Apache Kyuubi(Incubating)(下文簡稱Kyuubi)是⼀個建構在Spark SQL之上的企業級JDBC網關,相容HiveServer2通信協定,提供高可用、多租戶能力。Kyuubi 具有可擴充的架構設計,社群正在努力使其能夠支援更多通信協定(如 RESTful、 MySQL)和計算引擎(如Flink)。
Kyuubi的願景是讓大資料平民化。一個的典型使用場景是替換HiveServer2,幫助企業把HiveQL遷移到Spark SQL,輕松獲得10~100倍性能提升(具體提升幅度與SQL和資料有關)。另外最近比較火的兩個技術,LakeHouse和資料湖,都與Spark結合得比較緊密,如果我們能把計算引擎遷移到Spark上,那我們離這兩個技術就很近了。
Kyuubi最早起源于網易,這個項目自誕生起就是開源的。在Kyuubi發展的前兩年,它的使用場景主要在網易内部。自從2020年底進行了一次架構大更新、釋出了Kyuubi 1.0之後,整個Kyuubi社群開始活躍起來了,項目被越來越多的企業采用,然後在今年6月進入了Apache基金會孵化器,并在今年9月釋出了進入孵化器後的第一個版本1.3.0-incubating。
我們通過Kyuubi和其他SQL on Spark方案的對比,看看用Kyuubi替換 HiveServer2能帶來什麼樣的提升。圖中對Hive Server2标記了Hive on Spark,這是Hive2的一個功能,最早的Hive會把SQL翻譯成MapReduce來執行,Hive on Spark方案其實就是把SQL翻譯成Spark算子來執行,但是這僅僅是實體算子的替換,因為複用了Hive的SQL解析邏輯,是以SQL方言還是HiveQL,包括後續SQL的改寫、優化走的都是Hive的優化器。Spark2放棄了Hive on Spark方案,選擇從頭開始做SQL解析、優化,創造了Spark SQL和Catalyst。是以說,Spark Thrift Server隻是相容了HiveServer2的Thrift通信協定,它整個SQL的解析、優化都被重寫了。
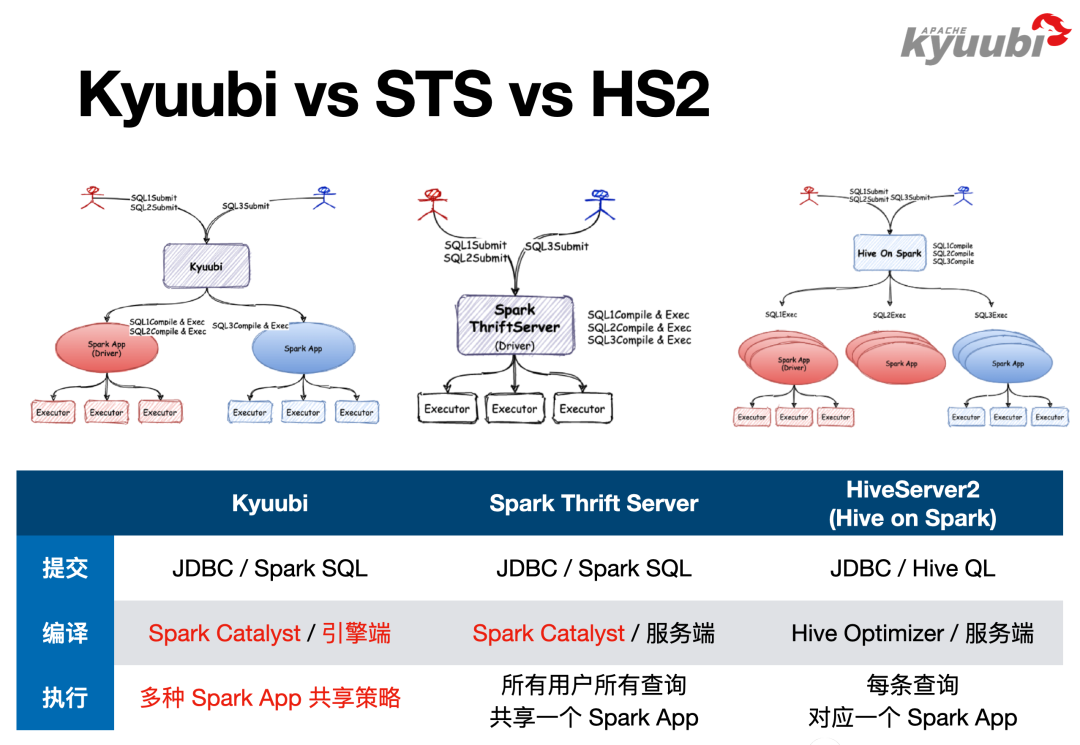
Kyuubi也是用Spark來解析、優化和執行SQL,是以對于使用者來說,用戶端與服務端的通信協定是一模一樣的,因為大家相容的都是HiveServer2的通信協定。但是在SQL方言上,Kyuubi和Spark Thrift Server是Spark SQL,HiveServer2是HiveQL。SQL的編譯和優化過程,HiveServer2在本程序上進行,Spark是在Driver端進行。對于STS,Thrift Server和Driver在同一個程序内;對于Kyuubi,Thrift Server和Spark Driver是分離的,它們可以跑在同一台機器上的不同程序(如YARN Client模式),也可以跑在不同的機器上(如YARN Cluster模式)。
對于執行階段,當一條SQL送出後,HiveServer2會将其翻譯成了一個Spark Application,每一次SQL送出就會生成一個全新的Spark的應用,都會經曆Driver的建立、Executor的建立過程,SQL執行結束後再将其銷毀掉。Spark Thrift Server則是完全相反的方式,一個Spark Thrift Server隻持有一個Driver,Driver是常駐的,所有的SQL都會由這一個Driver來編譯、執行。Kyuubi不僅對這兩種方式都支援,還支援了更靈活的Driver共享政策,會在後續詳細介紹。
CDH是使用最廣泛的Apache Hadoop發行版之一,其本身內建了Spark,但是禁用了Spark Thrift Server功能和spark-sql指令,使得使用者隻能通過spark-shell、spark-submit使用Spark,故而在CDH上使用Spark SQL具有一定的門檻。在CDH上SQL方案用得更多的往往是Hive,比如說我們可以通過Beeline、HUE連接配接HiveServer2,來進行SQL批任務送出或互動式查詢,同時也可以通過Apache Superset這類BI工具連接配接到HiveServer2上做資料可視化展示,背後最終的計算引擎可以是MapReduce,也可以是Spark。

當我們引入Kyuubi後,圖中左側的這些Client都是不需要更改的,隻需要部署Spark3和Kyuubi Server(目前Kyuubi僅支援Spark3),再把Client連接配接位址改一下,即可完成從HiveQL到Spark SQL的遷移。當然其間可能會碰到HiveQL方言跟Spark SQL方言的差異性問題,可以結合成本選擇修改Spark或者修改SQL來解決。
Kyuubi中有一個重要的概念叫作引擎共享級别(Engine Share Level),Kyuubi通過該特性提供了更進階的Spark Driver共享政策。Spark Engine與Spark Driver概念是等價的,都對應一個Spark Application。Kyuubi目前提供了三種Engine共享級别,SERVER、USER和CONNECTION,預設是USER模式。
SERVER模式類似Spark Thrift Server,Kyuubi Server隻會持有一個Spark Engine,即所有的查詢都會送出到一個Engine上來跑。USER模式即每個使用者會使用獨立的Engine,能做到使用者級别的隔離,這也是更具普适性的一種方式,一方面不希望太浪費資源,每個SQL都起一個Engine,另一方面也希望保持一定的隔離性。CONNECTION模式是指Client每建立一個連接配接,就建立一個Engine,這種模式和Hive Server2較為類似,但不完全一緻。CONNECTION模式比較适合跑批計算,比如ETL任務,往往需要數十分鐘甚至幾個小時,使用者不希望這些任務互相幹擾,同時也希望不同的SQL有不同的配置,例如為Driver配置設定2G記憶體還是8G記憶體。總的來說,CONNECTION模式比較适合跑批任務或者大任務,USER模式比較适合HUE互動式查詢的場景。
大家可能會擔心,我們是不是對Spark做了很厚的一層包裝,限制了很多功能?其實不是的,所有的Spark的configuration在Kyuubi中都是可用的。當一個請求發送給Kyuubi時,Kyuubi會去找一個合适的Engine跑這個任務,如果找不到它就會通過拼接spark-submit指令來建立一個Engine,是以所有的Spark支援的configuration都可以用。如圖中列舉了YARN Client和YARN Cluster兩種模式,怎麼寫配置,Spark Driver就跑在什麼地方,改成K8s,Driver就跑在Kubernetes裡面,是以Kyuubi對Kubernetes的支援也是水到渠成的。
還有一個使用者常問的問題,是不是USER模式或者CONNECTION模式,每一個場景都需要單獨部署一套Kyuubi Server?不需要。我們可以把常用的配置固化在kyuubi-defaults.conf裡面,當Client連接配接Kyuubi Server時,可以通過在URL裡面寫一些配置參數來覆寫預設配置項,比如預設使用的是USER模式,送出批任務時選擇CONNECTION模式。
Kyuubi多種靈活的隔離級别是怎麼實作的?下圖綠色的元件即Service Discovery Layer,目前通過ZooKeeper實作,但它本質上是一個服務注冊/發現的元件。我們已經發現有開發者把Kyuubi內建到Kubernetes上,用API Server來實作Service Discovery Layer,該功能目前還沒有送出給社群。
上圖中的User Side即Client側,社群目前政策是完全相容Hive的Client,以更好的複用Hive生态。Hive本身通過ZooKeeper實作了Client側的HA模式,Server啟動以後,會将自身按照一定的規則注冊到ZooKeeper裡面,Beeline或者其他Client連接配接的時候,将連接配接位址設定成ZooKeeper叢集的位址,Client即可以發現指定的路徑下所有的Server,随機選擇其中一個來連接配接。這是HiveServer2協定的一部分,Kyuubi是完全相容的。
Kyuubi Server與Engine之間也使用了類似的服務注冊與發現機制,Engine在Zookeeper上的注冊路徑會遵守一定的規則,例如在USER隔離級别下,路徑規則是/kyuubi_USER/{username}/{engine_node}。Kyuubi Server接到連接配接請求,會按照規則從特定路徑下查找可用的Engine節點。若找到,直接連接配接該Engine;若找不到,建立一個Engine并等待其啟動完成,Engine啟動完成後,會按照相同的規則在指定路徑下建立一個engine節點,并把自己的(包含連接配接位址、版本等)填寫到節點裡。在YARN Cluster模式下,Engine會被配置設定到YARN叢集任意節點啟動,正是通過這種機制,Server才能找到并連接配接Engine。
對于CONNECTION模式,每一個Engine隻會被連接配接一次,為了實作這個效果,Kyuubi設計了如下的路徑規則,/kyuubi_CONNECTION/{username}/{uuid}/{engine_node},通UUID的唯一性來實作隔離。是以Kyuubi實作引擎隔離級别的方式是一個非常靈活的機制,我們目前支援了SERVER、USER和CONNECTION,但通過簡單的擴充,它就可以支援更多更靈活的模式。在代碼主線分支上,社群目前已經實作了額外的兩個共享級别,一個是GROUP,可以讓一組使用者來共享一個Engine;另外一個是Engine Pool,可以讓一個使用者來使用多個Engine以提高并發能力,一個适用的場景是BI圖表展示,例如為Superset配置一個Service Account,對應多個Engine,當幾百個圖表一起重新整理時,可以将計算壓力分攤到不同Engine上。
Kyuubi實踐 | 編譯Spark3.1以适配CDH5并內建Kyuubi https://mp.weixin.qq.com/s/lgbmM1qNetuPB0-j-TAzkQ Apache Kyuubi on Spark 在CDH上的深度實踐 https://my.oschina.net/u/4565392/blog/5264848
我們在Kyuubi的官方公衆号提供了兩篇文章,内容包含了将Kyuubi內建到CDH平台上的具體操作過程,第一篇描述了與CDH5(Hadoop2,啟用Kerberos)的內建,第二篇描述了CDH6(Hadoop3,未啟用Kerberos)的內建。對于內建其他非CDH平台的Hadoop發行版,也具有一定的參考價值。
首先是動态資源配置設定,Spark本身已經提供了Executor的動态伸縮能力。可以看到,這幾個參數配置在語義上是非常明确的,描述了Executor最少能有多少個,最多能有多少個,最大閑置時長,以此控制Executor的動态建立和釋放。
引入了Kyuubi後,結合剛才提到的Share Level和Engine的建立機制,我們可以實作Driver的動态建立,然後我們還引入了一個參數,engine.idle.timeout,約定Driver閑置了多長時間以後也釋放,這樣就實作Spark Driver的動态建立與釋放。
這裡要注意,因為CONNECTION場景比較特殊,Driver是不會被複用的,是以對于CONNECTION模式,engine.idle.timeout是沒有意義的,隻要連接配接斷開Driver就會立刻退出。
Adaptive Query Execution(AQE)是Spark 3帶來的一個重要特性,簡而言之就是允許SQL邊執行邊優化。就拿Join作為例子來說,等值的Inner Join,大表對大表做Sort Merge Join,大表對小表做Broadcast Join,但大小表的判斷發生在SQL編譯優化階段,也就是在SQL執行之前。
我們考慮這樣一個場景,兩個大表和大表Join,加了一個過濾條件,然後我們發現跑完過濾條件之後,它就變成了一個大表和一個小表Join了,可以滿足Broadcast Join的條件,但因為執行計劃是在沒跑SQL之前生成的,是以它還是一個Sort Merge Join,這就會引入一個不必要的Shuffle。這就是AQE優化的切入點,可以讓SQL先跑一部分,然後回頭再跑優化器,看看能不能滿足一些優化規則來讓SQL執行得更加高效。
另一個典型的場景是資料傾斜。我們講大資料不怕資料量大,但是怕資料傾斜,因為在理想情況下,性能是可以通過硬體的水準擴充來實作線性的提升,但是一旦有了資料傾斜,可能會導緻災難。還是以Join為例,我們假定是一個等值的Inner Join,有個别的partition特别大,這種場景我們會有一些需要修改SQL的解決方案,比如把這些大的挑出來做單獨處理,最後把結果Union在一起;或者針對特定的Join Key加鹽,比如加一個數字字尾,将其打散,但是同時還要保持語義不變,就是說右表對應的資料要做拷貝來實作等價的Join語義,最後再把添加的數字字尾去掉。
可以發現,這樣的一個手工處理方案也是有一定規律可循的,在Spark中将該過程自動化了,是以在Spark3裡面開啟了AQE後,就能自動幫助解決這類Join的資料傾斜問題。如果我們的ETL任務裡面有很多大表Join,同時資料品質比較差,有嚴重的資料傾斜,也沒有精力去做逐條SQL的優化,這樣情況從HiveQL遷到Spark SQL上面可以帶來非常顯著的性能提升,10到100倍一點也不誇張!
Spark通過Extension API提供了擴充能力,Kyuubi提供了KyuubiSparkSQLExtension,利用Extension API在原有的優化器上做了一些增強。這裡列舉了其中一部分增強規則,其中有Z-order功能,通過自定義優化器規則支援了資料寫入時Z-order優化排序的的功能,并且通過擴充SQL文法實作了Z-order文法的支援;也有一些規則豐富了監控統計資訊;還有一些規則限制了查詢分區掃描數量,和結果傳回數量等。
以RepartitionBeforeWriteHive為例做下簡單介紹,這條規則用于解決Hive的小檔案寫入問題。對于Hive動态分區寫入場景,如果執行計劃最後一個stage,在寫入Hive表之前,DataFrame的Partition分布與Hive表的Partition分布不一緻,在資料寫入時,每一個task就會将持有的資料寫到很多Hive表分區裡面,就會生成大量的小檔案。當我們開啟RepartitionBeforeWriteHive規則以後,它會在寫入Hive表之前依照Hive表的分區插入一個Repartition算子,保證相同Hive表分區的資料被一個task持有,避免寫入産生大量的小檔案。
Kyuubi為所有規則都提供了開關,如果你隻希望啟用其中部分規則,參考配置文檔将其打開即可。KyuubiSparkSQLExtension提供一個Jar,使用時,可以把Jar拷貝到${SPAKR_HOME}/jars下面,或指令參數--jar添加Jar,然後開啟KyuubiSparkSQLExtension,并根據配置項來選擇開啟特定功能。
Data Source V2 API也是Spark3引入的一個重要特性。Data Source V2最早在Spark 2.3提出,在Spark 3.0被重新設計。下圖用多種顔色标記不同的Spark版本提供的Data Source V2 API,我們可以看到,每個版本都加了大量的API。可以看出,DataSourceV2 API 功能十分豐富,但我們更看重的是它有一個非常良好的擴充性,使得API可以一直進化。
Apache Iceberg在現階段對Data Source V2 API提供了一個比較完整的适配,因為Iceberg的社群成員是Data Source V2 API主要設計者和推動者,這也為我們提供了一個非常好的Demo。
ClickHouse目前在OLAP領域,尤其在單表查詢領域可以說是一騎絕塵,如果我們能結合Spark和ClickHouse這兩個大資料元件,讓Spark讀寫ClickHouse像通路Hive表一樣簡單,就能簡化很多工作,解決很多問題。
基于Data Source V2 API,我們實作了并開源了Spark on ClickHouse,除了适配API提升Spark操作ClickHouse的易用性,也十分注重性能,其中包括了支援本地表的透明讀寫。ClickHouse基于分布式表和本地表實作了一套比較簡單的分布式方案。如果直接寫分布式表,開銷是比較大的,一個變通的方案是修改調整邏輯,手動計算分片,直接寫分布式表背後的本地表,該方案繁瑣且有機率出錯。當使用Spark ClickHouse Connector寫ClickHouse分布式表時,隻需使用SQL或者DataFrame API,架構會自動識别分布式表,并嘗試将對其分布式表的寫入轉化成對本地表的寫入,實作自動透寫本地表,帶來很大的性能提升。
項目位址: https://github.com/housepower/spark-clickhouse-connector
下圖描繪了經過改造之後的新一代資料平台,改造帶來了十分顯著的收益。在硬體資源不變的情況下,首先,Daily Batch ETL從8個小時下降到了2個小時;其次,通過引入Iceberg和增量同步,資料的時效性是從天級降至十分鐘級;第三,收縮計算引擎,原有平台需要搭配Hive、Elasticsearch、Presto、MongoDB、Druid、Spark、Kylin等多種計算引擎滿足不同的業務場景,在新平台中,Spark和ClickHouse可以滿足大部分場景,大大減少了計算引擎的維護成本;最後,縮短了資料鍊路,在以前,受限于RDMS的計算能力,我們往往在資料展示前需要進行一遍一遍的加工,最終把聚合結果放到MySQL裡面,但是當引入ClickHouse以後,通常隻要把資料加工成主題大寬表,報表展示借助ClickHouse強悍的單表計算能力,現場計算就可以了,是以資料鍊路會短很多。
最後展望一下Kyuubi社群未來的發展。剛才提到了Kyuubi架構是可擴充的,目前Kyuubi相容HiveServer2,是因為僅實作了Thrift Binary協定;Kyuubi目前僅支援Spark引擎,Flink引擎正在開發中,這項工作由T3出行的社群夥伴在做。RESTful Frontend社群也正在做,這樣我們也可以提供RESTful API。我們還計劃提供MySQL的API,這樣使用者就可以直接使用MySQL Client或MySQL JDBC Driver來連接配接。後面附了社群裡面相關的issue或者PR。
如下是即将出現在1.4版本中的一些特性,包括剛才已經提到過的Engine Pool、Z-order、Kerberos相關的解決方案,以及新釋出的Spark 3.2的适配工作。
最後展示一下已知使用Kyuubi的企業,如果你也使用Kyuubi,或者在調研企業級的Spark SQL Gateway方案,有任何相關的問題,歡迎可以到我們社群裡面分享、讨論。
GitHub分享頁面: https://github.com/apache/incubator-kyuubi/discussions/925
本文根據網易數帆大資料平台專家、Apache Kyuubi(Incubating) PPMC成員潘成在 Apache Hadoop Meetup 2021 北京站的分享内容整理,重點結合實際落地的案例講述了如何實作 Apache Kyuubi(Incubating) on Spark和CDH內建,以及該方案為企業資料平台建設帶來的收益,并展望了Apache Kyuubi(Incubating) 社群未來的發展。
Apache Kyuubi(Incubating)項目位址:
https://github.com/apache/incubator-kyuubi
視訊回放:
https://www.bilibili.com/video/BV1Lu411o7uk?p=20
案例分享:
Apache Kyuubi 在 T3 出行的深度實踐