在前面的文章之中,我們已經學習了PyTorch 分布式的基本子產品,接下來我們通過幾篇文章來看看如何把這些子產品應用到實踐之中,順便把PyTorch分布式邏輯整體梳理一下。本文介紹如何把DDP和RPC framework結合起來。
目錄
[源碼解析] PyTorch 分布式(17) --- 結合DDP和分布式 RPC 架構
0x00 摘要
0x00 綜述
0x01 啟動
0x03 支撐系統
3.1 功能
3.2 使用
3.2.1 混合模型
3.2.2 使用
3.3 定義
3.4 主要函數
0x04 HybridModel
0x05 訓練
5.1 初始化
5.2 訓練循環
0x06 比對
0xFF 參考
本文以 COMBINING DISTRIBUTED DATAPARALLEL WITH DISTRIBUTED RPC FRAMEWORK 的翻譯為基礎,加入了自己的了解。
PyTorch分布式其他文章如下:
深度學習利器之自動微分(1)
深度學習利器之自動微分(2)
[源碼解析]深度學習利器之自動微分(3) --- 示例解讀
[源碼解析]PyTorch如何實作前向傳播(1) --- 基礎類(上)
[源碼解析]PyTorch如何實作前向傳播(2) --- 基礎類(下)
[源碼解析] PyTorch如何實作前向傳播(3) --- 具體實作
[源碼解析] Pytorch 如何實作後向傳播 (1)---- 調用引擎
[源碼解析] Pytorch 如何實作後向傳播 (2)---- 引擎靜态結構
[源碼解析] Pytorch 如何實作後向傳播 (3)---- 引擎動态邏輯
[源碼解析] PyTorch 如何實作後向傳播 (4)---- 具體算法
[源碼解析] PyTorch 分布式(1)------曆史和概述
[源碼解析] PyTorch 分布式(2) ----- DataParallel(上)
[源碼解析] PyTorch 分布式(3) ----- DataParallel(下)
[源碼解析] PyTorch 分布式(4)------分布式應用基礎概念
[源碼解析] PyTorch分布式(5) ------ DistributedDataParallel 總述&如何使用
[源碼解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源碼解析] PyTorch 分布式(7) ----- DistributedDataParallel 之程序組
[源碼解析] PyTorch 分布式(8) -------- DistributedDataParallel之論文篇
[源碼解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源碼解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer靜态架構
[源碼解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 建構Reducer和Join操作
[源碼解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向傳播
[源碼解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向傳播
[源碼解析] PyTorch 分布式 Autograd (1) ---- 設計
[源碼解析] PyTorch 分布式 Autograd (2) ---- RPC基礎
[源碼解析] PyTorch 分布式 Autograd (3) ---- 上下文相關
[源碼解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
[源碼解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
[源碼解析] PyTorch 分布式 Autograd (6) ---- 引擎(下)
[源碼解析] PyTorch分布式優化器(1)----基石篇
[源碼解析] PyTorch分布式優化器(2)----資料并行優化器
[源碼解析] PyTorch分布式優化器(3)---- 模型并行
[源碼解析] PyTorch 分布式(14) --使用 Distributed Autograd 和 Distributed Optimizer
[源碼解析] PyTorch 分布式(15) --- 使用分布式 RPC 架構實作參數伺服器
[源碼解析] PyTorch 分布式(16) --- 使用異步執行實作批處理 RPC
注:本文沒有完全按照原文順序進行翻譯,而是按照自己了解的思路重新組織了文章。
本教程使用一個簡單的示例來示範如何将 DistributedDataParallel (DDP) 與分布式 RPC 架構 相結合,将分布式資料并行性與分布式模型并行性相結合,以訓練一個簡單的模型。該示例的源代碼可以在這裡找到。
前面的教程 入門分布式資料并行 和入門分布式RPC架構 分别描述了如何執行分布式資料并行和分布式模型平行訓練。盡管如此,您可能希望在多種訓練範式中結合這兩種技術。例如:
如果我們有一個包含稀疏部分(大型嵌入表)和密集部分(FC 層)的模型,我們可能希望将嵌入表放在參數伺服器上,并使用DistributedDataParallel在多個trainer之間複制 FC 層。分布式RPC架構 就可被用于在參數伺服器上執行嵌入查找。
如PipeDream論文中所述啟用混合并行性。我們可以使用分布式 RPC 架構 将模型的各個階段跨多個worker 進行流水線化,并使用DistributedDataParallel 對每個階段進行資料并行(如果需要)。
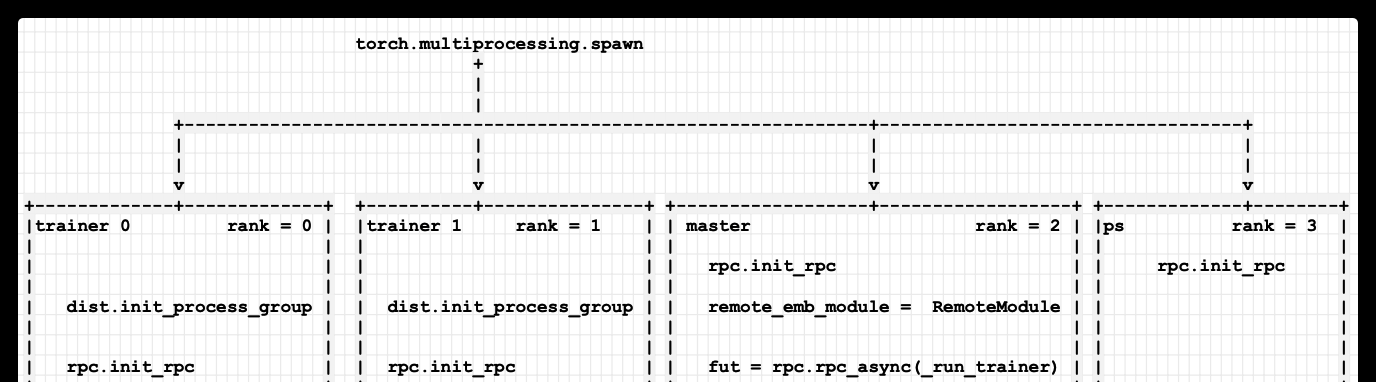
在本教程中,我們将介紹上述案例 1。我們的設定中共有 4 個 worker,如下所示:
1 個Master,負責在參數伺服器上建立嵌入表(nn.EmbeddingBag)。master 還負責驅動兩個trainer上的訓練循環。
1 個Parameter Server,它将嵌入表儲存在記憶體中,并響應來自 Master 和 Trainer 的 RPC 請求。
2 個trainer,它存儲一個 FC 層 (nn.Linear),其使用DistributedDataParallel 進行資料并行。trainer還負責執行前向傳播、後向傳播和優化器步驟。
整個訓練過程執行如下:
Master 建立一個RemoteModule ,在參數伺服器上儲存一個嵌入表。
Master 在trainer上啟動訓練循環,并将遠端子產品(remote module)傳播給trainer。
Trainer 建立一個<code>HybridModel</code>,其首先使用 master 提供的遠端子產品執行嵌入查找(embedding lookup),然後執行封裝在 DDP 中的 FC 層。
Trainer 執行模型的前向傳播,并使用Distributed Autograd 對損失執行後向傳播。
作為反向傳播的一部分,首先計算 FC 層的梯度,并通過 DDP 中的 allreduce 同步到所有trainer。
接下來,分布式 Autograd 将梯度傳播到參數伺服器,在那裡更新嵌入表的梯度。
最後,分布式優化器被用于更新所有參數。
注意:如果您将 DDP 和 RPC 結合使用,則應始終使用Distributed Autograd進行反向傳播。
我們看看系統如何啟動。首先,在進行訓練之前,需要設定所有worker。我們建立了 4 個程序,其中 rank 0 和 rank 1 是我們的trainer,rank 2是master,rank 3是參數伺服器。
初始化邏輯如下:
我們使用 TCP init_method 在所有 4 個 worker 上初始化 RPC 架構。
對于 Master,代碼做了如下操作:
完成 RPC 初始化後,master 建立一個遠端子產品RemoteModule,該子產品指向一個在參數伺服器上儲存的EmbeddingBag層。
然後 master 周遊每個trainer,并通過使用rpc_async調用<code>_run_trainer</code> 在每個trainer之上啟動訓練循環。
最後,master 在退出之前等待所有訓練完成。
Trainers做了如下操作:
Trainers 首先使用 init_process_group為DDP初始化一個world_size = 2(對于兩個trainer)的<code>ProcessGroup</code>。
接下來,Trainers 使用 TCP init_method 初始化 RPC 架構。注意RPC初始化和ProcessGroup初始化的端口是不同的。這是為了避免兩個架構的初始化之間的端口沖突。
初始化完成後,trainer隻需等待來自 master的<code>_run_trainer</code> RPC。
參數伺服器隻是初始化 RPC 架構并等待來自trainer和master的 RPC。
具體代碼如下:
目前邏輯如下,我們後續會繼續拓展:
手機如下:
支撐系統主要指的就是 _RemoteModule,其作用是在異地建立一個模型,具體代碼在:torch/distributed/nn/api/remote_module.py。
RemoteModule執行個體隻能在RPC初始化之後建立,它可以在指定的遠端節點上建立使用者指定的子產品,其行為類似于正常的<code>nn.Module</code>方法,但不同之處是 RemoteModule 在遠端節點上執行<code>forward</code>方法。RemoteModule 負責autograd recording,以確定向後傳播可以将梯度傳播回相應的遠端子產品。
RemoteModule 可以使用<code>RPC framework <https://pytorch.org/docs/stable/rpc.html></code> 在處理器之間共享,且不會産生複制實際子產品的任何開銷,這相當于使用一個<code>~torch.distributed.rpc.RRef</code>指向遠端子產品。
要建立混合模型,通常應該在遠端子產品之外建立本地子產品,而不是作為任何遠端子產品的子子產品。如果遠端子產品放置在cuda裝置上,那麼任何輸入CPU張量将自動移動到同一cuda裝置之上。混合模型例子如下:
使用例子如下,需要在兩個不同程序上運作如下代碼,例子之中,RemoteModule 建立時候,傳入了一個"worker1/cpu"參數,意思是在 worker1 的 cpu 裝置上運作這個RemoteModule。具體格式是: <code><workername> / <device></code>,其中 <code><device></code> 是torch.device類型。
_RemoteModule定義如下,具體初始化邏輯是:
(1). 準備參數。
(2). 設定運作的遠端worker和遠端裝置。
(3). 如果設定了<code>_module_interface_cls</code> 。
(3.1) 使用 <code>_module_interface_cls</code> 來在遠端構模組化塊。_
(3.2) 在本地建構函數代理生成器。
(3.3) 等待建立完成。
(3.4) 在本地建構句柄。
(4) 沒有設定_module_interface_cls。
(4.1) 在本地建構函數代理生成器。
(4.2) 在遠端建立子產品。
(5). 在本地建立遠端函數代理。
其主要函數如下:
rpc.rpc_sync 傳回指向遠端子產品參數的<code>~torch.distributed.rpc.RRef</code>清單。通常可以與<code>~torch.distributed.optim.DistributedOptimizer</code>結合使用。
get_module_rref 傳回一個指向遠端子產品的<code>~torch.distributed.rpc.RRef(RRef[nn.Module])</code>類。
于是邏輯圖轉換如下,在上圖基礎之上多了一個remote_emb_module,其在ps之上建立了一個RemoteModule。

在讨論 Trainer 的細節之前,讓我們先介紹一下 Trainer使用的<code>HybridModel</code>。該模型由稀疏部分和稠密部分組成。
稠密部分是一個nn.Linear,使用DistributedDataParallel在所有trainer中複制,即 在 DDP 内包裝了一個 nn.Linear層。
稀疏部分是一個遠端子產品 (<code>remote_emb_module</code>) ,它持有一個在參數伺服器上的nn.EmbeddingBag。即,此遠端子產品可以擷取參數伺服器上嵌入表的遠端引用。
該模型的前向方法非常簡單。它使用 RemoteModule 在參數伺服器上執行嵌入查找<code>forward</code> ,并将其輸出傳播到 FC 層,這裡的 FC 使用了DDP。
邏輯拓展如下,兩個trainer 之上也建立了remote_emb_module,指向了ps之上的RemoteModule。
之前初始化時候,我們漏過了trainer的初始化,這裡我們分析一下。
我們先看看 Trainer 上的設定。
首先,trainer使用遠端子產品(remote module)和自己的rank 來建立上面提到的 <code>HybridModel</code>,遠端子產品持有參數伺服器上的嵌入表。
其次,我們需要得到一個RRef 清單,該清單指向我們想要使用DistributedOptimizer優化的所有參數。
要從參數伺服器嵌入表之中拿到這些參數,我們可以調用 RemoteModule 的remote_parameters,它會周遊嵌入表的所有參數并傳回一個 RRef 清單。trainer通過 RPC 在參數伺服器上調用此方法來得到所需參數的 RRef 清單。
由于 DistributedOptimizer 始終持有一個需要優化參數的 RRef 清單,是以我們需要為 FC 層的局部參數建立 RRef。這是通過周遊<code>model.fc.parameters()</code>來完成的,其将為每個參數建立一個 RRef 并将其附加到從<code>remote_parameters()</code>傳回的清單中。
請注意,我們不能使用<code>model.parameters()</code>,因為它會遞歸調用<code>model.remote_emb_module.parameters()</code>,而<code>RemoteModule</code>不支援這種操作。
最後,我們使用所有 RRef 建立我們的 DistributedOptimizer 并定義一個 CrossEntropyLoss 函數。
我們邏輯拓展如下,這裡省略了 trainer 0 指向 參數伺服器的箭頭,與上圖相比,增加了 DistributedOptimizer。
現在我們介紹在每個trainer上運作的主訓練循環。這裡 <code>get_next_batch</code>隻是一個輔助函數,用于生成随機輸入和訓練目标。我們為多個epoch和每個batch運作該訓練循環:
為Distributed Autograd.設定Distributed Autograd Context 。
運作模型的前向傳播并拿到其輸出。
使用損失函數根據我們的輸出和target來計算損失。
使用 Distributed Autograd 對損失執行分布式反向傳播。
最後,運作分布式優化器step 來優化所有參數。
因為篇幅所限,我們隻是把上面的trainer再細化如下圖:
初始化時候,調用 dist.init_process_group 來初始化 DistributedDataParallel,調用 rpc.init_rpc 來初始化 RPC。
HybridModel 之中,fc 是DistributedDataParallel方式,remote_emb_module 是參數伺服器上的 RemoteModule。
DistributedOptimizer 之中,對于 HybridModel 的 fc 和 remote_emb_module 都會進行分布式優化。
_run_trainer 之中,使用 model(indices, offsets) 進行前向傳播,其中會調用到 HybridModel.forward。
HybridModel.forward 之中則對embedding 和 fc 進行操作。
embedding 是利用RPC 和 參數伺服器。
fc 是利用 DistributedDataParallel。
将嵌入表放在參數伺服器上,并使用DistributedDataParallel 在多個trainer之間複制 FC 層。
這些序号與下圖中數字對應。
注,可以在此處找到整個示例的源代碼。
我們已經看了三篇PyTorch官方樣例,裡面對參數伺服器的實作各有不同。對于本文來說,又加入了一個master作為協調者來統一各個worker。
總的來說,在PyTorch 之中,因為有了 RPC 機制,是以PyTorch 的參數伺服器實作比 ps-lite, paracel 更佳靈活機動:
首先參數伺服器目前可以放在 GPU 之中。
其次,可以在參數伺服器隻放置參數,也可以運作優化代碼,甚至可以在參數服務之上啟動控制trainer。
具體優化器根據實際需要,可以是普通優化器,也可以是DistributedOptimizer。
訓練代碼從使用者編寫角度看則完全是運作在本地。
COMBINING DISTRIBUTED DATAPARALLEL WITH DISTRIBUTED RPC FRAMEWORK