(Level:級别),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下圖來展示下維的結構群組成:
以時間維為例,時間維一般會包含年、季、月、日這幾個Level,每個Level一般都會有ID、NAME、
DESCRIPTION這幾個公共屬性,這幾個公共屬性不僅适用于時間維,也同樣表現在其它各種不同類型的維。
分層(Hierarchy)
OLAP需要基于有層級的自上而下的鑽取,或者自下而上地聚合。是以我們一般會在維的基礎上再次進行分層,維、分層、層級的關系如下圖:
每一級之間可能是附屬關系(如市屬于省、省屬于國家),也可能是順序關系(如天周年)
量度
量度就是我們要分析的具體的技術名額,諸如年銷售額之類。它們一般為數值型資料。我們或者将該資料彙總,或者将該資料取次數、獨立次數或取最大最小值等,這樣的資料稱為量度。
粒度
資料的細分層度,例如按天分按小時分。
事實表和維表
事實表是用來記錄分析的内容的全量資訊的,包含了每個事件的具體要素,以及具體發生的事情。事實表中存儲數字型ID以及度量資訊。
維表則是對事實表中事件的要素的描述資訊,就是你觀察該事務的角度,是從哪個角度去觀察這個内容的。
事實表和維表通過ID相關聯,如圖所示:
星型:
雪花型:
雪花形就是在次元下面又細分出次元,這樣切分是為了使表結構更加規範化。雪花模式可以減少備援,
但是減少的那點空間和事實表的容量相比實在是微不足道,而且多個表聯結操作會降低性能,是以一般不用雪花模式設計資料倉庫。
事實星座模式就是星形模式的集合,包含星形模式,也就包含多個事實表。
企業級資料倉庫/資料集市
企業級資料倉庫:突出大而全,不論是細緻資料和聚合資料它全都有,設計時使用事實星座模式
資料集市:可以看做是企業級資料倉庫的一個子集,它是針對某一方面的資料設計的資料倉庫,例如為公司的支付業務設計一個單獨的資料集市。
由于資料集市沒有進行企業級的設計和規劃,是以長期來看,它本身的內建将會極其複雜。其資料來源有兩種,一種是直接從原生資料源得到,
另一種是從企業資料倉庫得到,設計時使用星形模型
主題與業務密切相關,是以設計數倉之前應當充分了解業務有哪些方面的需求,據此确定主題
在确定了主題以後,我們将考慮要分析的技術名額,諸如年銷售額之類。量度是要統計的名額,必須事先選
擇恰當,基于不同的量度将直接産生不同的決策結果。
考慮到量度的聚合程度不同,我們将采用“最小粒度原則”,即将量度的粒度設定到最小。例如如果知道某些資料細分到天就好了,那麼設定其粒度到天;
但是如果不确定的話,就将粒度設定為最小,即毫秒級别的。
設計各個次元的主鍵、層次、層級,盡量減少備援。
事實表中将存在次元代理鍵和各量度,而不應該存在描述性資訊,即符合“瘦高原則”,即要求事實表資料條數盡量多(粒度最小),而描述性資訊盡量少。
參考自:https://www.cnblogs.com/wzlbigdata/p/9458123.html
https://blog.csdn.net/qq_36632174/article/details/102756395