<b>深度學習執行降維過程</b><b></b>
考慮到之前的章節,這不是一個令人吃驚的斷言。在之前的章節中,我們從幾個角度和層次讨論了人工智能是如何地高效工作。此外,也使用TensorFlow及相關API實作的例子示範了二者的性能。可以發現,TensorFlow及API的結合能夠在這個系統中實作很多的解決方案,且泛化足夠簡單。
下圖是使用Keras圖像了解示意圖
<b></b>
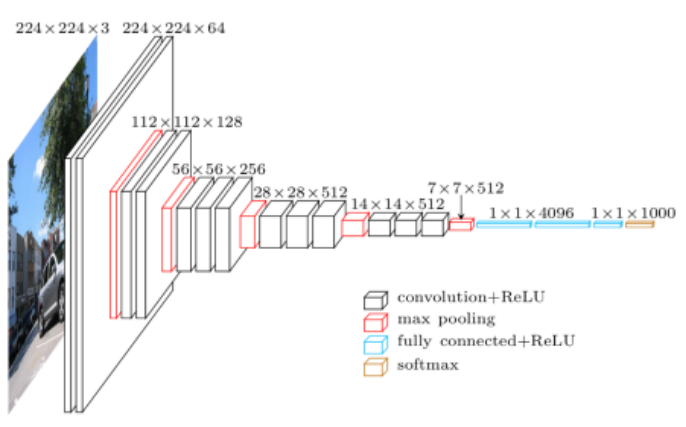
首先,将最左邊的輸入層稱作“底部”,将上圖旋轉九十度後可以發現,可以将其看作是一個從低到高的抽象層次堆棧,随着層數的增多,可以看到資料量和每層的複雜度明顯降低,我們能否确定這個系統是否也在執行認知降維過程?它是否減少了一些不重要的東西?如果是這樣的話,深度學習是如何做到這一點以及怎樣确定哪些是重要的東西?
是以我們可以想象一個關于深度學習的神話,假設我們已經建立了一個從圖像中找到人臉的系統,并意圖将它作為照相機中的一個功能特性。目前,許多照相機已經具備了這一特性,是以,這也是個常見的例子。我們實作了一個圖像了解神經網絡模型,并花一些時間給該模型展示許多不同類型的圖像,這就是使用監督學習來學習模型,之後就能利用該模型來展示從圖像中識别人臉的這一童話。
如上圖所示,模型首先将輸入圖像從RGB彩色值轉換為輸入數組,然後數組經過許多層的操作處理後,輸出的資料比輸入的資料更少,這也意味着有些資料被處理掉了。每層接收的輸入信号都來自上一層的輸入,每層的輸出傳送給下一層。
在一些底層時,一些操作可能隻是得到一些相鄰的像素并确定方向,提取到一些邊角資訊。随着層數的加深,可以提取到更加抽象具體的資訊,最終得到能夠确定為一張人臉的特征資訊。
<b>丢棄所有非</b><b>人</b><b>臉特征資訊後,剩下的就是臉。</b><b></b>
人為的丢棄某些資訊是不可取的,因為無法判斷這些丢棄掉的資訊是否有用,直到可以确定抽象級别的資訊時,才可以進行操作。同理,以一個公園遊玩照片為例,模型的一些底層操作不能丢棄草坪的資訊,因為它們沒有關于草坪或地面的顯著線索,而更高層能夠得到更加抽象具體的資訊,是以能夠丢棄一些無用的資訊。每一層從前一層接收“低級描述”,并丢棄它認為不相幹的資訊,并向下一層傳送更抽象的資訊,直到最終找到人臉。這也是為什麼深度學習模型一般層次會比較深的原因。
深度學習這一想法本身并不新穎,早在1959年就被讨論過。當時受限于算法、硬體水準及資料量的限制,沒有得到很好的發展。近60年,随着硬體水準的不斷提升,資料量的爆炸式增長,深度學習再一次煥發出勃勃生機,并展現出優異的性能。
下面講解池化層操作,如下圖所示。在TensorFlow中,有50多種池化操作,下圖顯示的2x2最大值池化操作,左圖到右圖需要執行四次池化操作。

2x2最大值池化操作就是從2x2矩形框中挑選出其中的最大值,并将其作為輸出。輸入層四個相鄰的像素值可能表示RGB通道中的亮度,是以數值更大的值能夠更能代表其亮度資訊。在2x2最大值池化操作中,舍去了75%的輸入資料,隻儲存并傳播其中的最大值。
就像素值而言,它可能意味着最亮的顔色值,但就草葉而言,這可能意味着“這裡至少有一片草葉”。每層提取特征,并丢棄一些特征,這也意味着進行着降維操作。
可以清楚地看到,深層神經網絡中最重要的思想之一就是:必須在多個抽象層上進行降維。隻有在适當的層才能決定哪些資訊可能是相關的,哪些資訊可能是需要丢棄的。這也是一種簡化過程,隻有在學習中取得好的結果時,才會以這種方式作出決定。
下面講解卷積過程,根據TensorFlow手冊:
“請注意,雖然這些操作被稱為卷積,嚴格上來講,應該被稱作‘互相關’”。
卷積層發現各種類型的交叉相關與共生性,圖像内部存在空間關系,就像Geoff Hinton最近舉的例子一樣,通常在鼻子下面發現嘴巴。更明顯的是,在有監督學習情況中,模式與可用元資訊(标簽)之間存在關聯。
網絡模型中的更高層次的資訊描述了這些相關性,不相關資訊被視為非顯著資訊而被丢棄。從之前的模型圖中可以看到,卷積層與ReLU激活函數層後接着最大值池化層。其中ReLU是一種新型激活函數,能夠舍去負值,該非線性函數對深度學習而言是非常重要的,相較于傳統的Sigmoid等激活函數而言,ReLU激活函數表現更加優異。
由卷積層-ReLU層-池化層這三層組成的這種模式是相當流行且實用的,這是由于這種組合方式執行了一個可靠的降維過程,絕大多數的卷積神經網絡模型都參考這種結構模式來模組化。随着模型的加深,特征逐漸被減少,直到最終得到能夠完成相關任務的正确特征。
這也是為什麼深度學習模型是深層的原因,因為如果你明白在不同抽象層中哪些是相關和不相幹資訊,那麼你隻能通過丢棄無關的資訊來降維。
<b>深度學習是科學的嗎?</b><b></b>
盡管深度學習過程可以用數學符号描述(大多數是采用線性代數的形式),但這個過程本身是不科學的。深度學習就像一個黑匣子,我們無法了解這個系統是如何了解處理特征并完成相關任務的。
就拿卷積操作舉例,正如TensorFlow手冊中所說,卷積層發現相關性。許多草葉通常代表一個草坪,在TensorFlow中,系統會花費大量時間來發現這些相關性。一旦發現了某些相關性,這種關聯會導緻模型中某些權重的調整,進而使得特征提取正确。但從本質上來說,所有的相關性開始時對于模型來說都被遺忘了,必須在每次前向傳播和梯度下降的過程中來重新發現。這種系統實際上是從錯誤中吸取教訓,即模型輸出與理想輸出之間的誤差。
前向和反向傳播過程對圖像了解有一定的意義,有些人在文本上使用了相同的算法。幸運的是,針對于文本任務而言,有更加高效的算法。首先,我們可以使用大腦突觸或程式設計語言中的正常指針或對象引用顯式地表示所發現的相關性,神經元與神經元之間有關聯。
無論是深度學習算法,還是有機學習,都不是科學的。它們在缺乏證據并信任相關性的前提下得出結論,而不堅持可證明的因果關系。大多數深層神經網絡程式設計很難得到理想結果并存在一定的誤差,隻能通過從實驗結果中發現線索來改進模型。增加網絡層數不總是有效的,對于大多數深度神經網絡從業者而言,根據實驗結果來調整改進網絡就是他們的日常工作。沒有先驗模型,就沒有先驗估計。任何深層神經網絡可靠性和正确性的最佳估計,都是經過大量的實驗得到。
為什麼我們會使用不能保證得到正确答案的工程系統呢?因為我們别無選擇,使用整體方法當作可靠的降維方法是不可用的。與此類似,當任務需要有能力自主地執行上下文切片簡化時,模型需要具有了解能力。
我們沒有别的辦法來處理這些不靠譜的機器嗎?當然可以,因為地球上有幾十億的人類已經掌握了處理這項複雜任務的技能,是以你可以取代表現良好但理論上未經證明的玩意兒——一個通過深層神經網絡建立的機器。比比你和機器誰每小時能掙更多的錢?這看起來不太像是科技的進步,這類機器不能被證明是正确的,因為它不能像普通計算機那樣運作。
我最喜歡的一句話是由McCarthy和Hayes所斷言的,“你看到了它,你将再次看到它”,深度學習是人工智能認識論其中一部分内容,盡管目前大多數智能是不科學的,但在幾年後,我們将對智能定義達成一緻意見,最終實作智能化的世界。
<b>作者資訊</b><b></b>
Monica Anderson,Syntience公司研究總監。
個人首頁:https://www.linkedin.com/in/syntience/
文章原标題《Why Deep Learning Works》,作者:Monica Anderson,譯者:海棠,審閱:袁虎。