最
近在做資料平台這邊的監控,因為之前一直在用zabbix,而且個人比較傾向于把資料放在資料庫中(這一點nagios和cacti是沒法和zabbix
比的),友善後面做進一步的分析和處理(容量規劃等)。在架構上考慮到擴充性和性能問題,采用了master---proxy的結構,其中proxy使用
active的模式,這樣可以減輕master端的壓力。
談幾個遇到的問題:
1.首先,為了了解zabbix的性能情況,增加了zabbix相關的metric監控
(具體見:http://1662935.blog.51cto.com/1652935/1345664)
2.
監控添加問題,開發了添加監控的前端頁面,使用zabbix
api的方式來一鍵添加監控,完成連結模闆,配置設定分組的操作。其中主機到模闆的連結通過主機名的方式進行比對,缺乏可維護性,因為現在cmdb不可用,和
同僚讨論下來,準備自己在資料庫裡面維護一套資訊(host--process,process--template),每天動态更新。
3.在一個proxy添加了200台機器後,開始遇到了斷圖的問題
比如下面這個:
通
過分析zabbix server 資料庫中history的資料,發現有資料丢失的情況,interval
為60s,1小時應該有60條資料,但是在資料庫中隻有十幾條,進而分析proxy
資料庫中的items表,delay設定是沒有問題的,排除config
sync的問題,分析agent端的日志,發現在agent端就存在資料擷取不完整的問題(agent使用了passive的模式),也就是說proxy
busy造成了擷取資料不完整,調整StartPollers後解決,這個值預設是5,在passive
agent的模式下,遠遠不夠用,建議改成hosts*1.5的值。
4.unreachable 問題
1)
接入機器後,出現大批的host unreachable的報警(agent.ping
item),但是主機是可以通的,通過部署網絡監測腳本,排除agent---proxy---master 3者間的網絡連通問題。通過增大
StartPollersUnreachable和UnreachablePeriod解決。
2)報警問題,zabbix在
ok--->unknown狀态時不會産生報警,是以unreachable的報警不能發現host item擷取值的問題,可通過增加host
update percent監控實作(具體見:http://1662935.blog.51cto.com/1652935/1345789)。
5.叢集整體update percent很低
通過breakdown到host,發現部分host update percent導緻(幾台機器agent有問題,值狀态為unknown)修複後,整體的update percent升高到98%左右。
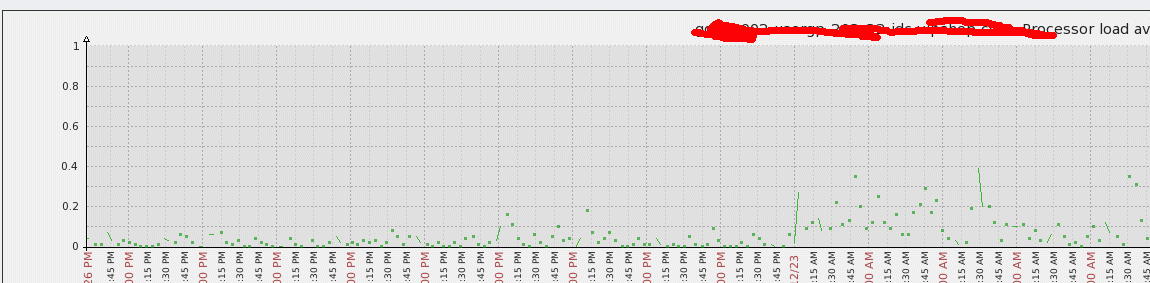
6.proxy伺服器load問題
一
個proxy接入350台左右的叢集,nvps200左右,但是load比較高,因為agent是passive的模式,資料擷取都是proxy負責的,
是以如果item比較多,proxy的壓力就會比較大。考慮轉換agent的模式為active,将壓力分散到agent端,proxy隻負責資料
sync和config sync,調整後,proxy壓力減小了很多,具體見下圖(沒資料的地方是item沒有調整為active導緻)

同時解決了queue過多的問題,調整後,基本沒有超過5分鐘的delay了。
7.housekeeper的問題
master端和proxy端都存在這個問題(proxy不能disable housekeeper),master端可以通過disable 并partition db解決,因為需要停機維護,暫時還沒做調整。
8.db partition
http://caiguangguang.blog.51cto.com/1652935/1354093
通過上面的調整,zabbix基本沒什麼壓力了(單proxy 350台),擴充性也不錯,後面需要做benchmark test,看看能跑到多少nvps.
小結:做zabbix的性能調優之前,要做好zabbix性能的監控,調整中要考慮把壓力分散,master分散至proxy,proxy分散至agent。
對zabbix的工作機制和各種process的作用要了解,對zabbix的資料庫表結構也要有比較好的了解。