在分布式系統中,分布式事務基本上是繞不開的, 分布式事務是指事務的參與者、支援事務的伺服器、資源伺服器以及事務管理器分别位于不同的分布式系統的不同節點之上 。其實就可以簡單了解成在分布式系統中實作事務。
一個簡單的例子,電商系統中,下單接口,一般會有扣庫存,扣積分,然後生成訂單。而一般來說,這三個系統都是不同的服務,我們本地不能控制其他服務的事務,此時如果訂單服務發生了錯誤進行了復原,但遠端的服務,如扣庫存已經調用完成,不能進行復原了。也就是說下單接口的成功與否,不僅取決于本地的 db 操作,而且依賴第三方系統的結果, 這時候分布式事務就保證這些操作要麼全部成功,要麼全部失敗。本質上來說,分布式事務就是為了保證不同資料庫的資料一緻性。
在講分布式事務之前,先回顧下本地事務的知識點。
嚴格意義上的事務實作應該是具備原子性( Atomicity )、一緻性( Consistency )、隔離性( Isolation )和持久性(Durability),簡稱 ACID。
原子性:一系列操作整體不可拆分,要麼都執行,要麼都不執行。
一緻性:事務的執行不能破壞資料庫資料的完整性和一緻性,一個事務在執行之前和執行之後,資料庫都必須處于一緻性狀态
隔離性:事務之間互相隔離, 指的是多個事務并發執行的時候不會互相幹擾,即一個事務内部的資料對于其他事務來說是隔離的。
持久性:一旦事務送出,那麼它對資料庫中的對應資料的狀态的變更就會永久儲存到資料庫中
通俗意義上事務就是為了使得一些更新操作要麼都成功,要麼都失敗。
隔離性中還有一個隔離級别的概念,總共有4個事務隔離級别,不同的隔離級别對事務的處理不同,分别是:未送出讀,已送出讀, 可重複讀,串行化。這裡面又牽扯到三個概念,髒讀、不可重複讀 ,幻讀,我們先了解這三個概念
髒讀:所謂的髒讀,其實就是讀到了别的事務復原前的髒資料
不可重複讀:目前事務先進行了一次資料讀取,然後再次讀取到的資料是别的事務修改成功的資料,導緻兩次讀取到的資料不比對
幻讀:目前事務讀第一次取到的資料比後來讀取到資料條目少
而事務的隔離級别其實就是如何避免這三種
未送出讀:該隔離級别允許髒讀取,其隔離級别最低,也就是啥都沒避免。
已送出讀 :一個事務可以讀取已送出的事務,保證了一個事務不會讀到另一個并行事務已修改但未送出的資料。但是不保證可重複讀,也就是不保證多次讀取資料都相同。
可重複讀:保證多次讀取一個資料時都跟開始讀取的時候一樣, 是以該事務級别禁止不可重複讀取和髒讀取,但是有可能出現幻讀資料。
串行化:是最嚴格的事務隔離級别,它要求所有事務被串行執行,即事務隻能一個接一個的進行處理,不能并發執行。該隔離級别能防止髒讀、不可重複讀、幻讀。
Mysql預設級别是可重複讀,在編寫代碼時是可以進行設定的。
而在Spring中七種事務傳播行為事務的傳播行為概念:
PROPAGATION_REQUIRED:如果目前存在事務,則加入該事務,如果目前不存在事務,則建立一個新的事務。
PROPAGATION_SUPPORTS:如果存在一個事務,支援目前事務。如果沒有事務,則非事務的執行。
PROPAGATION_MANDATORY:如果已經存在一個事務,支援目前事務。如果沒有一個活動的事務,則抛出異常。
PROPAGATION_REQUIRES_NEW:重新建立一個新的事務,如果目前存在事務,延緩目前的事務。
PROPAGATION_NOT_SUPPORTED:以非事務的方式運作,如果目前存在事務,暫停目前的事務。
PROPAGATION_NEVER:總是非事務地執行,如果存在一個活動事務,則抛出異常。
PROPAGATION_NESTED:如果沒有,就建立一個事務;如果有,就在目前事務中嵌套其他事務。
這裡有個點,Spring的事務實作是通過代理類實作的,是以同一個對象内事務調用是預設失效的, 預設隻有在外部調用事務才會生效 。
回顧完本地事務,讓我們回到分布式事務的學習,分布式事務的實作是建立在很多概念之上的,讓我們先來了解下基礎概念吧。
CAP是分布式當中一個非常重要的理論,指的是在一個分布式系統中一緻性 (Consistency)、可用性 (Availability)、分區容錯性(Partition tolerance),三者不可得兼。
一緻性:在分布式系統中的所有資料備份,在同一時刻是否同樣的值。(等同于所有節點通路同一份最新的資料副本)
可用性:在叢集中一部分節點故障後,叢集整體是否還能響應用戶端的讀寫請求。(對資料更新具備高可用性)
分區容錯性:分布式系統在遇到任何網絡分區故障的時候,仍然需要能夠保證對外提供滿足一緻性和可用性的服務,除非整個網絡環境都發生故障。
CAP理論是指一個分布式系統不可能同時滿足一緻性,可用性和分區容錯性這個三個基本需求,最多隻能同時滿足其中兩項。
舉個例子:有A、B、C三個服務,都儲存一份資料是7,而當A服務将這個資料改成8,同步到B時,正常,但同步至C時出現了異常,此時C仍然是7,如果此時依舊要保持一緻性,那麼C服務就不能可用。
放棄P(CA):如果希望能夠避免系統出現分區容錯性問題,一種較為簡單的做法就是将所有的資料(或者是與事物先相關的資料)都放在一個分布式節點上,這樣雖然無法保證100%系統不會出錯,但至少不會碰到由于網絡分區帶來的負面影響。但是這樣其實就不是分布式系統了,
放棄A(CP):其做法是一旦系統遇到網絡分區或其他故障時,那受到影響的服務需要等待一定的時間,應用等待期間系統無法對外提供正常的服務,即不可用
放棄C(AP):這裡說的放棄一緻性,并不是完全不需要資料一緻性,是指放棄資料的強一緻性,保留資料的最終一緻性。
大多數時候我們是選擇AP,也就是選擇放棄一緻性,但是這不是絕對的,在一些業務中,例如,轉賬業務,是放棄了可用性。
BASE 理論指的是基本可用 Basically Available,軟狀态 Soft State,最終一緻性 Eventual Consistency,核心思想是即便無法做到強一緻性,但應該采用适合的方式保證最終一緻性。
BA:Basically Available 基本可用,分布式系統在出現故障的時候,允許損失部分可用性,即保證核心可用。
S:Soft State 軟狀态,允許系統存在中間狀态,而該中間狀态不會影響系統整體可用性。
E:Eventual Consistency 最終一緻性,系統中的所有資料副本經過一定時間後,最終能夠達到一緻的狀态。
這裡需要解釋下強一緻性,弱一緻性和最終一緻性。
強一緻性:任何一次讀都能讀到某個資料的最近一次寫的資料。系統中的所有程序,看到的操作順序,都和全局時鐘下的順序一緻。簡言之,在任意時刻,所有節點中的資料是一樣的。
弱一緻性: 資料更新後,如果能容忍後續的通路隻能通路到部分或者全部通路不到,則是弱一緻性。
最終一緻性: 不保證在任意時刻任意節點上的同一份資料都是相同的,但是随着時間的遷移,不同節點上的同一份資料總是在向趨同的方向變化。簡單說,就是在一段時間後,節點間的資料會最終達到一緻狀态。
上面都是一些理論,用這些理論作為指導,分布式事務有以下一些解決方案
兩階段送出,顧名思義就是要分兩步送出。存在一個負責協調各個本地資料總管的事務管理器,本地資料總管一般是由資料庫實作,事務管理器在第一階段的時候詢問各個資料總管是否都就緒?如果收到每個資源的回複都是 yes,則在第二階段送出事務,如果其中任意一個資源的回複是 no, 則復原事務。
階段1:送出事務請求
事務管理器向所有本地資料總管發起請求,詢問是否是 ready 狀态,所有參與者都将本事務能否成功的資訊回報發給協調者;
事務詢問:協調者向所有的參與者發送事務内容,詢問是否可以執行事務送出操作,并開始等待各參與者的響應
執行事務:各參與者節點執行事務操作,并将Undo和Redo資訊記入事務日志中
如果參與者成功執事務操作,就回報給協調者Yes響應,表示事物可以執行,如果沒有成功執行事務,就回報給協調者No響應,表示事務不可以執行
二階段送出一些的階段也被稱為投票階段,即各參與者投票票表明是否可以繼續執行接下去的事務送出操作
二階段:執行事務送出
假如協調者從所有的參與者或得回報都是Yes響應,那麼就會執行事務送出。
發送送出請求:協調者向所有參與者節點發出Commit請求
事務送出:參與者接受到Commit請求後,會正式執行事務送出操作,并在完成送出之後放棄整個事務執行期間占用的事務資源
回報事務送出結果:參與者在完成事物送出之後,向協調者發送ACK消息
完成事務:協調者接收到所有參與者回報的ACK消息後,完成事務
中斷事務
假如任何一個參與者向協調者回報了No響應,或者在等待逾時之後,協調者尚無法接收到所有參與者的回報響應,那麼就中斷事務。
發送復原請求:協調者向所有參與者節點發出Rollback請求
事務復原:參與者接收到Rollback請求後,會利用其在階段一種記錄的Undo資訊執行事物復原操作,并在完成復原之後釋放事務執行期間占用的資源。
回報事務復原結果:參與則在完成事務復原之後,向協調者發送ACK消息
中斷事務:協調者接收到所有參與者回報的ACk消息後,完成事務中斷
這種解決方案優點是實作簡單,缺點也很明顯:
同步阻塞:當參與事務者存在占用公共資源的情況,其中一個占用了資源,其他事務參與者就隻能阻塞等待資源釋放,處于阻塞狀态。
單點故障:一旦事務管理器出現故障,整個系統不可用
資料不一緻:在階段二,如果事務管理器隻發送了部分 commit 消息,此時網絡發生異常,那麼隻有部分參與者接收到 commit 消息,也就是說隻有部分參與者送出了事務,使得系統資料不一緻。
不确定性:當協事務管理器發送 commit 之後,并且此時隻有一個參與者收到了 commit,那麼當該參與者與事務管理器同時當機之後,重新選舉的事務管理器無法确定該條消息是否送出成功。
還有3PC送出,是對2PC送出做了一些改進
與兩階段送出不同的是,三階段送出有兩個改動點。引入逾時機制。同時在協調者和參與者中都引入逾時機制。在第一階段和第二階段中插入一個準備階段。保證了在最後送出階段之前各參與節點的狀态是一緻的。
三階段送出就有CanCommit、PreCommit、DoCommit三個階段。
TCC 指的是Try - Confirm - Cancel。
Try 指的是預留,即資源的預留和鎖定,注意是預留。
Confirm 指的是确認操作,這一步其實就是真正的執行了。
Cancel 指的是撤銷操作,可以了解為把預留階段的動作撤銷了。
TCC 事務機制相比于上面介紹的 XA,解決了其幾個缺點:
解決了協調者單點,由主業務方發起并完成這個業務活動。業務活動管理器也變成多點,引入叢集。
同步阻塞:引入逾時,逾時後進行補償,并且不會鎖定整個資源,将資源轉換為業務邏輯形式,粒度變小。
資料一緻性,有了補償機制之後,由業務活動管理器控制一緻性
TCC(Try Confirm Cancel) Try 階段:嘗試執行,完成所有業務檢查(一緻性), 預留必須業務資源(準隔離性) Confirm 階段:确認執行真正執行業務,不作任何業務檢查,隻使用 Try 階段預留的業務資源,Confirm 操作滿足幂等性。要求具備幂等設計,Confirm 失敗後需要進行重試。Cancel 階段:取消執行,釋放 Try 階段預留的業務資源 Cancel 操作滿足幂等性 Cancel 階段的異常和 Confirm 階段異常處理方案基本上一緻。
在 Try 階段,是對業務系統進行檢查及資源預覽,比如訂單和存儲操作,需要檢查庫存剩餘數量是否夠用,并進行預留,預留操作的話就是建立一個可用庫存數量字段,Try 階段操作是對這個可用庫存數量進行操作。 基于 TCC 實作分布式事務,會将原來隻需要一個接口就可以實作的邏輯拆分為 Try、Confirm、Cancel 三個接口,是以代碼實作複雜度相對較高。
本地消息表其實就是利用了 各系統本地的事務來實作分布式事務。
當系統 A 被其他系統調用發生資料庫表更操作,首先會更新資料庫的業務表,其次會往相同資料庫的消息表中插入一條資料,兩個操作發生在同一個事務中
系統 A 的腳本定期輪詢本地消息往 mq 中寫入一條消息,如果消息發送失敗會進行重試
系統 B 消費 mq 中的消息,并處理業務邏輯。如果本地事務處理失敗,會在繼續消費 mq 中的消息進行重試,如果業務上的失敗,可以通知系統 A 進行復原操作
本地消息表實作的條件:
消費者與生成者的接口都要支援幂等
生産者需要額外的建立消息表
需要提供補償邏輯,如果消費者業務失敗,需要生産者支援復原操作
容錯機制:
步驟 1 失敗時,事務直接復原
步驟 2、3 寫 mq 與消費 mq 失敗會進行重試
步驟 3 業務失敗系統 B 向系統 A 發起事務復原操作
此方案的核心是将需要分布式處理的任務通過消息日志的方式來異步執行。消息日志可以存儲到本地文本、資料庫或消息隊列,再通過業務規則自動或人工發起重試。人工重試更多的是應用于支付場景,通過對賬系統對事後問題的處理。
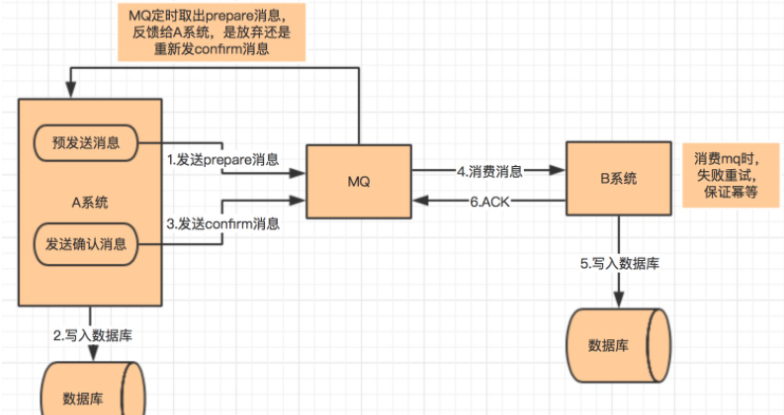
A 系統先向 mq 發送一條 prepare 消息,如果 prepare 消息發送失敗,則直接取消操作
如果消息發送成功,則執行本地事務
如果本地事務執行成功,則想 mq 發送一條 confirm 消息,如果發送失敗,則發送復原消息
B 系統定期消費 mq 中的 confirm 消息,執行本地事務,并發送 ack 消息。如果 B 系統中的本地事務失敗,會一直不斷重試,如果是業務失敗,會向 A 系統發起復原請求
mq 會定期輪詢所有 prepared 消息調用系統 A 提供的接口查詢消息的處理情況,如果該 prepare 消息本地事務處理成功,則重新發送 confirm 消息,否則直接復原該消息
該方案與本地消息最大的不同是去掉了本地消息表,其次本地消息表依賴消息表重試寫入 mq 這一步由本方案中的輪詢 prepare 消息狀态來重試或者復原該消息替代。其實作條件與餘容錯方案基本一緻。目前市面上實作該方案的隻有阿裡的 RocketMq。
最大努力通知是最簡單的一種柔性事務,适用于一些最終一緻性時間敏感度低的業務,且被動方處理結果 不影響主動方的處理結果。
這個方案的大緻意思就是:
系統 A 本地事務執行完之後,發送個消息到 MQ;
這裡會有個專門消費 MQ 的服務,這個服務會消費 MQ 并調用系統 B 的接口;
要是系統 B 執行成功就 ok 了;要是系統 B 執行失敗了,那麼最大努力通知服務就定時嘗試重新調用系統 B, 反複 N 次,最後還是不行就放棄。
![Kafka:Topic概念與API介紹[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)