接着昨日的旅程,我們應該開始處理具體的子路徑了:
【fs/namei.c】sys_open->do_sys_open->do_filp_open->path_openat->link_path_walk
點選(此處)折疊或打開
...
err = walk_component(nd, &next, LOOKUP_FOLLOW);
if (err 0)
return err;
if (err) {
err = nested_symlink(&next, nd);
if (err)
return err;
}
現在,我們可以肯定目前的子路徑一定是一個中間節點(檔案夾或符号連結),既然是中間節點,那麼就需要“走過”這個節點。咱們來看看 walk_component 是怎麼“走過”中間節點的。在此之前先小小劇透一下,當 walk_component 傳回時,如果目前子路徑是一個真正的目錄的話,那麼 nd 已經“站在”目前節點上并等着下一次循環再往前“站”一步。但如果目前子路徑隻是一個符号連結呢?這時 nd 會原地不動,告訴你個小秘密:nd 是很有脾氣的,如果不是真正的目錄絕不會站上去;而 next 就随和得多,它會自告奮勇不管是不是真正的目錄先站上去再說。接着 next 會和 nest_symlink 聯手幫助 nd 在下一個真正的目錄“上位”。
【fs/namei.c】sys_open->do_sys_open->do_filp_open->path_openat->link_path_walk->walk_component
static inline int walk_component(struct nameidata *nd, struct path *path,
int follow)
{
if (unlikely(nd->last_type != LAST_NORM))
return handle_dots(nd, nd->last_type);
對于這個子路徑可以分成三種情況,第一,它可能是“.”或“..”;第二,這就是一個普通的目錄;第三,它是一個符号連結。我們先來看第一種可能,對于“.”或“..”,是在 handle_dots 單獨處理的。
【fs/namei.c】sys_open->do_sys_open->do_filp_open->path_openat->link_path_walk->walk_component->handle_dots
static inline int handle_dots(struct nameidata *nd, int type)
if (type == LAST_DOTDOT) {
if (nd->flags & LOOKUP_RCU) {
if (follow_dotdot_rcu(nd))
return -ECHILD;
} else
follow_dotdot(nd);
}
return 0;
}
這裡隻是針對“..”做處理(1489);如果是“.”的話那就就代表的是目前路徑,直接傳回就好了。前面說過
do_filp_open 會首先使用 RCU 政策進行操作,如果不行再用普通政策。這裡就可以看出隻有 RCU 失敗才會傳回 -ECHILD
以啟動普通政策。但是大家有沒有發現,這裡并沒有對 follow_dotdot(_rcu)
的傳回值進行檢查,為什麼?這是因為“..”出現在路徑裡就表示要向“上”走一層,也就是要走到父目錄裡面去,而父目錄一定是存在記憶體中而且對于目前的程序來說一定也是合法的,否則在讀取父目錄的時候就已經出錯了。接着我們就來“跟随 ..”。
【fs/namei.c】sys_open > do_sys_open > do_filp_open > path_openat > link_path_walk > walk_component > handle_dots > follow_dotdot_rcu
static int follow_dotdot_rcu(struct nameidata *nd)
set_root_rcu(nd);
首先設定 nd 的根目錄(nd.root),還記得我們在哪裡設定過這個成員麼?沒錯,在 path_init 裡,如果是絕對路徑的話就會把這個 nd.root 設定成目前程序的根目錄(其實還可以在 do_file_open_root 裡預設這個值,是以為了和系統根目錄區分,我們稱 nd.root 為預設根目錄),但如果是相對路徑的話,就沒有對 nd.root 進行初始化。為啥要分兩步走呢?還是因為效率問題,任何一個目錄都是一種資源,根目錄也不例外,要擷取某種資源必定會有一定的系統開銷(在這裡就是順序鎖),況且很有可能辛辛苦苦獲得了這個根目錄資源卻根本就用不上,造成無端的浪費,是以 Kernel 本着能不用就不用的原則不到萬不得已絕不輕易占用系統資源。現在的情況是路徑中出現了“..”,就說明需要向上走一層,也就有可能會通路根目錄,是以現在正是擷取根目錄的時候。拿到根目錄後就進入一個小小的循環,有人問了:不就是往上走一層麼,為啥是個循環呢?請往下看:
while (1) {
if (nd->path.dentry == nd->root.dentry &&
nd->path.mnt == nd->root.mnt) {
break;
if (nd->path.dentry != nd->path.mnt->mnt_root) {
struct dentry *old = nd->path.dentry;
struct dentry *parent = old->d_parent;
unsigned seq;
seq = read_seqcount_begin(&parent->d_seq);
if (read_seqcount_retry(&old->d_seq, nd->seq))
goto failed;
nd->path.dentry = parent;
nd->seq = seq;
if (!follow_up_rcu(&nd->path))
nd->seq = read_seqcount_begin(&nd->path.dentry->d_seq);
通過觀察這個循環體我們發現隻有 follow_up_rcu 傳回非 0 的時候才會進入循環,其餘幾種情況都會通過 break 直接跳出循環。那麼這幾種情況都是啥意思呢?我們一個一個來看:
首先,如果目前路徑就是預設根目錄的話(1141)就什麼也不做直接跳出循環(都已經到根目錄了不退出還等啥呢,大家可以在根目錄試試這個指令“cd ../../”,看看有什麼效果);其次,目前路徑不是預設根目錄,但也不是目前檔案系統的根目錄(1145),那麼向上走一層也是很簡單的事,直接将父目錄項拿過來就是了(1153);到最後,目前路徑一定是某個檔案系統的根目錄,往上走有可能就會走到另一個檔案系統裡去了。
看到這裡可能有人要問了,啥叫檔案系統的根目錄,檔案系統和檔案系統又有啥關系?别着急,我們祭出本次旅途的第二張導遊圖,再配合我的講解相信大家很快就會明白的。
【mount 結構圖】
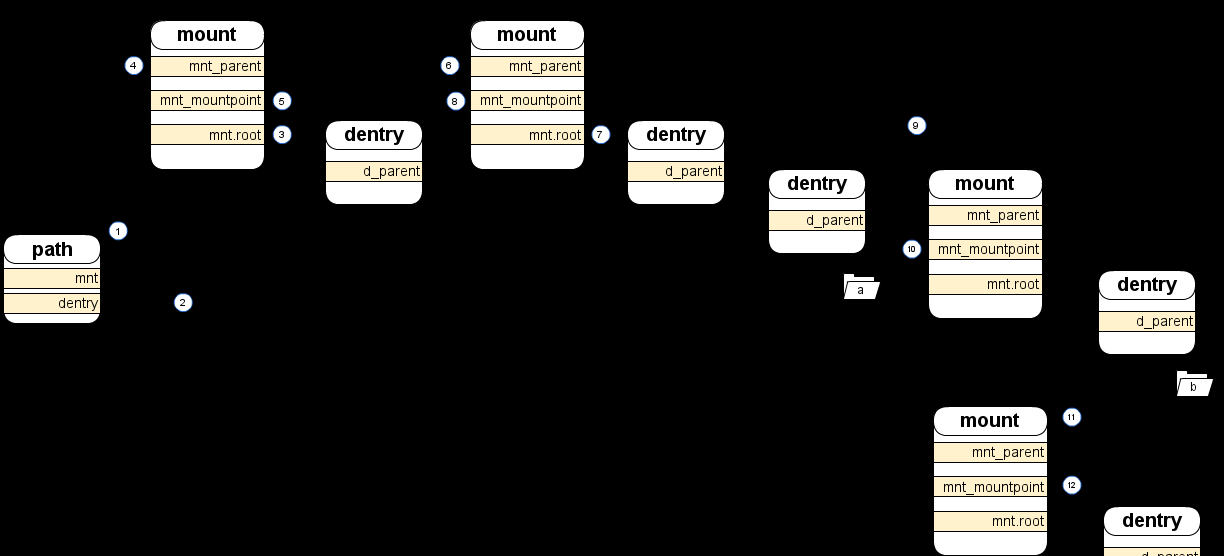
這是一個關于 mount(挂載)的故事。在 Kernel 世界裡,挂載是一項很了不起的特性,它可以将不同類型的檔案系統組合成一個有機的整體,從使用者角度來看不同的檔案系統并沒有什麼差別,那麼 Kernel 是怎麼做到呢?首先,Kernel 會為每個檔案系統準備一個 mount 結構,然後再把這個結構加入到 vfs 這顆大樹上就好了。這麼一個小小的 mount 結構就這麼神奇?請看圖,一個 mount 中有三個很重要的成員,他們分别指向父 mount 結構(6)、本檔案系統自己的根目錄(7)和本檔案系統的挂載點(8),前兩個很好了解,那麼挂載點是什麼呢?簡單地說挂載點就是父級檔案系統的某個目錄,一旦将某個檔案系統挂載到某個目錄上,這個目錄就成了該檔案系統的根目錄了。并且該目錄的标志位 DCACHE_MOUNTED 将被置位,這将表明這個目錄已經是一個挂載點了,如果要通路這個目錄的話就要順着 mount 結構通路另一個檔案系統了,原來的内容将變得不可通路。
現在我們從圖的左邊講起,帶你一窺 mount 的風采。一個程序有一個叫 root 的 path 結構,它就是本程序的根目錄(大多數情況下它就是系統根目錄),root 中兩個成員分别指向某個檔案系統的 mount 結構(其實是指向 mount.mnt 但這樣了解沒問題)(1)和該檔案系統的根目錄(2),這個檔案系統就是所謂根檔案系統(在圖中就是 rootfs)。由于它是根檔案系統,是以它的父 mount 結構就是它自己(4)它的挂載點就是它自己的根目錄(5)。但是 rootfs 隻是一個臨時的根檔案系統,在 Kernel 的啟動過程中加載完 rootfs 之後會緊接着解壓縮 initramfs 到 rootfs 中,這裡面包括了驅動以及加載真正的根檔案系統的工具,Kernel 通過加載這些驅動、使用這些工具實作了挂載真正的根檔案系統。之後 rootfs 将推出曆史舞台,但作為檔案系統的總根 rootfs 并不會被解除安裝(注)。圖中 fs1 就是所謂的真正的根檔案系統,Kernel 把它挂載到了 rootfs 的根目錄上(8),并且将它的父 mount 結構指向了 rootfs(6)。這時通路根目錄的話就會直接通路到 fs1 的根目錄,而 rootfs 就好像不存在了一樣。
再看 fs1,他有一個子目錄“mnt/”,以及“mnt/”的子目錄“a”,此時路徑“/mnt/a/”是可通路的。但現在我們還有另一個檔案系統 fs2,我們把它挂載到“/mnt/”上會發生什麼呢?首先 fs2 的父 mount 将指向 fs1(9),然後 fs2 的挂載點将指向 “/mnt/”(10),同時“mnt/”的 DCACHE_MOUNTED 将被置位。此時路徑“/mnt/a/”就不可通路了,取而代之的是“/mnt/b/”。本着不怕麻煩的精神我們再折騰一下,把 fs3 也挂載到“/mnt/”上,這時和挂載 fs2 一樣父 mount 将指向 fs2(11),但是挂載點應該指向哪裡呢?答案是 fs2 的根目錄(12)。這時“/mnt/b/”也消失了,我們隻能看見“/mnt/c”了。這樣整個結構就形成了一個挂載的序列,最後挂載的在序列末尾,Kernel 可以很容易的通過這個序列找到最初的挂載點和最終的檔案系統。
在順序查找的情景下,當遇到一個目錄時 Kernel 會判斷這個目錄是不是挂載點(檢查 DCACHE_MOUNTED 标志位),如果是就要找到挂載到這個目錄的檔案系統,繼而找到該檔案系統的根目錄,然後在判斷這個根目錄是不是挂載點,如果是那就再往下找直到某個檔案系統的根目錄不再是挂載點。
反向查找也和順序查找類似,我們結合代碼來看:
【fs/namei.c】sys_open > do_sys_open > do_filp_open > path_openat > link_path_walk > walk_component > handle_dots > follow_dotdot_rcu > follow_up_rcu
static int follow_up_rcu(struct path *path)
struct mount *mnt = real_mount(path->mnt);
struct mount *parent;
struct dentry *mountpoint;
parent = mnt->mnt_parent;
if (&parent->mnt == path->mnt)
return 0;
mountpoint = mnt->mnt_mountpoint;
path->dentry = mountpoint;
path->mnt = &parent->mnt;
return 1;
首先檢查目前的檔案系統是不是根檔案系統(891),如果是就直接傳回 0 并結束循環。如果不是的話就要像上走一層走到父 mount 代表的檔案系統中去,這個向上走的過程也很簡單,直接取得挂載點就可以了(894)當然 mount 也需要跟新一下(895)。但僅僅這樣做是不夠的,因為很有可能現在的這個目錄也是該檔案系統的根目錄,這就需要傳回 1,啟動循環再來一次。
當跳出這個 while(1) 循環時我們已經站在某個目錄上了,一般來說這個目錄就是我們想要的目标,而不會是一個挂載點,但也有例外。請看 while(1) 循環中第一個 if 和 follow_up_rcu 中的那個 if,想必大家已經發現了,當遇到(預設)根目錄的時候會直接退出循環,而這時我們的位置就相當于站在圖中 rootfs 的根目錄上,這顯然不是我們想要的,我們想要站在 fs1 的根目錄上。這就需要接下來的循環,再順着 mount 結構往下走。
while (d_mountpoint(nd->path.dentry)) {
struct mount *mounted;
mounted = __lookup_mnt(nd->path.mnt, nd->path.dentry);
if (!mounted)
nd->path.mnt = &mounted->mnt;
nd->path.dentry = mounted->mnt.mnt_root;
if (!read_seqretry(&mount_lock, nd->m_seq))
goto failed;
nd->inode = nd->path.dentry->d_inode;
d_mountpoint() 就是檢查标志位 DCACHE_MOUNTED(1161),然後在某個散清單中查找屬于這個挂載點的 mount 結構,如果找到了(如果某個目錄既是挂載點但又沒有任何檔案系統挂載在上面那就說明這個目錄可能擁有自動挂載的屬性),就往下走一層,走到挂載檔案系統的根目錄上(1167),然後再回到 1161 行再判斷、查找、向下走,周而複始直到某個非挂載點。
從 follow_dotdot_rcu 傳回後,對“.”和“..”的處理也完成了,程式将直接傳回 link_path_walk 進入對下一個子路徑的處理。
休息一下,我們馬上回來。
注:摘自《深度探索 Linux 作業系統》王柏生
![linux-svn解除安裝與安裝[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)