要使決策樹完整而有效,它必須包含所有的可能性。事件序列也必須提供,并且是互斥的,這意味着如果一個事件發生,另一個就不能發生。
決策樹是監督機器學習的一種形式,因為我們必須解釋輸入和輸出應該是什麼。有決策節點和葉子。葉子是決策,不管是否是最終決策,節點是決策分裂發生的地方。
雖然有很多算法可供我們使用,但我們将使用疊代二分法(ID3)算法。
在每個遞歸步驟中,根據一個标準(資訊增益、增益比等)選擇對我們正在處理的輸入集進行最佳分類的屬性。
這裡必須指出的是,無論我們使用什麼算法,都不能保證生成盡可能小的樹。因為這直接影響到算法的性能。
請記住,對于決策樹,學習僅僅基于啟發式,而不是真正的優化标準。讓我們用一個例子來進一步解釋這一點。
下面的示例來自http://jmlr.csail.mit.edu/papers/volume8/esmeir07a/esmeir07a.pdf,它示範了XOR學習概念,我們所有的開發人員都(或應該)熟悉這個概念。稍後的例子中也會出現這種情況,但現在a3和a4與我們要解決的問題完全無關。它們對我們的答案沒有影響。也就是說,ID3算法将選擇其中一個建構樹,事實上,它将使用a4作為根節點!記住,這是算法的啟發式學習,而不是優化結果:
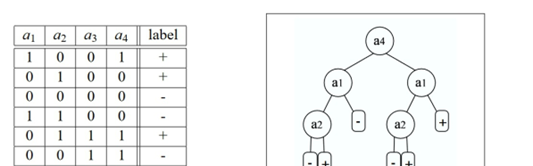
希望這張圖能讓大家更容易了解剛剛所說的内容。我們的目标并不是深入研究決策樹機制和理論。而是如何使用它,盡管存在很多問題,但決策樹仍然是許多算法的基礎,尤其是那些需要對結果進行人工描述的算法。這也是我們前面試試人臉檢測算法的基礎。
決策樹的一個節點。每個節點可能有關聯的子節點,也可能沒有關聯的子節點
此對象定義樹和節點可以處理的每個決策變量的性質。值可以是範圍,連續的,也可以是離散的。
此集合包含将一個或多個決策節點組,以及關于決策變量的附加資訊,以便進行比較。
下面是一個用于确定金融風險的決策樹示例。我們隻需要在節點之間導航,就可以很容易地跟随它,決定要走哪條路,直到得到最終的答案。在這種情況下,當有人正在申請貸款,而我們需要對他們的信用價值做出決定。這時決策樹就是解決這個問題的一個很好的方法:

你剛剛得到一份新工作,你需要決定是否接受它。有一些重要的事情需要考慮,是以我們将它們作為輸入變量或特性,用于決策樹。
對你來說最重要的是:薪水、福利、公司文化,當然還有,我能在家工作嗎?
我們将建立一個記憶體資料庫并以這種方式添加特性,而不是從磁盤存儲中加載資料。我們将建立DataTable并建立列,如下圖所示:
在這之後,我們将加載幾行資料,每一行都有一組不同的特性,最後一列應該是Yes或No,作為我們的最終決定:
一旦所有的資料都建立好并放入表中,我們就需要将之前的特性轉換成計算機能夠了解的表示形式。
由于數字更簡單,我們将通過一個稱為編碼的過程将我們的特性(類别)轉換為一本代碼本。該代碼本有效地将每個值轉換為整數。
注意,我們将傳遞我們的資料類别作為輸入:
接下來,我們需要為決策樹建立要使用的決策變量。
這棵樹會幫助我們決定是否接受新的工作邀請。對于這個決策,将有幾類輸入,我們将在決策變量數組中指定它們,以及兩個可能的決策,是或者否。
DecisionVariable數組将儲存每個類别的名稱以及該類别可能的屬性的總數。例如,薪水類别有三個可能的值,高、平均或低。我們指定類别名和數字3。然後,除了最後一個類别(即我們的決定)之外,我們對所有其他類别都重複這個步驟:
現在我們已經建立了決策樹,我們必須教它如何解決我們要解決的問題。為了做到這一點,我們必須為這棵樹建立一個學習算法。由于我們隻有這個示例的分類值,是以ID3算法是最簡單的選擇。
一旦學習算法被運作,它就會被訓練并可供使用。我們簡單地為算法提供一個樣本資料集,這樣它就可以給我們一個答案。在這種情況下,薪水不錯,公司文化不錯,福利也不錯,我可以在家工作。如果正确地訓練決策樹,答案将會是是:
numl是一個非常著名的開源機器學習工具包。與大多數機器學習架構一樣,它的許多示例也使用Iris資料集,包括我們将用于決策樹的那個。
下面是我們的numl輸出的一個例子:
讓我們看一下這個例子背後的代碼:
這個方法并不複雜,對吧?這就是在應用程式中使用numl的好處;它非常容易使用和內建。
上述代碼建立描述符和DecisionTreeGenerator,加載Iris資料集,然後生成模型。這裡隻是正在加載的資料的一個示例:
Accord.NET framework也有自己的決策樹例子。它采用了一種不同的、更圖形化的方法來處理決策樹,但是您可以通過調用來決定您喜歡哪個決策樹,并且最習慣使用哪個決策樹。
一旦資料被加載,您就可以建立決策樹并為學習做好準備。您将看到與這裡類似的資料圖,使用了X和Y兩個類别:
下一個頁籤将讓您看到樹節點、葉子和決策。右邊還有一個自頂向下的樹的圖形視圖。最有用的資訊在左邊的樹形視圖中,你可以看到節點,它們的值,以及做出的決策:
最後,最後一個頁籤将允許您執行模型測試:
下面是學習代碼
然後他的值被輸入一個混淆矩陣。對于不熟悉這一點的同學,讓我簡單解釋一下.
混淆矩陣是用來描述分類模型性能的表。它在已知真值的測試資料集上運作。這就是我們如何得出如下結論的。
在這個例子中,我們預測是,這是事實。
在這種情況下,我們預測否,這是事實。
在這種情況下,我們預測是,但事實并非如此。有時您可能會看到這被稱為type 1錯誤。
在這種情況下,我們預測“否”,但事實是“是”。有時您可能會看到這被type 2類錯誤。
現在,說了這麼多,我們需要談談另外兩個重要的術語,精确度和回憶。
讓我們這樣來描述它們。在過去的一個星期裡,每天都下雨。這是7天中的7天。很簡單。一周後,你被問到上周多久下一次雨?
它是你正确回憶下雨的天數與正确事件總數的比值。如果你說下了7天雨,那就是100%。如果你說下了四天雨,那麼57%的人記得。在這種情況下,它的意思是你的回憶不是那麼精确,是以我們有精确度來識别。
它是你正确回憶将要下雨的次數與那一周總天數的比值。
對我們來說,如果我們的機器學習算法擅長回憶,并不一定意味着它擅長精确。有道理嗎?這就涉及到其他的事情,比如F1的分數,我們會留到以後再講。
以下是一些可能會有幫助的可視化:
識别真陽性和假陰性:
使用混淆矩陣計算統計量後,建立散點圖,識别出所有内容:
在這一章中,我們花了很多時間來研究決策樹;它們是什麼,我們如何使用它們,以及它們如何使我們在應用程式中受益。在下一章中,我們将進入深度信念網絡(DBNs)的世界,它們是什麼,以及我們如何使用它們。
我們甚至會談論一下計算機的夢,當它做夢的時候!
“老天爺給你的任何機會,你也不會珍惜,更不會深入下去,你認為自己就是窮命,最喜歡通過脈脈閱讀免費的職場技巧。如果你還是杠精思維,任何事情,跑上來先論證困難,給自己一個不幹不參與的充分理由,那你完了。人生不過是短短十五年的機會,到了四十歲,你還在屌絲堆裡,啥也不幹,那你沒希望了。”