一,使用數組存儲
二,緩存行優勢&僞共享
三,記憶體屏障
參考文章:https://ifeve.com/dissecting-disruptor-whats-so-special/
之是以ringbuffer采用這種資料結構,是因為它在可靠消息傳遞方面有很好的性能。這就夠了,不過它還有一些其他的優點。
首先,因為它是數組,是以要比連結清單快,而且有一個容易預測的通路模式。(譯者注:數組内元素的記憶體位址的連續性存儲的)。這是對CPU緩存友好的—也就是說,在硬體級别,數組中的元素是會被預加載的,是以在ringbuffer當中,cpu無需時不時去主存加載數組中的下一個元素。(校對注:因為隻要一個元素被加載到緩存行,其他相鄰的幾個元素也會被加載進同一個緩存行)
其次,你可以為數組預先配置設定記憶體,使得數組對象一直存在(除非程式終止)。這就意味着不需要花大量的時間用于垃圾回收。此外,不像連結清單那樣,需要為每一個添加到其上面的對象創造節點對象—對應的,當删除節點時,需要執行相應的記憶體清理操作。
在本文中并沒有介紹如何避免ringbuffer産生重疊,以及如何對ringbuffer進行讀寫操作。你可能注意到了我将ringbuffer和連結清單那樣的資料結構進行比較,因為我并不認為連結清單是實際問題的标準答案。
當你将Disruptor和基于 隊列之類的實作進行比較時,事情将變得很有趣。隊列通常注重維護隊列的頭尾元素,添加和删除元素等。所有的這些我都沒有在ringbuffer裡提到,這是因為ringbuffer不負責這些事情,我們把這些操作都移到了資料結構(ringbuffer)的外部。
計算機基礎
CPU是你機器的心髒,最終由它來執行所有運算和程式。主記憶體(RAM)是你的資料(包括代碼行)存放的地方。本文将忽略硬體驅動和網絡之類的東西,因為Disruptor的目标是盡可能多的在記憶體中運作。
CPU和主記憶體之間有好幾層緩存,因為即使直接通路主記憶體也是非常慢的。如果你正在多次對一塊資料做相同的運算,那麼在執行運算的時候把它加載到離CPU很近的地方就有意義了(比如一個循環計數-你不想每次循環都跑到主記憶體去取這個資料來增長它吧)。
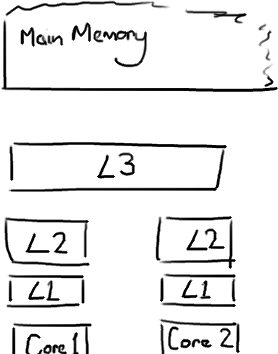
越靠近CPU的緩存越快也越小。是以L1緩存很小但很快(譯注:L1表示一級緩存),并且緊靠着在使用它的CPU核心。L2大一些,也慢一些,并且仍然隻能被一個單獨的 CPU 核使用。L3在現代多核機器中更普遍,仍然更大,更慢,并且被單個插槽上的所有 CPU 核共享。最後,你擁有一塊主存,由全部插槽上的所有 CPU 核共享。
當CPU執行運算的時候,它先去L1查找所需的資料,再去L2,然後是L3,最後如果這些緩存中都沒有,所需的資料就要去主記憶體拿。走得越遠,運算耗費的時間就越長。是以如果你在做一些很頻繁的事,你要確定資料在L1緩存中。
Martin和Mike的 QCon presentation演講中給出了一些緩存未命中的消耗資料:
從CPU到
大約需要的 CPU 周期
大約需要的時間
主存
約60-80納秒
QPI 總線傳輸
(between sockets, not drawn)
約20ns
L3 cache
約40-45 cycles,
約15ns
L2 cache
約10 cycles,
約3ns
L1 cache
約3-4 cycles,
約1ns
寄存器
1 cycle
如果你的目标是讓端到端的延遲隻有 10毫秒,而其中花80納秒去主存拿一些未命中資料的過程将占很重的一塊。
緩存行
現在需要注意一件有趣的事情,資料在緩存中不是以獨立的項來存儲的,如不是一個單獨的變量,也不是一個單獨的指針。緩存是由緩存行組成的,通常是64位元組(譯注:這篇文章發表時常用處理器的緩存行是64位元組的,比較舊的處理器緩存行是32位元組),并且它有效地引用主記憶體中的一塊位址。一個Java的long類型是8位元組,是以在一個緩存行中可以存8個long類型的變量。

(為了簡化,我将忽略多級緩存)
非常奇妙的是如果你通路一個long數組,當數組中的一個值被加載到緩存中,它會額外加載另外7個。是以你能非常快地周遊這個數組。事實上,你可以非常快速的周遊在連續的記憶體塊中配置設定的任意資料結構。我在第一篇關于ring buffer的文章中順便提到過這個,它解釋了我們的ring buffer使用數組的原因。
是以如果你資料結構中的項在記憶體中不是彼此相鄰的(連結清單,我正在關注你呢),你将得不到免費緩存加載所帶來的優勢。并且在這些資料結構中的每一個項都可能會出現緩存未命中。
不過,所有這種免費加載有一個弊端。設想你的long類型的資料不是數組的一部分。設想它隻是一個單獨的變量。讓我們稱它為<code>head</code>,這麼稱呼它其實沒有什麼原因。然後再設想在你的類中有另一個變量緊挨着它。讓我們直接稱它為<code>tail</code>。現在,當你加載<code>head</code>到緩存的時候,你也免費加載了<code>tail</code>。
聽想來不錯。直到你意識到<code>tail</code>正在被你的生産者寫入,而<code>head</code>正在被你的消費者寫入。這兩個變量實際上并不是密切相關的,而事實上卻要被兩個不同核心中運作的線程所使用。
設想你的消費者更新了<code>head</code>的值。緩存中的值和記憶體中的值都被更新了,而其他所有存儲<code>head</code>的緩存行都會都會失效,因為其它緩存中<code>head</code>不是最新值了。請記住我們必須以整個緩存行作為機關來處理(譯注:這是CPU的實作所規定的,詳細可參見深入分析Volatile的實作原理),不能隻把<code>head</code>标記為無效。
現在如果一些正在其他核心中運作的程序隻是想讀<code>tail</code>的值,整個緩存行需要從主記憶體重新讀取。那麼一個和你的消費者無關的線程讀一個和<code>head</code>無關的值,它被緩存未命中給拖慢了。
當然如果兩個獨立的線程同時寫兩個不同的值會更糟。因為每次線程對緩存行進行寫操作時,每個核心都要把另一個核心上的緩存塊無效掉并重新讀取裡面的資料。你基本上是遇到兩個線程之間的寫沖突了,盡管它們寫入的是不同的變量。
這叫作“僞共享”(譯注:可以了解為錯誤的共享),因為每次你通路<code>head</code>你也會得到<code>tail</code>,而且每次你通路<code>tail</code>,你也會得到<code>head</code>。這一切都在背景發生,并且沒有任何編譯警告會告訴你,你正在寫一個并發通路效率很低的代碼。
解決方案-神奇的緩存行填充
你會看到Disruptor消除這個問題,至少對于緩存行大小是64位元組或更少的處理器架構來說是這樣的(譯注:有可能處理器的緩存行是128位元組,那麼使用64位元組填充還是會存在僞共享問題),通過增加補全來確定ring buffer的序列号不會和其他東西同時存在于一個緩存行中。
<code>1</code>
<code>public</code> <code>long</code> <code>p1, p2, p3, p4, p5, p6, p7; </code><code>// cache line padding</code>
<code>2</code>
<code> </code><code>private</code> <code>volatile</code> <code>long</code> <code>cursor = INITIAL_CURSOR_VALUE;</code>
<code>3</code>
<code> </code><code>public</code> <code>long</code> <code>p8, p9, p10, p11, p12, p13, p14; </code><code>// cache line padding</code>
是以沒有僞共享,就沒有和其它任何變量的意外沖突,沒有不必要的緩存未命中。
在你的<code>Entry</code>類中也值得這樣做,如果你有不同的消費者往不同的字段寫入,你需要確定各個字段間不會出現僞共享。
修改:Martin寫了一個從技術上來說更準确更詳細的關于僞共享的文章,并且釋出了性能測試結果。
什麼是記憶體屏障?
它是一個CPU指令。沒錯,又一次,我們在讨論CPU級别的東西,以便獲得我們想要的性能(Martin著名的Mechanical Sympathy理論)。基本上,它是這樣一條指令: a)確定一些特定操作執行的順序; b)影響一些資料的可見性(可能是某些指令執行後的結果)。
編譯器和CPU可以在保證輸出結果一樣的情況下對指令重排序,使性能得到優化。插入一個記憶體屏障,相當于告訴CPU和編譯器先于這個指令的必須先執行,後于這個指令的必須後執行。正如去拉斯維加斯旅途中各個站點的先後順序在你心中都一清二楚。
記憶體屏障另一個作用是強制更新一次不同CPU的緩存。例如,一個寫屏障會把這個屏障前寫入的資料重新整理到緩存,這樣任何試圖讀取該資料的線程将得到最新值,而不用考慮到底是被哪個cpu核心或者哪顆CPU執行的。
和Java有什麼關系?
現在我知道你在想什麼——這不是彙程式設計式。它是Java。
這裡有個神奇咒語叫volatile(我覺得這個詞在Java規範中從未被解釋清楚)。如果你的字段是volatile,Java記憶體模型将在寫操作後插入一個寫屏障指令,在讀操作前插入一個讀屏障指令。
這意味着如果你對一個volatile字段進行寫操作,你必須知道:
1、一旦你完成寫入,任何通路這個字段的線程将會得到最新的值。
2、在你寫入前,會保證所有之前發生的事已經發生,并且任何更新過的資料值也是可見的,因為記憶體屏障會把之前的寫入值都重新整理到緩存。
舉個例子呗!
很高興你這樣說了。又是時候讓我來畫幾個甜甜圈了。
RingBuffer的指針(cursor)(譯注:指向隊尾元素)屬于一個神奇的volatile變量,同時也是我們能夠不用鎖操作就能實作Disruptor的原因之一。
生産者将會取得下一個Entry(或者是一批),并可對它(們)作任意改動, 把它(們)更新為任何想要的值。如你所知,在所有改動都完成後,生産者對ring buffer調用commit方法來更新序列号(譯注:把cursor更新為該Entry的序列号)。對volatile字段(cursor)的寫操作建立了一個記憶體屏障,這個屏障将重新整理所有緩存裡的值(或者至少相應地使得緩存失效)。
這時候,消費者們能獲得最新的序列号碼(8),并且因為記憶體屏障保證了它之前執行的指令的順序,消費者們可以确信生産者對7号Entry所作的改動已經可用。
…那麼消費者那邊會發生什麼?
消費者中的序列号是volatile類型的,會被若幹個外部對象讀取——其他的下遊消費者可能在跟蹤這個消費者。ProducerBarrier/RingBuffer(取決于你看的是舊的還是新的代碼)跟蹤它以確定環沒有出現重疊(wrap)的情況(譯注:為了防止下遊的消費者和上遊的消費者對同一個Entry競争消費,導緻在環形隊列中互相覆寫資料,下遊消費者要對上遊消費者的消費情況進行跟蹤)。
是以,如果你的下遊消費者(C2)看見前一個消費者(C1)在消費号碼為12的Entry,當C2的讀取也到了12,它在更新序列号前将可以獲得C1對該Entry的所作的更新。
基本來說就是,C1更新序列号前對ring buffer的所有操作(如上圖黑色所示),必須先發生,待C2拿到C1更新過的序列号之後,C2才可以為所欲為(如上圖藍色所示)。
對性能的影響
記憶體屏障作為另一個CPU級的指令,沒有鎖那樣大的開銷。核心并沒有在多個線程間幹涉和排程。但凡事都是有代價的。記憶體屏障的确是有開銷的——編譯器/cpu不能重排序指令,導緻不可以盡可能地高效利用CPU,另外重新整理緩存亦會有開銷。是以不要以為用volatile代替鎖操作就一點事都沒。
你會注意到Disruptor的實作對序列号的讀寫頻率盡量降到最低。對volatile字段的每次讀或寫都是相對高成本的操作。但是,也應該認識到在批量的情況下可以獲得很好的表現。如果你知道不應對序列号頻繁讀寫,那麼很合理的想到,先獲得一整批Entries,并在更新序列号前處理它們。這個技巧對生産者和消費者都适用。以下的例子來自BatchConsumer:
<code>01</code>
<code> </code><code>long</code> <code>nextSequence = sequence + </code><code>1</code><code>;</code>
<code>02</code>
<code> </code><code>while</code> <code>(running)</code>
<code>03</code>
<code> </code><code>{</code>
<code>04</code>
<code> </code><code>try</code>
<code>05</code>
<code> </code><code>{</code>
<code>06</code>
<code> </code><code>final</code> <code>long</code> <code>availableSequence = consumerBarrier.waitFor(nextSequence);</code>
<code>07</code>
<code> </code><code>while</code> <code>(nextSequence <= availableSequence)</code>
<code>08</code>
<code> </code><code>{</code>
<code>09</code>
<code> </code><code>entry = consumerBarrier.getEntry(nextSequence);</code>
<code>10</code>
<code> </code><code>handler.onAvailable(entry);</code>
<code>11</code>
<code> </code><code>nextSequence++;</code>
<code>12</code>
<code> </code><code>}</code>
<code>13</code>
<code> </code><code>handler.onEndOfBatch();</code>
<code>14</code>
<code> </code><code>sequence = entry.getSequence();</code>
<code>15</code>
<code> </code><code>}</code>
<code>16</code>
<code> </code><code>…</code>
<code>17</code>
<code> </code><code>catch</code> <code>(</code><code>final</code> <code>Exception ex)</code>
<code>18</code>
<code>19</code>
<code> </code><code>exceptionHandler.handle(ex, entry);</code>
<code>20</code>
<code>21</code>
<code> </code><code>nextSequence = entry.getSequence() + </code><code>1</code><code>;</code>
<code>22</code>
<code>23</code>
<code> </code><code>}</code>
(你會注意到,這是個舊式的代碼和命名習慣,因為這是摘自我以前的部落格文章,我認為如果直接轉換為新式的代碼和命名習慣會讓人有點混亂)
在上面的代碼中,我們在消費者處理entries的循環中用一個局部變量(nextSequence)來遞增。這表明我們想盡可能地減少對volatile類型的序列号的進行讀寫。
總結
記憶體屏障是CPU指令,它允許你對資料什麼時候對其他程序可見作出假設。在Java裡,你使用volatile關鍵字來實作記憶體屏障。使用volatile意味着你不用被迫選擇加鎖,并且還能讓你獲得性能的提升。
但是,你需要對你的設計進行一些更細緻的思考,特别是你對volatile字段的使用有多頻繁,以及對它們的讀寫有多頻繁。