業内經常說的一句話是不要重複造輪子,但是有時候,隻有自己造一個輪子了,才會深刻明白什麼樣的輪子适合山路,什麼樣的輪子适合平地! 我将會持續更新java基礎知識,歡迎關注。
往期章節:
JAVA基礎第一章-初識java JAVA基礎第二章-java三大特性:封裝、繼承、多态 JAVA基礎第三章-類與對象、抽象類、接口 JAVA基礎第四章-集合架構Collection篇
在上一章節中,我們講了集合架構的Collection部分,下面我們來講一下Map接口
我們再看一下集合架構的結構圖
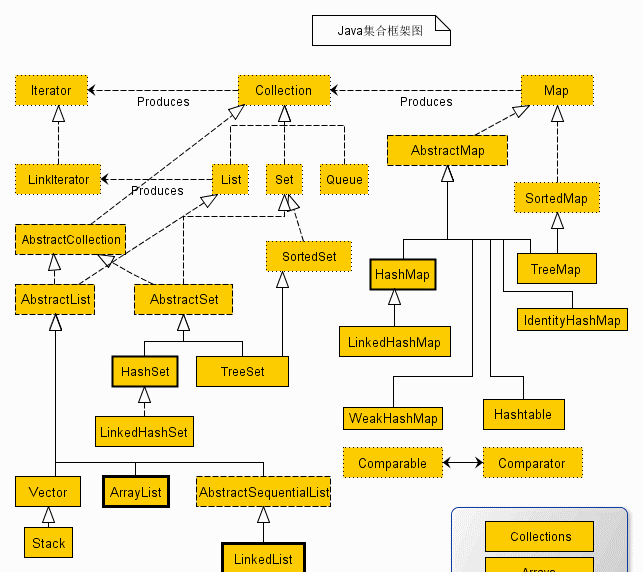
map接口的實作類大緻有 HashMap、LinkedHahMap、TreeMap、HashTable 四類。
Map
從這個名字上我們可以知道是“地圖、映射”的意思。
map集合使用鍵(key)值(value)來儲存資料,其中值(value)可以重複,但鍵(key)必須是唯一,也可以為空,但最多隻能有一個key為空。
HashMap
對于hashMap,我們需要從名字中的hash入手,去分析他,hash,我們經常叫做哈希表又或者叫做散列函數。
在 JDK 中,Object 的 hashcode 方法是本地方法,也就是用 c 語言或 c++ 實作的,該方法直接傳回對象的 記憶體位址。
先看一張圖

如上圖中的結構過程整個形成過程大緻如下:
1,假如我們先插入一個鍵值對,然後進行hash後,存放在了數組的1号位置;
2,然後我們再插入一個鍵值對 ,經過hash後,存在了4号位置,;
3,再然後我們又插入了一個鍵值對,這個時候很不幸,與1号位置沖突,然後這個時候會在1号位置之後追加一個連結清單,讓1号位置的Entry中的next指向這次最新追加的這一個鍵值對,以此類推;
從上圖中我們大概可以了解到,整個的HashMap的資料結構就是 數組+連結清單(在jdk1.8中确切的說是Node對象,隻不過Node實作了Entry接口),我們先看看Node 類的代碼:
從上面的代碼我們可以看出主要有4個屬性,key value、 hash、以及再包含一個自身的類對象Node~ 這部分其實和我們上一節講過的LinkedList的資料結構很像
當我們在代碼中我們會調用put方法,源碼如下:
從注釋中我們可以了解大意:“關聯一個指定的值和鍵在這個map 如果map顯然已經包含了這個鍵的映射,那麼舊值就會被替代”
在這個代碼中繼續調用putval方法,我們繼續看源碼:
從注釋中我們可以知道:實作map.put 和相關的方法
從第14行代碼開始意思是,這個map如果是空的,那先初始化一個數組,然後再new一個 Node對象,放入數組中,具體的位置根據數組的長度和hash的 “與” 值确定 ;
如果已經有元素存在map中,則代碼從19行開始執行,對于這塊大緻意思就是,如果已經存在相同的hashcode ,那麼會判斷鍵是否相同,如果也相同則替換原有的值。
另外關于hashMap的擴容,我們需要了解的是預設的容量是16 重載因子是0.75 什麼意思呢?
就是說當集合中的資料量大小達到了門限值 16*0.75=12,那再添加元素進去,就會對目前的集合進行擴容,擴容為原來的2倍。
注意,這裡是根據門限值進行擴容也就是12,而不是總容量16。
TreeMap
根據名字我們可以知道這是一個和樹有關的map,關于treemap的結構圖大緻如下:
從上圖中可以大概了解到,treemap的實作底層是紅黑樹,了解這個的同學相信也就能知道為什麼treemap是有序的了。
這個圖中的每一個節點對象都是Entry,他和hashmap中的不一樣,而是一個類,不是接口,代碼如下圖所示:
從上圖圈中可以了解到,每一個節點都包含 key、value、 以及Entry類型的 left、right、parent 屬性
上述結構圖形成過程大緻描述如下:
1,我們先插入一個鍵值對,鍵為2;
2,再插入一個鍵為1,這個時候,會将這個鍵值對放在上一個的左子節點部分;
3,再插入一個3,這個時候,會将他放在第一個節點的右子節點部分;
4,如果再插入一個4,那這個時候,會把前面3個整體作為他的左子節點,以此類推;
我們再來看看源碼:
從注釋可以了解,和hashmap表達的意思一樣,再看代碼中,如果還沒有初始化,那先進行初始化root節點,如果有指定比較器,那就根據指定的比較器,進行比較。
然後後面的代碼就是根據插入的鍵進行大小的比較,然後設定各種左右子父節點屬性等。
LinkedHahMap
關于linkedHashMap,從名字可以知道他是和連結清單有關系的,結構圖如下所示:
注意圖中的灰色箭頭,在這裡我們需要和一開始我們講的hashmap中的結構圖,做一個比較,在hashmap中雖然也有連結清單,但是我們要知道,那個連結清單隻是為了解決hash沖突,連結清單中的元素互相之間沒有什麼關系,不代表誰早誰晚,或者說誰大誰小。
而這裡的連結清單中比hashmap多了一個before 和after,如下圖:
那麼這裡的before 和after就确定了插入的順序先後。
HashTable
關于hashTable基本上和HashMap結構一緻,不再贅述,唯一差別就是他是線程安全的,而且不允許null value,如果有直接抛出異常
為什麼是線程安全的?我們看如下源碼:
從上面的方法中加上的 synchronized 關鍵詞,我們就可以知道了。
另外要注意的是hashTable已經不建議使用了,取而代之的是ConcurrentHashMap ,因為他既保證了線程的安全性,又進一步提高了,效率。
四個實作類的異同:
1. HashMap是基于哈希表(hash table)實作,其keys和values都沒有順序。
2. TreeMap是基于紅黑樹(red-black tree)實作,按照keys排序元素,可以指定排序規則,如果不指定則按照自然排序。
3. LinkedHashMap是基于哈希表(hash table)實作,按照插入順序排序元素。
4. Hashtable差別與HashMap的地方隻有,它是同步的(synchronized),是以性能較低些。為了性能,線上程安全的代碼中,優先考慮使用HashMap。
Map的周遊
對于map的周遊大緻有以下3種方式:
比較器
在這裡說以下Comparable 、 Comparator 2個接口
Comparable
隻有一個方法compareto,而且是通過傳回的int型數值判斷大小
1、比較者大于被比較者(也就是compareTo方法裡面的對象),那麼傳回正整數
2、比較者等于被比較者,那麼傳回0
3、比較者小于被比較者,那麼傳回負整數
Comparator
Comparator接口裡面有一個compare方法,方法有兩個參數T o1和T o2,是泛型的表示方式,分别表示待比較的兩個對象,方法傳回值和Comparable接口一樣是int,有三種情況:
1、o1大于o2,傳回正整數
2、o1等于o2,傳回0
3、o1小于o3,傳回負整數
二者之間的差別:
1,比較方法參數數不同;
2,後者接口中提供了更多的方法可以供使用;
3,前者隻能和自己比較,後者可以對其他2個類進行比較;
關于集合部分,到這裡我們就全部結束了。
注;以上源碼分析都是基于jdk1.8
文中若有不正之處,歡迎批評指正!
give me the ball!