Redis 作為一種 KV 緩存伺服器,有着極高的性能,相對于 Memcache,Redis 支援更多種資料類型,是以在業界應用廣泛。
記得剛畢業那會參加面試,面試官會問我 Redis 為什麼快,由于當時技術水準有限,我隻能回答出如下兩點:
資料是存儲在記憶體中的。
Redis 是單線程的。
當然,将資料存儲在記憶體中,讀取的時候不需要進行磁盤的 IO,單線程也保證了系統沒有線程的上下文切換。
但這兩點隻是 Redis 高性能原因的很小一部分,下面從資料存儲層面上為大家分析 Redis 性能為何如此高。
Redis性能如此高的原因,我總結了如下幾點:
純記憶體操作
單線程
高效的資料結構
合理的資料編碼
其他方面的優化
在 Redis 中,常用的 5 種資料結構和應用場景如下:
String:緩存、計數器、分布式鎖等。
List:連結清單、隊列、微網誌關注人時間軸清單等。
Hash:使用者資訊、Hash 表等。
Set:去重、贊、踩、共同好友等。
Zset:通路量排行榜、點選量排行榜等。
Redis 是用 C 語言開發完成的,但在 Redis 字元串中,并沒有使用 C 語言中的字元串,而是用一種稱為 SDS(Simple Dynamic String)的結構體來儲存字元串。
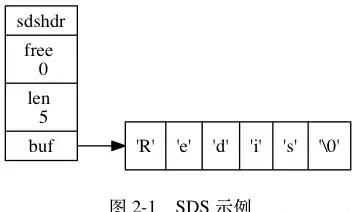
SDS 的結構如上圖:
len:用于記錄 buf 中已使用空間的長度。
free:buf 中空閑空間的長度。
buf[]:存儲實際内容。
例如:執行指令 set key value,key 和 value 都是一個 SDS 類型的結構存儲在記憶體中。
SDS 與 C 字元串的差別
①常數時間内獲得字元串長度
C 字元串本身不記錄長度資訊,每次擷取長度資訊都需要周遊整個字元串,複雜度為 O(n);C 字元串周遊時遇到 '\0' 時結束。
SDS 中 len 字段儲存着字元串的長度,是以總能在常數時間内擷取字元串長度,複雜度是 O(1)。
②避免緩沖區溢出
假設在記憶體中有兩個緊挨着的兩個字元串,s1=“xxxxx”和 s2=“yyyyy”。
由于在記憶體上緊緊相連,當我們對 s1 進行擴充的時候,将 s1=“xxxxxzzzzz”後,由于沒有進行相應的記憶體重新配置設定,導緻 s1 把 s2 覆寫掉,導緻 s2 被莫名其妙的修改。
但 SDS 的 API 對 zfc 修改時首先會檢查空間是否足夠,若不充足則會配置設定新空間,避免了緩沖區溢出問題。
③減少字元串修改時帶來的記憶體重新配置設定的次數
在 C 中,當我們頻繁的對一個字元串進行修改(append 或 trim)操作的時候,需要頻繁的進行記憶體重新配置設定的操作,十分影響性能。
如果不小心忘記,有可能會導緻記憶體溢出或記憶體洩漏,對于 Redis 來說,本身就會很頻繁的修改字元串,是以使用 C 字元串并不合适。而 SDS 實作了空間預配置設定和惰性空間釋放兩種優化政策:
空間預配置設定:當 SDS 的 API 對一個 SDS 修改後,并且對 SDS 空間擴充時,程式不僅會為 SDS 配置設定所需要的必須空間,還會配置設定額外的未使用空間。
配置設定規則如下:如果對 SDS 修改後,len 的長度小于 1M,那麼程式将配置設定和 len 相同長度的未使用空間。舉個例子,如果 len=10,重新配置設定後,buf 的實際長度會變為 10(已使用空間)+10(額外空間)+1(空字元)=21。如果對 SDS 修改後 len 長度大于 1M,那麼程式将配置設定 1M 的未使用空間。
惰性空間釋放:當對 SDS 進行縮短操作時,程式并不會回收多餘的記憶體空間,而是使用 free 字段将這些位元組數量記錄下來不釋放,後面如果需要 append 操作,則直接使用 free 中未使用的空間,減少了記憶體的配置設定。
④二進制安全
在 Redis 中不僅可以存儲 String 類型的資料,也可能存儲一些二進制資料。
二進制資料并不是規則的字元串格式,其中會包含一些特殊的字元如 '\0',在 C 中遇到 '\0' 則表示字元串的結束,但在 SDS 中,标志字元串結束的是 len 屬性。
與 Java 中的 HashMap 類似,Redis 中的 Hash 比 Java 中的更進階一些。
Redis 本身就是 KV 伺服器,除了 Redis 本身資料庫之外,字典也是哈希鍵的底層實作。
字典的資料結構如下所示:
重要的兩個字段是 dictht 和 trehashidx,這兩個字段與 rehash 有關,下面重點介紹 rehash。
Rehash
學過 Java 的朋友都應該知道 HashMap 是如何 rehash 的,在此處我就不過多贅述,下面介紹 Redis 中 Rehash 的過程。
由上段代碼,我們可知 dict 中存儲了一個 dictht 的數組,長度為 2,表明這個資料結構中實際存儲着兩個哈希表 ht[0] 和 ht[1],為什麼要存儲兩張 hash 表呢?
當然是為了 Rehash,Rehash 的過程如下:
為 ht[1] 配置設定空間。如果是擴容操作,ht[1] 的大小為第一個大于等于 ht[0].used*2 的 2^n;如果是縮容操作,ht[1] 的大小為第一個大于等于 ht[0].used 的 2^n。
将 ht[0] 中的鍵值 Rehash 到 ht[1] 中。
當 ht[0] 全部遷移到 ht[1] 中後,釋放 ht[0],将 ht[1] 置為 ht[0],并為 ht[1] 建立一張新表,為下次 Rehash 做準備。
漸進式 Rehash
由于 Redis 的 Rehash 操作是将 ht[0] 中的鍵值全部遷移到 ht[1],如果資料量小,則遷移過程很快。但如果資料量很大,一個 Hash 表中存儲了幾萬甚至幾百萬幾千萬的鍵值時,遷移過程很慢并會影響到其他使用者的使用。
為了避免 Rehash 對伺服器性能造成影響,Redis 采用了一種漸進式 Rehash 的政策,分多次、漸進的将 ht[0] 中的資料遷移到 ht[1] 中。
前一過程如下:
為 ht[1] 配置設定空間,讓字典同時擁有 ht[0] 和 ht[1] 兩個哈希表。
字典中維護一個 rehashidx,并将它置為 0,表示 Rehash 開始。
在 Rehash 期間,每次對字典操作時,程式還順便将 ht[0] 在 rehashidx 索引上的所有鍵值對 rehash 到 ht[1] 中,當 Rehash 完成後,将 rehashidx 屬性+1。當全部 rehash 完成後,将 rehashidx 置為 -1,表示 rehash 完成。
注意,由于維護了兩張 Hash 表,是以在 Rehash 的過程中記憶體會增長。另外,在 Rehash 過程中,字典會同時使用 ht[0] 和 ht[1]。
是以在删除、查找、更新時會在兩張表中操作,在查詢時會現在第一張表中查詢,如果第一張表中沒有,則會在第二張表中查詢。但新增時一律會在 ht[1] 中進行,確定 ht[0] 中的資料隻會減少不會增加。
Zset 是一個有序的連結清單結構,其底層的資料結構是跳躍表 skiplist,其結構如下:

前進指針:用于從表頭向表尾方向周遊。
後退指針:用于從表尾向表頭方向回退一個節點,和前進指針不同的是,前進指針可以一次性跳躍多個節點,後退指針每次隻能後退到上一個節點。
跨度:表示目前節點和下一個節點的距離,跨度越大,兩個節點中間相隔的元素越多。
在查詢過程中跳躍着前進。由于存在後退指針,如果查詢時超出了範圍,通過後退指針回退到上一個節點後仍可以繼續向前周遊。
壓縮清單 ziplist 是為 Redis 節約記憶體而開發的,是清單鍵和字典鍵的底層實作之一。
當元素個數較少時,Redis 用 ziplist 來存儲資料,當元素個數超過某個值時,連結清單鍵中會把 ziplist 轉化為 linkedlist,字典鍵中會把 ziplist 轉化為 hashtable。
ziplist 是由一系列特殊編碼的連續記憶體塊組成的順序型的資料結構,ziplist 中可以包含多個 entry 節點,每個節點可以存放整數或者字元串。
由于記憶體是連續配置設定的,是以周遊速度很快。
Redis 使用對象(redisObject)來表示資料庫中的鍵值,當我們在 Redis 中建立一個鍵值對時,至少建立兩個對象,一個對象是用做鍵值對的鍵對象,另一個是鍵值對的值對象。
例如我們執行 SET MSG XXX 時,鍵值對的鍵是一個包含了字元串“MSG“的對象,鍵值對的值對象是包含字元串"XXX"的對象。
redisObject 的結構如下:
其中 type 字段記錄了對象的類型,包含字元串對象、清單對象、哈希對象、集合對象、有序集合對象。
當我們執行 type key 指令時傳回的結果如下:
ptr 指針字段指向對象底層實作的資料結構,而這些資料結構是由 encoding 字段決定的,每種對象至少有兩種資料編碼:
可以通過 object encoding key 來檢視對象所使用的編碼:
細心的讀者可能注意到,list、hash、zset 三個鍵使用的是 ziplist 壓縮清單編碼,這就涉及到了 Redis 底層的編碼轉換。
上面介紹到,ziplist 是一種結構緊湊的資料結構,當某一鍵值中所包含的元素較少時,會優先存儲在 ziplist 中,當元素個數超過某一值後,才将 ziplist 轉化為标準存儲結構,而這一值是可配置的。
String 對象的編碼可以是 int 或 raw,對于 String 類型的鍵值,如果我們存儲的是純數字,Redis 底層采用的是 int 類型的編碼,如果其中包括非數字,則會立即轉為 raw 編碼:
List 對象的編碼可以是 ziplist 或 linkedlist,對于 List 類型的鍵值,當清單對象同時滿足以下兩個條件時,采用 ziplist 編碼:
清單對象儲存的所有字元串元素的長度都小于 64 位元組。
清單對象儲存的元素個數小于 512 個。
如果不滿足這兩個條件的任意一個,就會轉化為 linkedlist 編碼。注意:這兩個條件是可以修改的,在 redis.conf 中:
Set 對象的編碼可以是 intset 或 hashtable,intset 編碼的結婚對象使用整數集合作為底層實作,把所有元素都儲存在一個整數集合裡面。
如果 set 集合中儲存了非整數類型的資料時,Redis 會将 intset 轉化為 hashtable:
當 Set 對象同時滿足以下兩個條件時,對象采用 intset 編碼:
儲存的所有元素都是整數值(小數不行)。
Set 對象儲存的所有元素個數小于 512 個。
不能滿足這兩個條件的任意一個,Set 都會采用 hashtable 存儲。注意:第兩個條件是可以修改的,在 redis.conf 中:
Hash 對象的編碼可以是 ziplist 或 hashtable,當 Hash 以 ziplist 編碼存儲的時候,儲存同一鍵值對的兩個節點總是緊挨在一起,鍵節點在前,值節點在後:
當 Hash 對象同時滿足以下兩個條件時,Hash 對象采用 ziplist 編碼:
Hash 對象儲存的所有鍵值對的鍵和值的字元串長度均小于 64 位元組。
Hash 對象儲存的鍵值對數量小于 512 個。
如果不滿足以上條件的任意一個,ziplist 就會轉化為 hashtable 編碼。注意:這兩個條件是可以修改的,在 redis.conf 中:
Zset 對象的編碼可以是 ziplist 或 zkiplist,當采用 ziplist 編碼存儲時,每個集合元素使用兩個緊挨在一起的壓縮清單來存儲。
第一個節點存儲元素的成員,第二個節點存儲元素的分值,并且按分值大小從小到大有序排列。
當 Zset 對象同時滿足一下兩個條件時,采用 ziplist 編碼:
Zset 儲存的元素個數小于 128。
Zset 元素的成員長度都小于 64 位元組。
如果不滿足以上條件的任意一個,ziplist 就會轉化為 zkiplist 編碼。注意:這兩個條件是可以修改的,在 redis.conf 中:
思考:Zset 如何做到 O(1) 複雜度内元素并且快速進行範圍操作?Zset 采用 skiplist 編碼時使用 zset 結構作為底層實作,該資料結構同時包含了一個跳躍表和一個字典。
其結構如下:
Zset 中的 dict 字典為集合建立了一個從成員到分值之間的映射,字典中的鍵儲存了成員,字典中的值儲存了成員的分值,這樣定位元素時時間複雜度是 O(1)。
Zset 中的 zsl 跳躍表适合範圍操作,比如 ZRANK、ZRANGE 等,程式使用 zkiplist。
另外,雖然 Zset 中使用了 dict 和 skiplist 存儲資料,但這兩種資料結構都會通過指針來共享相同的記憶體,是以沒有必要擔心記憶體的浪費。
當我們對某些 key 設定了 expire 時,資料到了時間會自動删除。如果一個鍵過期了,它會在什麼時候删除呢?
下面介紹三種删除政策:
定時删除:在這是鍵的過期時間的同時,建立一個定時器 Timer,讓定時器在鍵過期時間來臨時立即執行對過期鍵的删除。
惰性删除:鍵過期後不管,每次讀取該鍵時,判斷該鍵是否過期,如果過期删除該鍵傳回空。
定期删除:每隔一段時間對資料庫中的過期鍵進行一次檢查。
定時删除:對記憶體友好,對 CPU 不友好。如果過期删除的鍵比較多的時候,删除鍵這一行為會占用相當一部分 CPU 性能,會對 Redis 的吞吐量造成一定影響。
惰性删除:對 CPU 友好,記憶體不友好。如果很多鍵過期了,但在将來很長一段時間内沒有很多用戶端通路該鍵導緻過期鍵不會被删除,占用大量記憶體空間。
定期删除:是定時删除和惰性删除的一種折中。每隔一段時間執行一次删除過期鍵的操作,并且限制删除操作執行的時長和頻率。
具體的操作如下:
Redis 會将每一個設定了 expire 的鍵存儲在一個獨立的字典中,以後會定時周遊這個字典來删除過期的 key。除了定時周遊外,它還會使用惰性删除政策來删除過期的 key。
Redis 預設每秒進行十次過期掃描,過期掃描不會掃描所有過期字典中的 key,而是采用了一種簡單的貪心政策。
從過期字典中随機選擇 20 個 key;删除這 20 個 key 中已過期的 key;如果過期 key 比例超過 1/4,那就重複步驟 1。
同時,為了保證在過期掃描期間不會出現過度循環,導緻線程卡死,算法還增加了掃描時間上限,預設不會超過 25ms。
總而言之,Redis 為了高性能,從各方各面都進行了優化,這裡的總結到這裡就結束了,想要了解更詳細内容請參閱之前文章。