通過ML.NET進行圖檔分類。
一、概述
通過之前兩篇文章的學習,我們應該已經了解了多元分類的工作原理,圖檔的分類其流程和之前完全一緻,其中最核心的問題就是特征的提取,隻要完成特征提取,分類算法就很好處理了,具體流程如下:
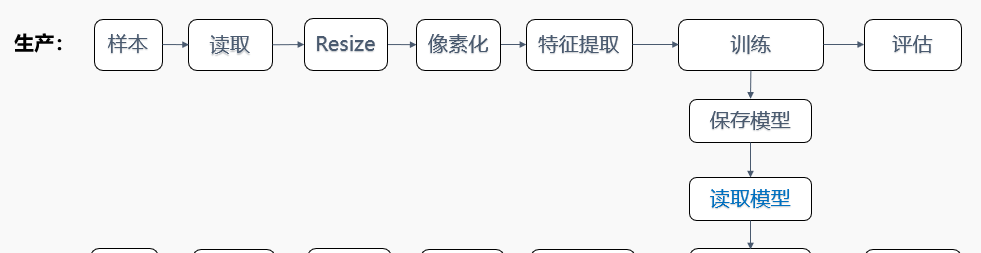
之前介紹過,圖檔的特征是不能采用像素的灰階值的,這部分原理的台階有點高,還好可以直接使用通過TensorFlow訓練過的特征提取模型(美其名曰遷移學習)。
模型檔案為:tensorflow_inception_graph.pb
二、樣本介紹
我随便在網上找了一些圖檔,分成6類:男孩、女孩、貓、狗、男人、女人。tags檔案标記了每個檔案所代表的類型标簽(Label)。

通過對這六類圖檔的學習,期望輸入新的圖檔時,可以判斷出是何種類型。
三、代碼
全部代碼:
View Code
四、分析
1、資料處理通道
可以看出,其代碼流程與結構與上兩篇文章介紹的完全一緻,這裡就介紹一下核心的資料處理模型部分的代碼:
MapValueToKey與MapKeyToValue之前已經介紹過了;
LoadImages是讀取檔案,輸入為檔案名、輸出為Image;
ResizeImages是改變圖檔尺寸,這一步是必須的,即使所有訓練圖檔都是标準劃一的圖檔也需要這個操作,後面需要根據這個尺寸确定容納圖檔像素資訊的數組大小;
ExtractPixels是将圖檔轉換為包含像素資料的矩陣;
LoadTensorFlowModel是加載第三方模型,ScoreTensorFlowModel是調用模型處理資料,其輸入為:“input”,輸出為:“softmax2_pre_activation”,由于模型中輸入、輸出的名稱是規定的,是以,這裡的名稱不可以随便修改。
分類算法采用的是L-BFGS最大熵分類算法,其特征資料為TensorFlow網絡輸出的值,标簽值為"LabelTokey"。
兩個實體類代碼:
上圖檔被識别為girl(我認為是Woman),這個情有可原,本來girl和worman在外貌上也沒有一個明确的分界點。
上圖被識别為woman,這個也情有可原,不解釋。
需要了解的是:不管你輸入什麼圖檔,最終的結果隻能是以上六個類型之一,算法會尋找到和六個分類中特征最接近的一個分類作為結果。
将我們要調試的列加入到實體對象中去,特别要注意資料類型。
檢視資料集詳細資訊:
五、資源擷取
源碼下載下傳位址:https://github.com/seabluescn/Study_ML.NET
工程名稱:TensorFlow_ImageClassification
資源擷取:https://gitee.com/seabluescn/ML_Assets
點選檢視機器學習架構ML.NET學習筆記系列文章目錄
簽名區:
如果您覺得這篇部落格對您有幫助或啟發,請點選右側【推薦】支援,謝謝!