首先還是要給自己的開原架構打個廣告 sharding-core 針對efcore 2+版本的分表元件,首先我們來快速回顧下目前市面上分表下針對分頁常見的集中解決方案
解決方案
skip<=100
skip<10000
skip>10000
優點
缺點
記憶體分表
速度快O(n),n=skip*分表數
速度快O(n),n=skip*分表數,記憶體暴漲
O(n),n=skip*分表數,記憶體爆炸,速度越來越慢
實作簡單,支援分庫
skip過大記憶體暴漲
union all
速度快
速度越來越慢
實作簡單
不支援分庫,不好優化,索引可能會失效
流式分表
速度快O(n),n=skip
O(n),n=skip 速度越來越慢
支援分庫
實作複雜,網絡流量随着N增大
顧名思義就是将各個表的結果集合并到記憶體中進行排序後分頁
使用的是資料庫本身的聚合操作,用過匿名表來實作和操作目前表一樣無感覺
和名字一樣就是通過next來一次一次擷取,和datareader類似隻有在next後才可以擷取到用戶端
通過上面的簡單對照我們可以清楚地發現,其實我們可以選擇的基本上就記憶體分表和流式分表而已,又以為記憶體分表的限制其實最優解就是流式分表。
上篇文章我們簡單的介紹了流式分表這次我們在針對流式分表的原理進行介紹,并且提出針對流式分表下的分頁“最優解”。
我們先簡單的假設一個場景,我們有一個訂單表,針對訂單表我們進行了分表,根據訂單的建立時間按月分表。
如果我們執行 select * from order limit 100,2
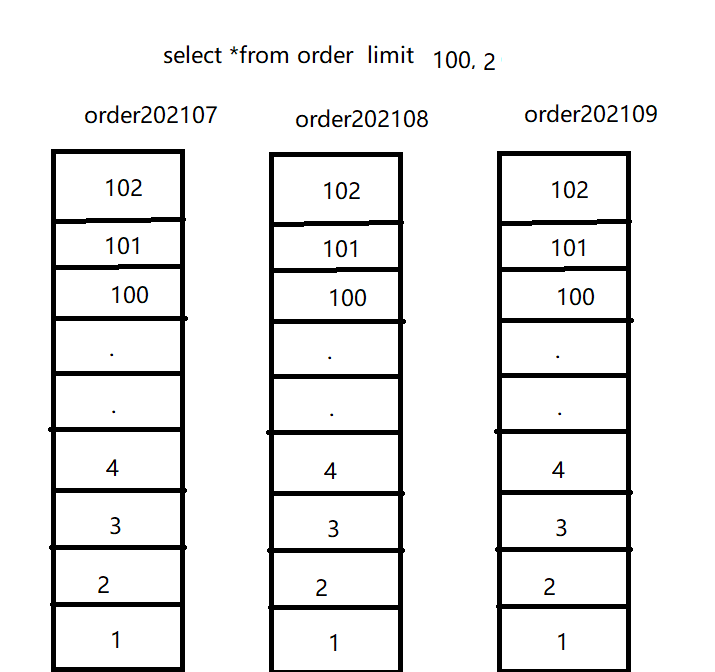
在這種情況下如果我們需要分頁跳過前 100條記錄擷取第101-102條記錄,現在如果記憶體分表情況下我們該如何操作

上述就是記憶體排序的實作,通過上圖發現我們需要擷取102*3條資料,并且進行排序後擷取第101和102條資料,是以說上述表格裡已經展現了記憶體分表的優劣
那麼如果是流式分頁我們是如何操作的呢
簡單解釋下這張圖,右邊為資料庫在資料庫外面的分别是next了一次的資料,其他資料都是在資料庫裡面隻是結果集有了但是結果還不沒有取到client,
通過100次next後我們可以取到真實的資料是以對于任何分頁都是隻需要O(n)的時間複雜度,其中n=skip+take就是跳過多少條和擷取多少條
注意:不要以為next了100次就是查詢了100次資料庫,結果集生成後就不會再查詢資料庫裡,next可以了解為是對結果集的用戶端擷取。
重新解釋:以文章的例子來說,如果你order by了訂單付款金額asc,那麼3張表的三個疊代器(暫時叫a,b,c)内部的順序都是金額小的在前面金額大的在後面,每個疊代器内部都是這樣的對不對。這個是毋庸置疑的,然後如果每個疊代器的頭部第一次互相比較可以比較出 a0.金額>b0.金額>c0.金額,那麼你是金額asc那麼擷取到c0放入記憶體(假設不分頁),然後調用c.next()這樣c就變成了c1再放入優先級隊列,然後優先級隊列變成了a0.金額,b0.金額,c1.金額,這個時候優先級隊列還是能按金額排出一個先後順序,比如b0.金額>c1.金額>a0.金額,那麼就擷取a0到記憶體,然後調用a.next(),變成了a1再放入優先級隊列,是以現在在記憶體裡的永遠比優先級隊列和疊代器後面的小,這個是毋庸置疑的對嗎,是以取到的都是正确的順序資料可以按任何字段排序
至此流式分表擷取資料的原理基本上就是這樣,針對這種情況下我們該如何進行對分頁資料進行優化,因為上圖資料庫子產品内部的區域是未知的也就是說我們是不知道索引“1”後面的索引“2”和其他語句下的目前索引大小情況,我們隻知道索引“1”和索引“2”在本張表裡面的排序情況,
針對這種情況我們應該是沒辦法進行程式的優化了,可以了解為目前情況下已經是最優解了。但是如果我們仔細一想可以發現事情并不簡單
大家能看懂嗎我們隻需要讓程式的擷取方式按順序那麼就可以保證性能最佳 O(1),是以針對時間分表或者順序分表的情況下我們一般情況下使用時間倒序或者順序,那麼就可以告訴程式如何排序,又可以得知,在對應順序的情況下每張表都是順序的又因為隻要保證如下就可以了
有些朋友可能會有疑問,為什麼order by id也可以這樣,其實order by id是不可以這樣的,但是如果你這樣又會怎麼樣?難道資料庫用它最優解排序傳回是正确,程式用最優解排序傳回就不是正确了?
可能有些噴友認為優化到這裡就是差不多了但是其實sharding-core針對優化還不止如此,
因為這種排序需要讓程式知道以某種情況排序可以按表順序排序達到性能最優,但是如果我是Id取模或者範圍就會導緻這個排序僅僅隻适合id排序如果需要按别的來排序就沒辦法了還是得走流式分表.
那麼該如何優化呢還是一樣我們忽略了分頁是2步操作
這種排序僅僅需要的是第一存在order by 第二告訴系統skip多少後需要啟用反排,并且該情況适用于任何的分表規則id取模或者别的其他情況都是可以支援的
sharding-core已經實作了以上所有的解決方案,并且已經在實作第三種優化,就是極不規則情況下的分頁,具體就是當表查詢坐落到3張表後其中2張表或者1張表的count極少的情況下直接取到記憶體然後剩餘的1張表可以直接通過skip+take擷取資料後記憶體排序,
因為時間原因目前還沒實作後續會針對這個情況進行實作。
以上就是我為大家帶來的理論和幹貨,
具體的理論聽得爽了幹貨我再發一遍吧 sharding-core
sharding-core本身使用流式處理擷取資料在普通情況下和單表的差距基本沒有,但是在分頁跳過X頁後,性能會随着X的增大而減小O(n)
目前該架構已經實作了一套高性能分頁可以根據使用者配置,實作分頁功能。
支援版本<code>x.2.0.16+</code>
1.如何開啟分頁配置 比如我們針對使用者月新表進行分頁配置,先實作<code>IPaginationConfiguration<></code>接口,該接口是分頁配置接口
2.添加配置
在對應的使用者月薪路由中添加配置
3.Configure内部為什麼意思?
builder.PaginationSequence(o => o.Id) 配置當分頁orderby 字段為Id時那麼分表所對應的表結構為順序,順序的規則通過<code>UseTailCompare</code>來設定,其中string為表tail,
具體什麼意思就是說如果本次分頁設計3張表分别是table1,table2,table3,如果我沒配置id的情況下那麼需要查詢3張表然後分别進行流式聚合,如果我配置了id的情況下,如果本次sql查詢帶上了id作為order by字段
那麼就不需要分别查詢3張表,可以直接查詢table1如果table1的count大于你要跳過的頁數,假設分頁查詢先查詢多少條,table1:100條,table2:200條,table3:300條
如果你要跳過90條擷取10條原先的時間就是O(100)現在的時間就是O(10)因為table1跳過了90條還剩餘10條;
<code>UseQueryMatch</code>是什麼意思,這個就是表示你要比對的規則,是必須是目前這個類下的屬性還是說隻需要排序名稱一樣即可,因為有可能select new{}匿名對象類型就會不一樣,<code>PrimaryMatch</code>表示是否隻需要第一個主要的
orderby比對上就行了,<code>UseAppendIfOrderNone</code>表示是否需要開啟在沒有對應order查詢條件的前提下添加本屬性排序,這樣可以保證順序排序性能最優
<code>builder.ConfigReverseShardingPage</code> 表示是否需要啟用反向排序,因為正向排序在skip過多後會導緻需要跳過的資料過多,尤其是最後幾頁,如果開啟其實最後幾頁就是前幾頁的反向排序,其中第一個參數表示跳過的因子,就是說
skip必須大于分頁總total*該因子(0-1的double),第二個參數表示最少需要total多少條必須同時滿足兩個條件才會開啟(必須大于500),并且反向排序優先級低于順序排序,
4.如何使用
注意:如果你是按時間排序無論何種排序建議開啟并且加上時間順序排序,如果你是取模或者自定義分表,建議将Id作為順序排序,如果沒有特殊情況請使用id排序并且加上反向排序作為性能優化
首先我們使用 <code>EFCore.BulkExtensions</code>
本機環境 AMD3900X 12核24線程,32GDDR4 3200記憶體 980pro固态 sqlserver2012
針對資料進行建立
一共近295.5w資料耗時24.2秒其中解析表路由耗時3.4秒,插入到本地20.8秒,實際300w訂單肯定要比這個時間長因為測試原因是以建立的訂單表字段比較少
再不起用高性能分表的情況下我們看下
基本在skip 1w後還是可以保持在500ms,skip2w後雖然記憶體波動不大但是基本上耗時也有顯著增加那麼如果開啟了高性能分表呢
直接爆殺有沒有
如果本文章對您有幫助請點下推薦,如果本架構對您有幫助請點下start,Thanks♪(・ω・)ノ github sharding-core