叢集報塊丢失的原因很多,如實體磁盤損壞,節點不正常下線退役,叢集高負載時如記憶體打滿卡死,網絡擁堵,系統本身問題等造成節點掉線,如cdh叢集的agent和server失去聯系,非正常下線,心跳逾時等原因造成yarn界面出現塊丢失現象。出現這種現象的底層原理,以及出現這種情況該如何分析,如何應對?
下圖如namenode界面出現提示塊丢失
背景監控到的hdfs圖示

要想弄明白快丢失的原理,首先要弄明白下面的知識點
1. datanode與namenode的通信
所有Datanode會定期向Namenode彙報自身所儲存的檔案block資訊,而namenode則會負責保持檔案的副本數量滿足配置(dfs.replication,預設是3,我們公司是2),根據datanode彙報結果進行删除多餘塊以及複制副本不足的塊等操作。
2. 心跳機制的作用
datanode通過心跳機制與namenoe進行通信,預設是dfs.heartbeat.interval=3s與namnenode通信一次,也是通過心跳機制接受任務等。當namenode連續10次(30s)沒有收到datanode的心跳報告,會判斷datanode可能異常,如出現死亡。此時namenode會主動向datanode主動發送一次檢查,發送一次檢查的時間是5分鐘(預設dfs.namenode.heartbeat.recheck-interval=300000 機關ms)。這個時候如果namenode與datanode通信還是異常,沒有應答,則namenode會繼續重試一次。如果第二次仍讀取不到datanode資訊,則namenode會判定該datanode死亡。合計時間也就是5min*2+30s=10min30s。
3.datanode塊彙報機制
datanode塊彙報分為兩種,IBR(增量塊彙報incremental block reports)、FBR(全量塊彙報 full block reports )。DataNode的BPServiceActor線程在datanode啟動後會一直執行,持續循環發送heartbeat、IBR、FBR。然後根據增量塊彙報會更新各種記錄時間的變量用來輔助調用IBR。比如強制觸發IBR等 。
IBR: 注意dfs.blockreport.incremental.intervalMsec 預設值是0 。 也就是說隻要datanode有如下三種塊變動,即可就會向namenode彙報:1.接受完畢(寫完)的塊。2.剛剛删除完成的塊。3.正在接收(寫入)的塊。這樣的好處是中繼資料維護的及時更新,壞處是過多的RPC請求會增加namenode的負載(因為更新中繼資料的鎖機制)。如果公司叢集單namenode,負載很高的話,可以适當将這個值調整一些比如200ms,實作datanode的IBR延時彙報,這樣datanode可以在間隔時内積攢的所有block一次送出給namenode,進而降低namenode的負載。
FBR:上面說了IBR是針對增量塊的變動彙報。datanode的上block的中繼資料資訊,如block位置,block的狀态等資訊都存放在記憶體中。每隔6個小時,datanode會進行一次Directory Scanners(具體參數:dfs.datanode.directoryscan.interval =21600),通過Directory Scannners檢查記憶體中block資訊和磁盤上實際存儲的block一緻性情況。當Directory Scanners發現block檔案、meta檔案丢失時,或者多餘時(即和磁盤存儲的結果不一緻的那些block),會将block标記為corrupted/invalidates等,datanode然後在下一次彙報中(3s心跳機制),将這個塊彙報給namenode。注意Directory Scanners隻檢查finalized狀态的block(增量block不管)。因為FBR給namenode的壓力太大,尤其對于幾億blocks的大叢集來說,是以每個datanode的全量塊彙報是在6個小時内逐漸完成的(多批次)。這樣的結果就是節點非增量塊的丢失一般極限的話要6個小時後namenode才會感覺,并且通知到使用者。
2.1.塊報丢失實際并沒有丢失
A:生産中某個節點磁盤突然壞盤
datanode會向namenode彙報block corrupted,namenode提示block corrupted。這個時候如果叢集是雙副本,突然單節點壞盤是不會出現兩個副本丢失的情況,這個時候namenode提示的blocck corrupted可以不用管的,最多等6個小時全量塊彙報完成後,就會找回。但是如果是多個節點多個磁盤出現同時損壞,有可能造成資料永久丢失(恰好某個block的所有的副本所在的磁盤都損壞了)。超過6個小時如果沒有找回,基本就是真的丢失了。具體進度可以參考hdfs的監控圖示,如下:
B:節點掉線超過10分30秒(如agent掉線,主機記憶體打滿卡死,rpc請求擁堵等)
這種情況也是namenode檢測到節點掉線,會啟動副本機制補足該節點上的所有副本,這個時候很容易出現RPC風暴,對于網絡帶寬也是個很大的挑戰。這種如果叢集3副本機制,同時掉線兩台也不會出現真正資料丢失;同理叢集是2副本的話,同時出現一台異常,也不會真的資料丢失。一般這種情況被動的做法是等待6小時,等待完成全量塊彙報找回結果。如下出現節點掉線後的帶寬監控,網絡風暴
2.2 塊丢失是真的丢失
通常情況namenode可以恢複絕大多數故障。如果是正好3個副本都同時出現實體永久丢失(注意:如3個副本所在節點同時故障掉線,這種情況即使超過6小時全量塊彙報後仍然顯示丢失,但等這三個節點重新上線後資料依舊可以找回,多餘塊會被删除。但如果是這個三個節點的同時壞盤,資料不可修複的那種,資料通過修複塊或者彙報的方式不可找回)這種情況下,隻能通過重跑任務,重新生成資料了。
HDFS支援fsck指令來檢查各種塊不一緻情況。它設計用于報告各種檔案的問題,例如,檔案缺少的塊或複制不足的塊。但是注意fsck不檢查正在打開的檔案,即正在寫入的檔案。fsck主要就是用來檢查檔案系統的健康狀态,以及定位問題的。
COMMAND_OPTION
Description
path
hdfs fsck 後面跟的path是需要fsck檢查的檔案目錄,或者檔案路徑如 hfds fsck /user/hive/warehouse/aaa.db/,這個path是必須帶的,最簡單也得是/
用來檢查檔案系統的健康狀态
-delete
這個參數用來删除指定目錄下的損壞塊,一般用來删除不可恢複的塊。這種情況要想讓塊丢失提示消失,使用這種方式。
它會删除所有損壞的塊的資料檔案,會導緻資料徹底丢失
-files
Print out files being checked.
輸出正在被檢測的檔案
-files -blocks
Print out the block report
輸出block的詳細報告
-files -blocks -locations
Print out locations for every block.
輸出block的位置資訊
-files -blocks -racks
Print out network topology for data-node locations.
輸出檔案塊位置所在的機架資訊
-files -blocks -replicaDetails
Print out each replica details.
-files -blocks -upgradedomains
Print out upgrade domains for every block.
-includeSnapshots
Include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it.
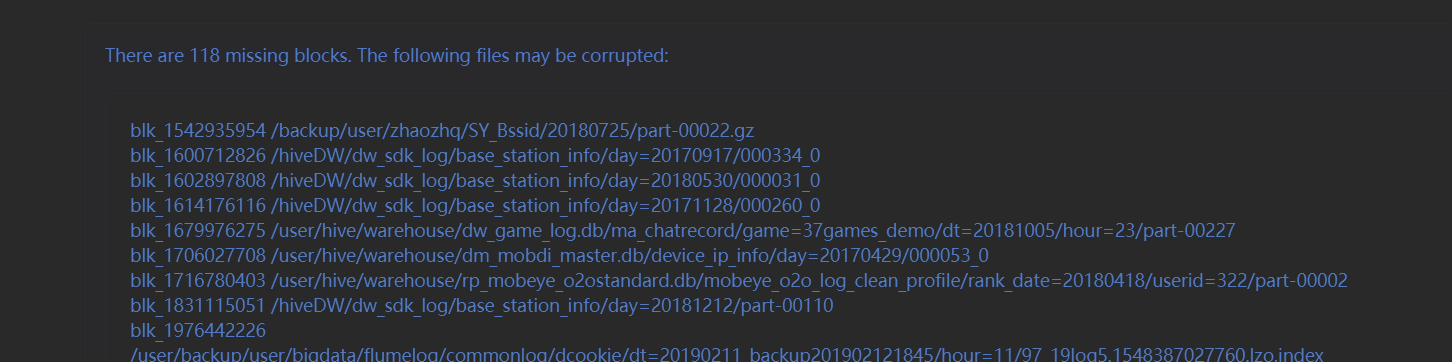
-list-corruptfileblocks
Print out list of missing blocks and files they belong to.常用,列印出所有壞塊的資訊,比如進行補資料等。因為namenode界面顯示是不完整的。
-move
Move corrupted files to /lost+found.
-openforwrite
Print out files opened for write.
-showprogress
Deprecated. A dot is print every 100 files processed with or without this switch.
-storagepolicies
Print out storage policy summary for the blocks.
-maintenance
Print out maintenance state node details.
-blockId
Print out information about the block.